上周的干货软文为您介绍了如何在Ensembl数据库查找目标基因序列(Ensembl篇),这周我们将进入NCBI篇,为您讲解如何在该数据库查找目标基因序列。
搜索已被RefSeq收录的基因序列
NCBI,是美国国立生物技术信息中心(National Center for Biotechnology Information)的英文缩写。与专攻基因组检索的Ensembl不同,NCBI数据库的内容更加庞杂和全面,它可提供36种数据检索与分析工具,这其中就包含大家都非常熟悉的文献数据库PubMed。而我们利用NCBI查找目标序列,主要是基于它的RefSeq、即参考序列数据库(reference sequence database)来实现的。概括地说,就是利用相对易获取、或已知的信息,如基因名或基因ID,关联到与之对应的RefSeq序列接收号,从而get目标序列信息。具体操作步骤如下:
01、进入NCBI网站:
进入https://www.ncbi.nlm.nih.gov/,在左侧下拉菜单选择“gene”
02、搜索基因:
可输入基因ID(NCBI Gene ID即GI号)或基因名进行查找。这里以小鼠的隐花色素基因举例,我们直接输入cryptochrome进行搜索,结果如下:
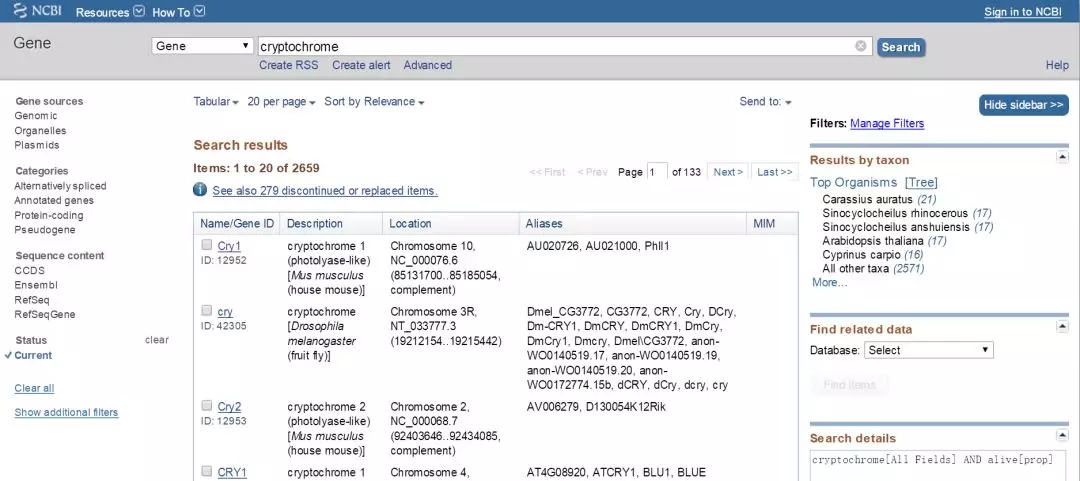
03、找到目标基因:
小鼠Cry1,即第一个结果,点击查看:
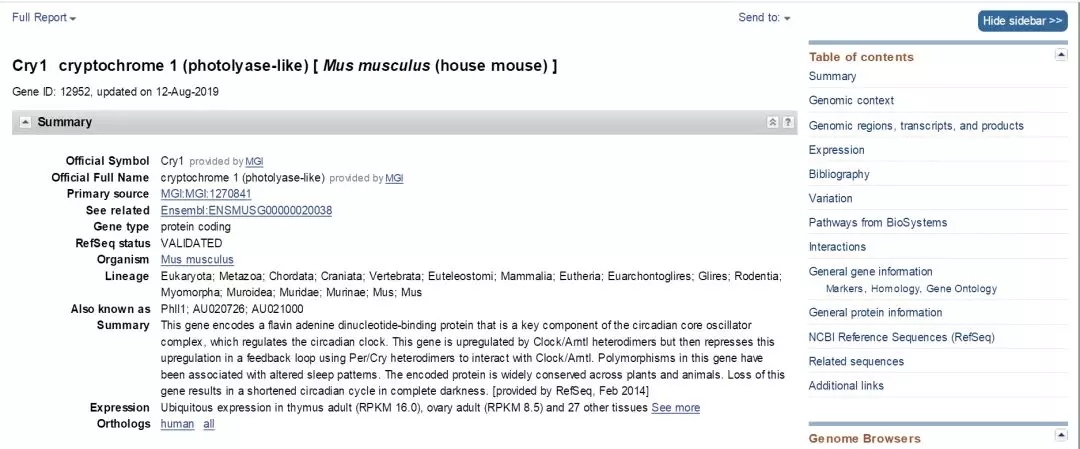
该页面会展示该基因具体信息,如上图展示的NCBI Gene ID、更新时间、官方名称、物种、及在其他数据库的链接。我们继续向下拖动页面,找到“NCBI Reference Sequences (RefSeq)”,点击代表mRNA记录的序列接收号,该编号通常以NM开头(图中红框)
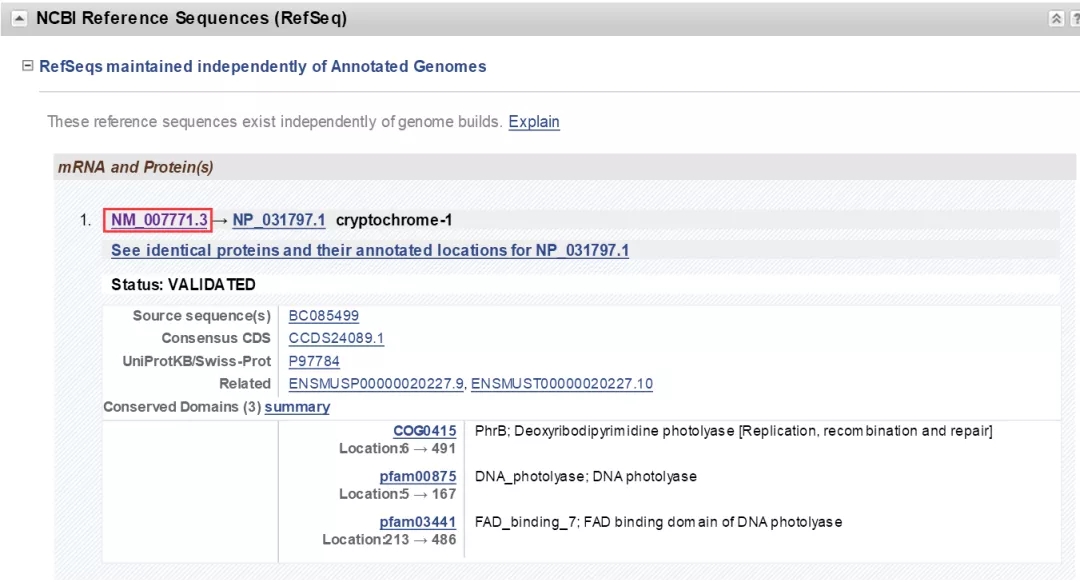
04、页面跳转至核苷酸数据库,如下图:

