转录组作为研究分子机制最常用的科研手段,几乎每个科研工作者都会与它有那么一两段缘分,今天就带大家一起来通过图说的形式,了解下转录组结果中的重点分析内容,闲话不多说,上干货!
图说一、 生物学重复平行性检验-相关性分析热图+PCA图
转录组测序目前普遍要求进行检测的每个组别,是少需要三个生物学重复,以保证结果的科学性。生物学重复的平行性越好,重复作为一个组呈现时,分析的结果越可靠,因此,在进行组别之间的差异分析时,先进行生物学重复的平行性检验尤为重要。一般可以通过样本的相关性分析和PCA分析结果来查看样本间的相似性。
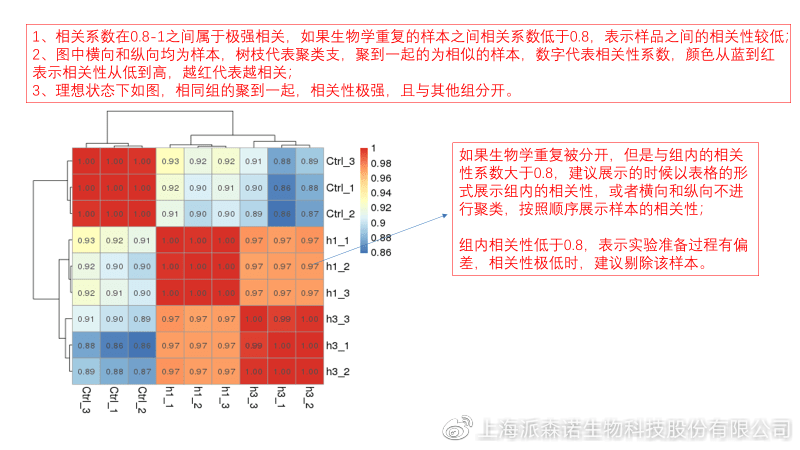
1、 样本相关性分析
用皮尔逊相关系数表示样品间基因的表达水平相关性,相关系数越接近1,表明样品间表达模式越相似。组内重复间的相关性较低时,表明有离群样本,可根据需要剔除离群样本;
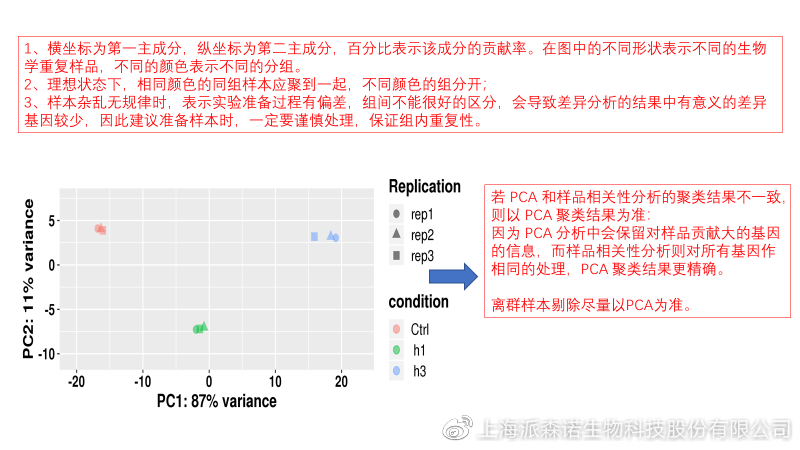
2、 PCA主成分分析
