2023
06-11
06-11
Biopython教程之“多序列比对”
 多序列比对(Multiple Sequence Alignment, MSA),对多个序列进行对位排列。这通常需要保证序列间的等同位点处在同一列上,并通过引进小横线(-)以保证最终的序列具有相同的长度。在生物信息分析中,我们有时需要进行多序列比对,Biopython可以帮我们实现,特别是使用linux系统的同学,biopython值得拥有。两种读取方法Biopython提供了两种方法读取多序...... 阅 读 全 部 >
多序列比对(Multiple Sequence Alignment, MSA),对多个序列进行对位排列。这通常需要保证序列间的等同位点处在同一列上,并通过引进小横线(-)以保证最终的序列具有相同的长度。在生物信息分析中,我们有时需要进行多序列比对,Biopython可以帮我们实现,特别是使用linux系统的同学,biopython值得拥有。两种读取方法Biopython提供了两种方法读取多序...... 阅 读 全 部 >
 众所周知,python在数据分析领域十分常用,而作为数据科学的一个分支,生物信息学也是对python偏爱有加。今天我们就来看看一个功能强大的python生信分析包——Biopython。什么?还不知道?知道又不会用?又out啦各位,现在跟着小编来一步步实现一些很实用的python分析工具吧。征服星辰实现目标预备工作学点语言 装好pyhton当然作为入门,python语言基础还是...阅读全文>...
众所周知,python在数据分析领域十分常用,而作为数据科学的一个分支,生物信息学也是对python偏爱有加。今天我们就来看看一个功能强大的python生信分析包——Biopython。什么?还不知道?知道又不会用?又out啦各位,现在跟着小编来一步步实现一些很实用的python分析工具吧。征服星辰实现目标预备工作学点语言 装好pyhton当然作为入门,python语言基础还是...阅读全文>...  撰写:生信大师兄 来源:小张聊科研平台的“ i生信”公众号,微信公众号搜索“ i生信”即可关注/扫描关注见文末#生信发文# #科研热点# #单基因#今天我们分享一篇文章,看单个基因的研究发到5分以上的期刊,需要做哪些工作。文章是2023年1月发表在Comput Biol Med期刊上的研究:Identification and analysis of C17...阅读全文>>...
撰写:生信大师兄 来源:小张聊科研平台的“ i生信”公众号,微信公众号搜索“ i生信”即可关注/扫描关注见文末#生信发文# #科研热点# #单基因#今天我们分享一篇文章,看单个基因的研究发到5分以上的期刊,需要做哪些工作。文章是2023年1月发表在Comput Biol Med期刊上的研究:Identification and analysis of C17...阅读全文>>...  天跟大家分享的是2020年4月发表在Mol. Carcinog.(IF:3.411)杂志上的一篇文章Alternative splicing related genetic variants contribute to bladder cancer risk.在文章中作者作者通过CancerSplicingQTL数据库搜索了位于膀胱癌的sQTL中的SNPs。进行了一项包括580例病例和1,...阅...
天跟大家分享的是2020年4月发表在Mol. Carcinog.(IF:3.411)杂志上的一篇文章Alternative splicing related genetic variants contribute to bladder cancer risk.在文章中作者作者通过CancerSplicingQTL数据库搜索了位于膀胱癌的sQTL中的SNPs。进行了一项包括580例病例和1,...阅... 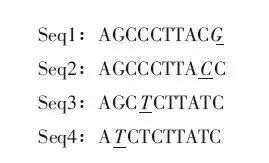 在周一(4月2日)的《浅谈选择压力分析》一文周老师向大家介绍了选择压力分析的由来和用途,下面就可看下如何进行选择压力分析。按照群体数量,选择压力分析的方法主要可分成两类:DNA多样性的计算(单个群体内分析)和多样性水平在不同亚群间的比较(多群体分析)。第一类方法DNA多样性的计算(单个群体内分析)。在动植物重测序领域,选择压力分析的方法大多数是在同一个物种内,进行多样性统计和比较。最基础...阅读...
在周一(4月2日)的《浅谈选择压力分析》一文周老师向大家介绍了选择压力分析的由来和用途,下面就可看下如何进行选择压力分析。按照群体数量,选择压力分析的方法主要可分成两类:DNA多样性的计算(单个群体内分析)和多样性水平在不同亚群间的比较(多群体分析)。第一类方法DNA多样性的计算(单个群体内分析)。在动植物重测序领域,选择压力分析的方法大多数是在同一个物种内,进行多样性统计和比较。最基础...阅读...  作者:华大时空来自美国加州大学的冯根生团队,利用scRNA-seq绘制了从新生儿到成年的单细胞分辨率小鼠肝脏发育图谱,证明了肝细胞与内皮细胞、星状细胞和Kupffer细胞协同作用的功能成熟,以及巨噬细胞群的短暂出现。这项研究提供了一个全面的图谱,涵盖了所有的肝细胞类型,并有助于进一步剖析肝脏发育、代谢和疾病。该文章在2022年2月7日发表在Developmental Cell,...阅读全文>...