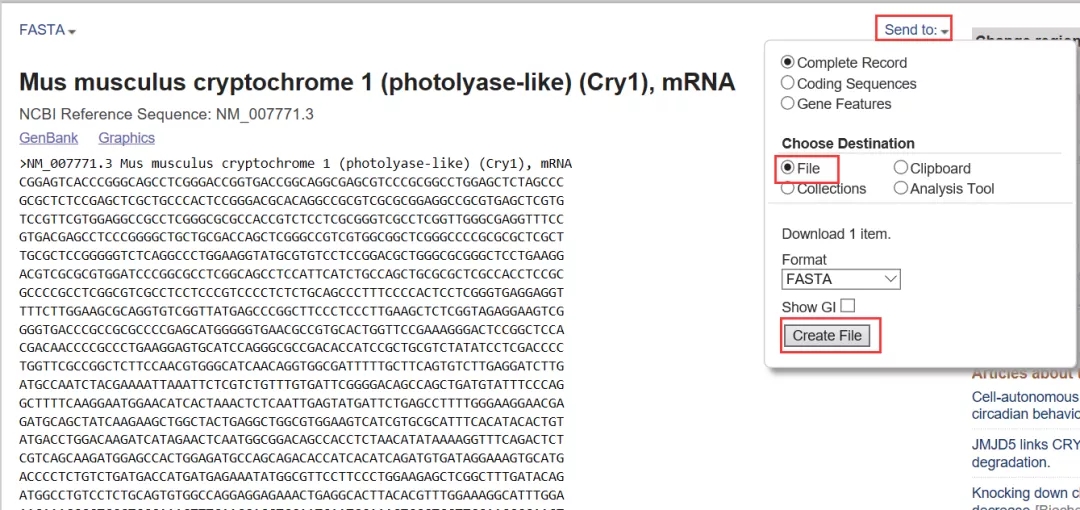
从图中信息可知该基因来自小鼠NM_007771染色体,长度为3035bp,点击“FASTA”可快速查找和下载全基因序列。如下图,在页面右侧,点击“Send to”选项,然后选择“File”,点击“Creat File”按钮。
05、点击“GenBank”切换页面:
该页面除了提供基因序列外,还包含注释信息。我们下拉页面至完整序列信息:
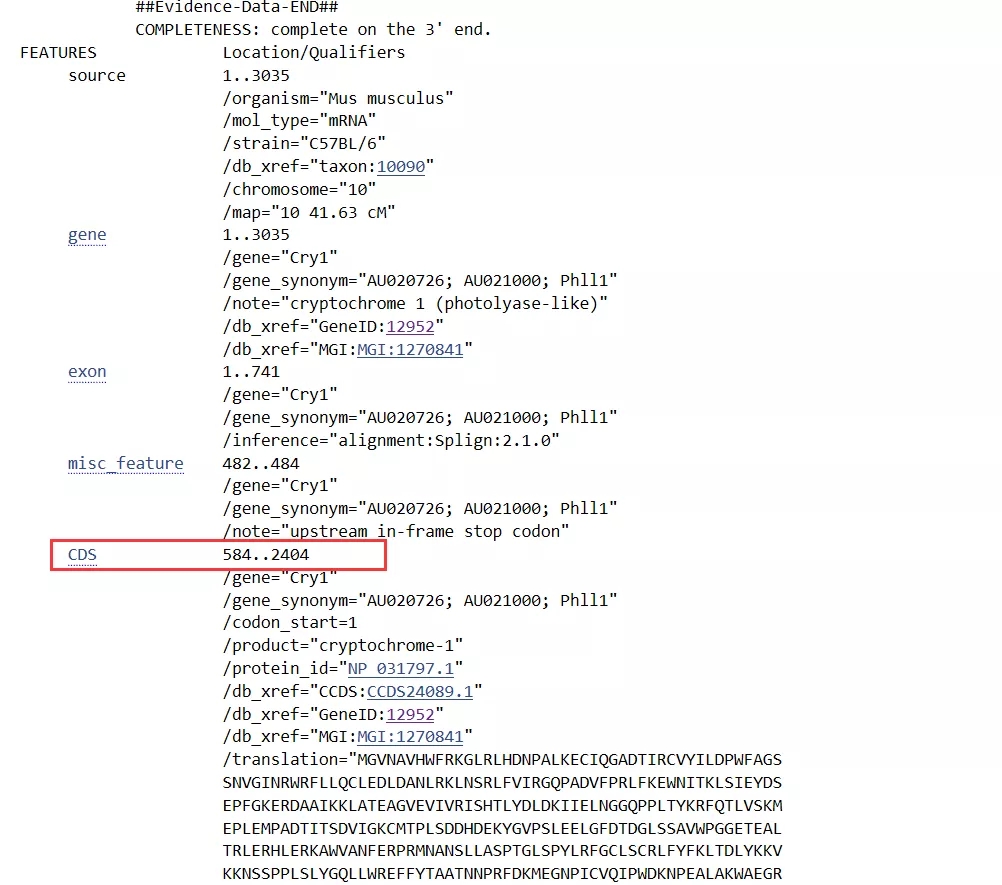
从图中信息可知,编码区序列位于该基因的第584-2404号核苷酸,可结合已下载的全基因序列进行查看。
搜索未被RefSeq收录的基因序列
看到这里,相信有不少小伙伴已经摩拳擦掌,跃跃欲试了,然而在实际操作过程中,我们有时却会遇到这样的情况:用来进行转录组测序分析的参考基因组千真万确就是来自NCBI数据库,然而利用刚学会的方法,在NCBI-gene菜单里搜索相应的基因名却一无所获,这又是为什么呢?