通过线性变换,降维分析以降低数据复杂度。PCA分析把相似的样本聚到一起,距离越近表明样本间相似性越高。有离群样本出现时,该样本会偏离组群,可根据需要剔除离群样本;
TIPS
建议尽量增加生物学重复的个数,保证剔除离群样本后,每组仍有至少3个重复。
图说二、表达差异分析-火山图和MA图
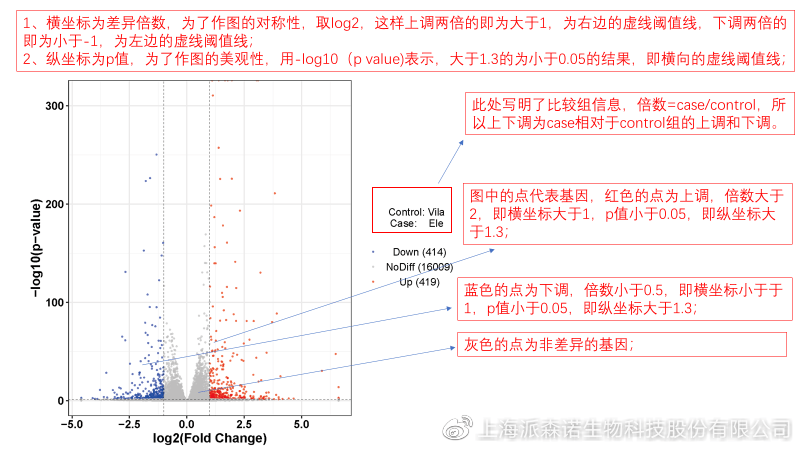
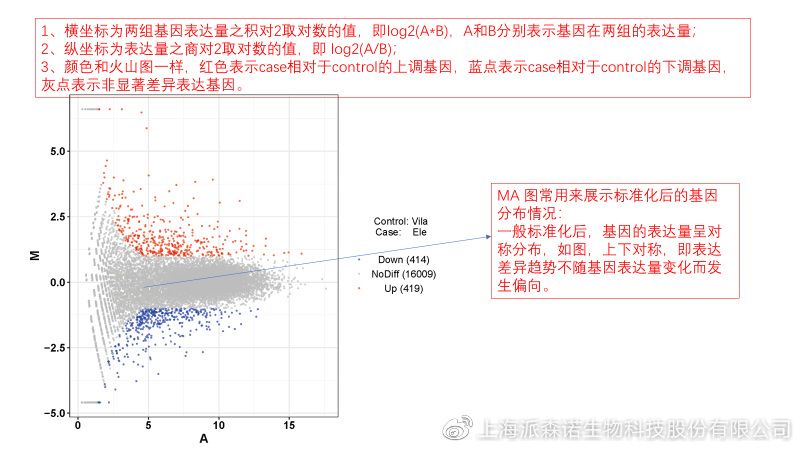
转录组主要目的是寻找不同比较组之间的差异基因,以揭示导致比较组之间不同的分子机制,因此在分析结果中,基因表达差异分析是重中之重。
1、 差异分析一般涉及两个标准,差异倍数foldchange和p值,一般认为上调或者下调在两倍以上,且同时p值小于0.05,才认为该基因在两个比较组间发生了显著的差异变化。按照这一标准筛选出来的差异基因即为转录组找到的显著差异基因集。