作者:华大时空来自美国加州大学的冯根生团队,利用scRNA-seq绘制了从新生儿到成年的单细胞分辨率小鼠肝脏发育图谱,证明了肝细胞与内皮细胞、星状细胞和Kupffer细胞协同作用的功能成熟,以及巨噬细胞群的短暂出现。这项研究提供了一个全面的图谱,涵盖了所有的肝细胞类型,并有助于进一步剖析肝脏发育、代谢和疾病。该文章在2022年2月7日发表在Developmental Cell,...阅读全文>...  大家好,又和大家见面了,之前我们医学方推出了两篇帖子关于基因ID的转化,分别是借助biomaRt和clusterprofiler包,来帮助大家实现同一物种ID的转化,当然这里的物种一般指的是人类,ID呢,通常是三类:entrez gene ID, HUGO symbol, ensembl ID,关于各类ID的介绍之前的帖子里面也有介绍,这里我就不在累赘了。今天呢,我的主题是不同物种之间ID...阅...
大家好,又和大家见面了,之前我们医学方推出了两篇帖子关于基因ID的转化,分别是借助biomaRt和clusterprofiler包,来帮助大家实现同一物种ID的转化,当然这里的物种一般指的是人类,ID呢,通常是三类:entrez gene ID, HUGO symbol, ensembl ID,关于各类ID的介绍之前的帖子里面也有介绍,这里我就不在累赘了。今天呢,我的主题是不同物种之间ID...阅...  “葡萄美酒夜光杯,欲饮琵琶马上催。”葡萄自古以来就是非常重要的水果,无论是直接食用、酿酒还是制成葡萄干,都深受世界各地人们的喜爱,同时葡萄(包括晶莹剔透的葡萄美酒)也经常成为文学家、艺术家笔下描绘的对象。时至今日,人们对葡萄的青睐有增无减,于是培育出更加美味的葡萄也就成了当务之急。对于那些重要的果实性状,若能将它们在基因组上进行定位,育种工作将会事半功倍。对于自然群体的性状定位而言,GWAS(Ge...
“葡萄美酒夜光杯,欲饮琵琶马上催。”葡萄自古以来就是非常重要的水果,无论是直接食用、酿酒还是制成葡萄干,都深受世界各地人们的喜爱,同时葡萄(包括晶莹剔透的葡萄美酒)也经常成为文学家、艺术家笔下描绘的对象。时至今日,人们对葡萄的青睐有增无减,于是培育出更加美味的葡萄也就成了当务之急。对于那些重要的果实性状,若能将它们在基因组上进行定位,育种工作将会事半功倍。对于自然群体的性状定位而言,GWAS(Ge...  森言森语下午开完组会,吃过晚饭终于得空干点别的,于是决定将之前写过的这篇关于基因家族分析的推文再检查完善一下。检查日志2021年9月30日:黄底红字为更新内容,其他色彩为原文。最近的一段时间是倦怠的,虽然忙,却实际上浑浑噩噩,没有长进。不管怎么样,一个阶段的结束,总要写点东西来宣告它的结束,然后迎接新的开始。已经很久没有跑步了,原本计划今年参加6月份的兰州马拉松...阅读全文>>...
森言森语下午开完组会,吃过晚饭终于得空干点别的,于是决定将之前写过的这篇关于基因家族分析的推文再检查完善一下。检查日志2021年9月30日:黄底红字为更新内容,其他色彩为原文。最近的一段时间是倦怠的,虽然忙,却实际上浑浑噩噩,没有长进。不管怎么样,一个阶段的结束,总要写点东西来宣告它的结束,然后迎接新的开始。已经很久没有跑步了,原本计划今年参加6月份的兰州马拉松...阅读全文>>...  常见的建树方法有:贝叶斯法(Bayesian),最大似然法(Maximum likelihood,ML),最大简约法(Maximum parsimony,MP),邻接法(Neighbor-Joining,NJ),最小进化法(Minimum Evolution,ME),类平均法(UPGMA)。一般来讲,如果模型合适,最大似然法的效果较好。对于近缘序列,最大简约法用的假设最少,各种方法结果...阅读全...
常见的建树方法有:贝叶斯法(Bayesian),最大似然法(Maximum likelihood,ML),最大简约法(Maximum parsimony,MP),邻接法(Neighbor-Joining,NJ),最小进化法(Minimum Evolution,ME),类平均法(UPGMA)。一般来讲,如果模型合适,最大似然法的效果较好。对于近缘序列,最大简约法用的假设最少,各种方法结果...阅读全... 