为了回答这个问题,我们需要认识另一个NCBI数据库:GenBank,它是一个DNA序列数据库,收集了所有公开的DNA序列以及与之相关的生物学信息和参考文献,其最主要的信息来源就是作者的直接投递。同属于序列数据库,GenBank与上文提到的RefSeq存在一些区别,主要在于:GenBank是一个开放的数据库,很多研究者或者公司都可以自己提交序列;而RefSeq是经过NCBI筛选的非冗余数据库,可信度更高。
因此,当一段序列仅被GenBank收录,而未被RefSeq收录时,我们自然无法通过上文介绍的通过基因名跳转至相应RefSeq序列接收号的方式来进行查找了。解决办法其实很简单:直接下载全基因组序列,然后搜索基因名即可。具体操作如下:
01、找到参考基因组的编号:
根据有参转录组的结题报告,找到参考基因组的编号,如下图:

02、进入NCBI网站:
进入https://www.ncbi.nlm.nih.gov/,在左侧下拉菜单选择“Assembly”,输入刚才找到的基因组编号:

03、搜索及下载:
点击搜索,进入该基因组的组装信息界面,可见该基因组仅被录入GenBank而未被RefSeq收录(蓝框),因此我们选择下载基因组。点击右侧“Download the GenBank assembly”(图中红框):
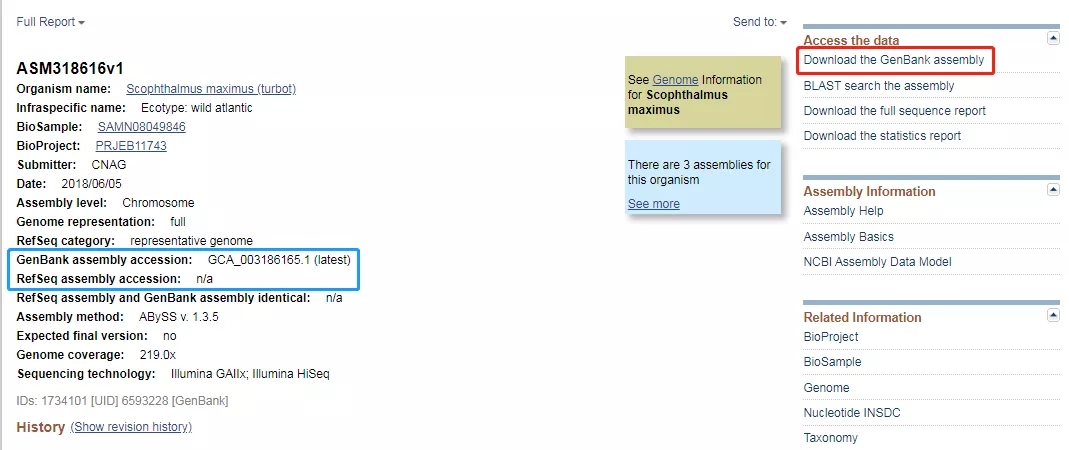
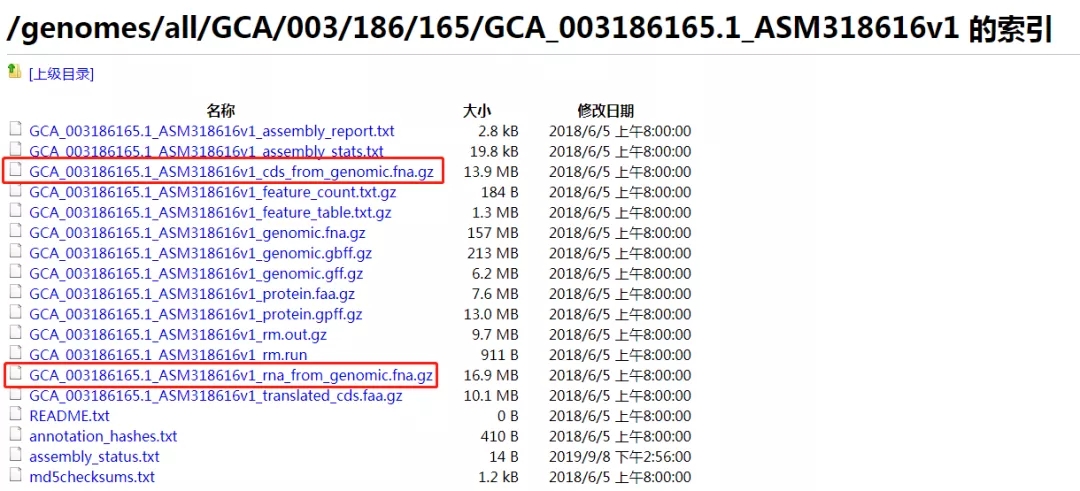
04、进入下载页面:
可选择下载CDS序列,或RNA序列(红框),这里我们选择下载CDS序列:
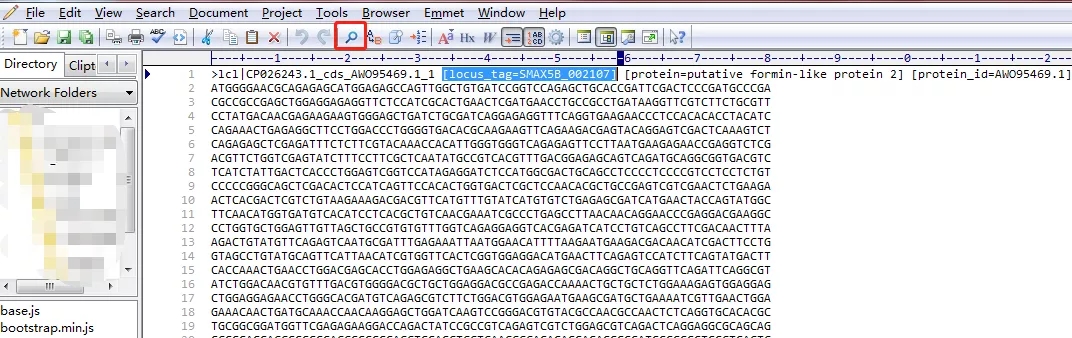
05、解压文件,查找目标基因:
下载完毕,解压后得到一个FASTA格式的序列文件。我们用EditPlus软件打开它,如下图。“locus_tag”即为该基因登记于GenBank的基因名。点击查找工具(图中红框)搜索目标基因名,即可获得相应CDS序列:
总结
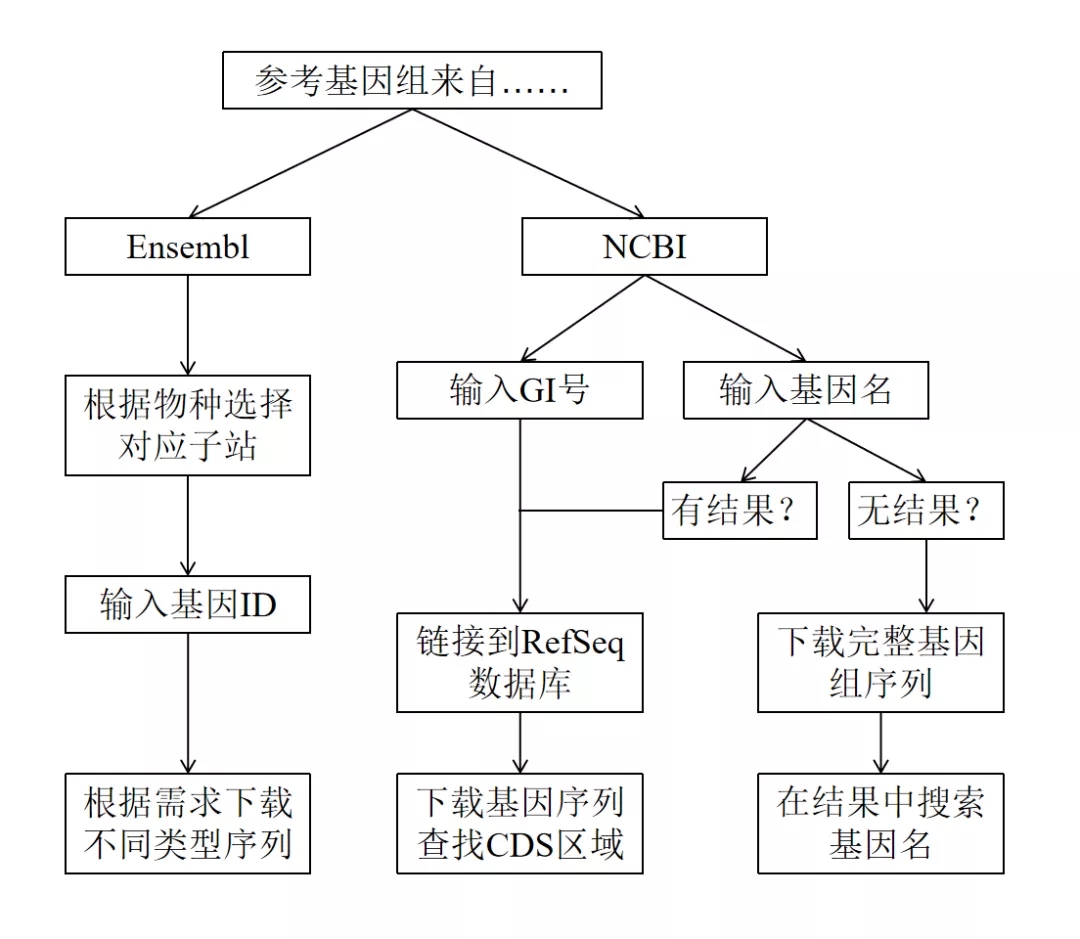
看到这里,聪明的您应该已经察觉到了,查找目标基因序列的方法概括起来其实只有三步:确定数据库、输入基因信息、下载特定序列。这似乎与“如何将一只大象关进冰箱?”有异曲同工之妙:我们需要先选择一个合适的“冰箱”,是Ensembl还是NCBI?是Ensembl的脊椎动物、植物还是真菌库?是NCBI的RefSeq还是GenBank?此外,“塞大象的手法”也至关重要,尤其是在NCBI这个“冰箱”里,我们是搜GI号还是基因名?如果搜不到,我们该怎么把这只不愿意进入冰箱的大象“忽悠”进去?在成功地“把冰箱门关上”之后,我们又得到了什么?是全基因的序列,还是CDS序列?
最后,让我们再来回顾一下这张流程图,现在的您应该已经对此心中有数了。只要掌握了这些步骤,相信您一定能轻松而又准确地查找到目标序列。
- 本文固定链接: https://maimengkong.com/kyjc/734.html
- 转载请注明: : 萌小白 2021年7月31日 于 卖萌控的博客 发表
- 百度已收录