2、 当差异基因的个数太多时,可以考虑收缩筛选标准,比如调大差异倍数,调小p值范围,若差异基因个数仍然较多,可以调整为比p值更严格的Padj或者FDR来进行筛选;
3、 当差异基因的个数太少时,可以考虑放宽筛选标准,比如调小差异倍数。
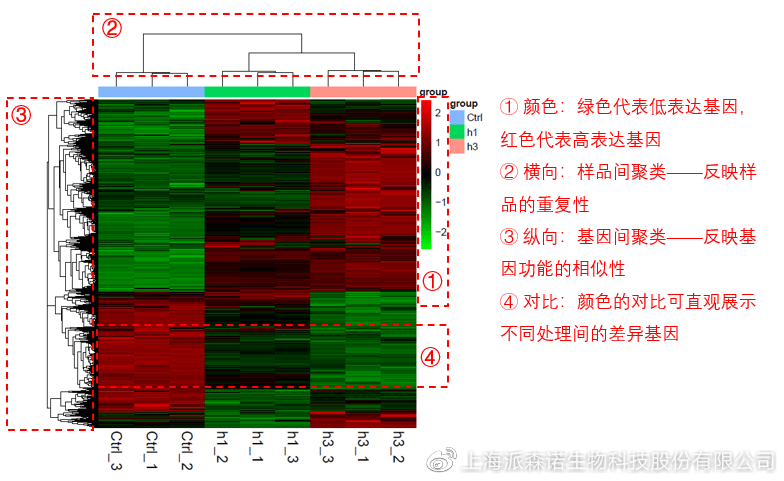
图说三、 双向聚类热图:始于聚类,不止于“聚类”
双向聚类热图,顾名思义也是聚类分析的一种形式。“双向”意指该图的横向、纵向聚类均具有统计学意义:横向为样品间聚类,可视为生物学重复的平行性检验;纵向为基因间聚类,可基于基因表达量将表达模式相似的基因归为一类。
该分析的作图数据为经过中心化和标准化的基因表达量(fpkm),由绿到红的颜色渐变表示基因表达量从低到高的变化。聚类热图一般针对差异基因进行,借由不同处理间的红绿色对比,可直观展示差异基因在组间的上下调表达情况。
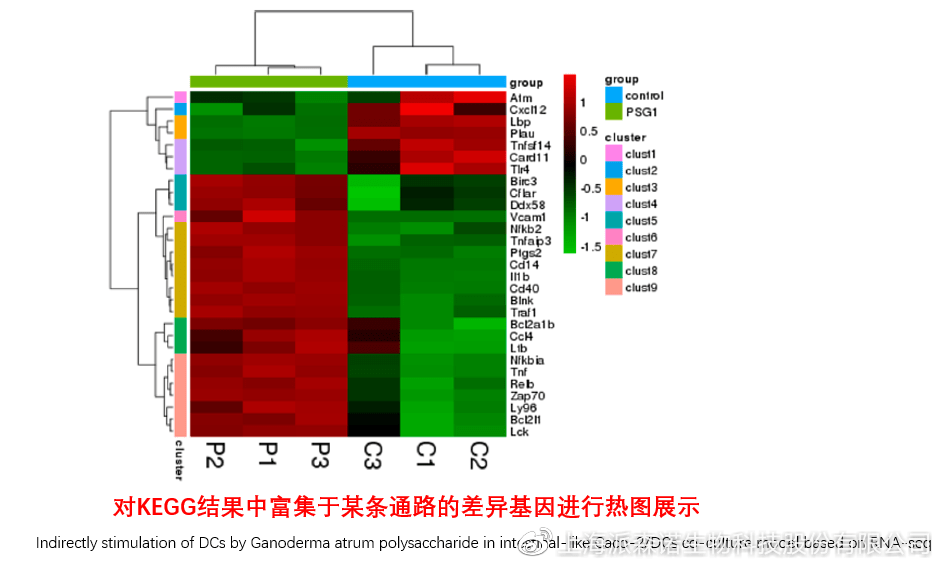
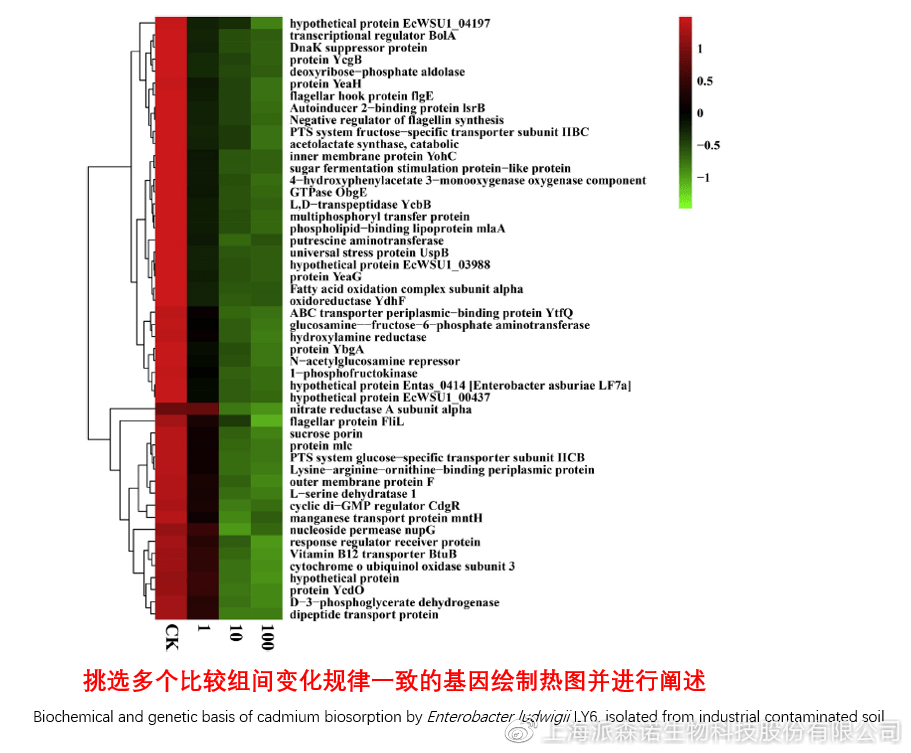
在转录组文章撰写过程中,双向聚类热图一般作为生物学重复的检验结果,功能类似样品相关性分析和PCA分析;但由于其可通过 “撞色”来体现差异,因此热图也可用于对目的基因进行可视化呈现,如图2和图3。因此我们说,聚类热图始于聚类,但它的用途并不止于“聚类”。
图说四、 趋势分析:热图“伴侣”,聚焦关键基因
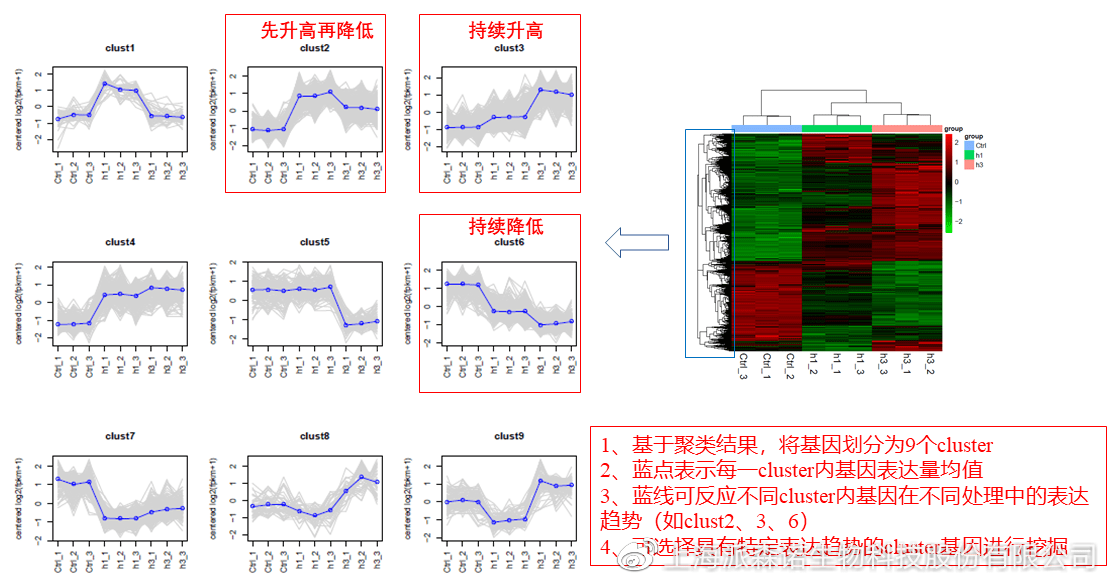
趋势分析,是基于双向聚类热图的分析结果,进一步根据基因表达模式的相似性将其划分成不同的cluster(默认分成9个)。我们认为每一cluster内的基因属于一类,更可能行使相似的功能。
该图的蓝色趋势线能直观地展示不同类型基因在样品间的表达量变化情况,因此可以用于缩小分析范围,聚焦关键基因。如,进行药物疗效的转录组测序分析时,可选择在空白对照-疾病-药物处理三组中呈现先增高后降低、或先降低后增高趋势的cluster,重点关注该cluster内的基因功能,辅以热图展示或功能富集分析,有效地筛出目的基因。
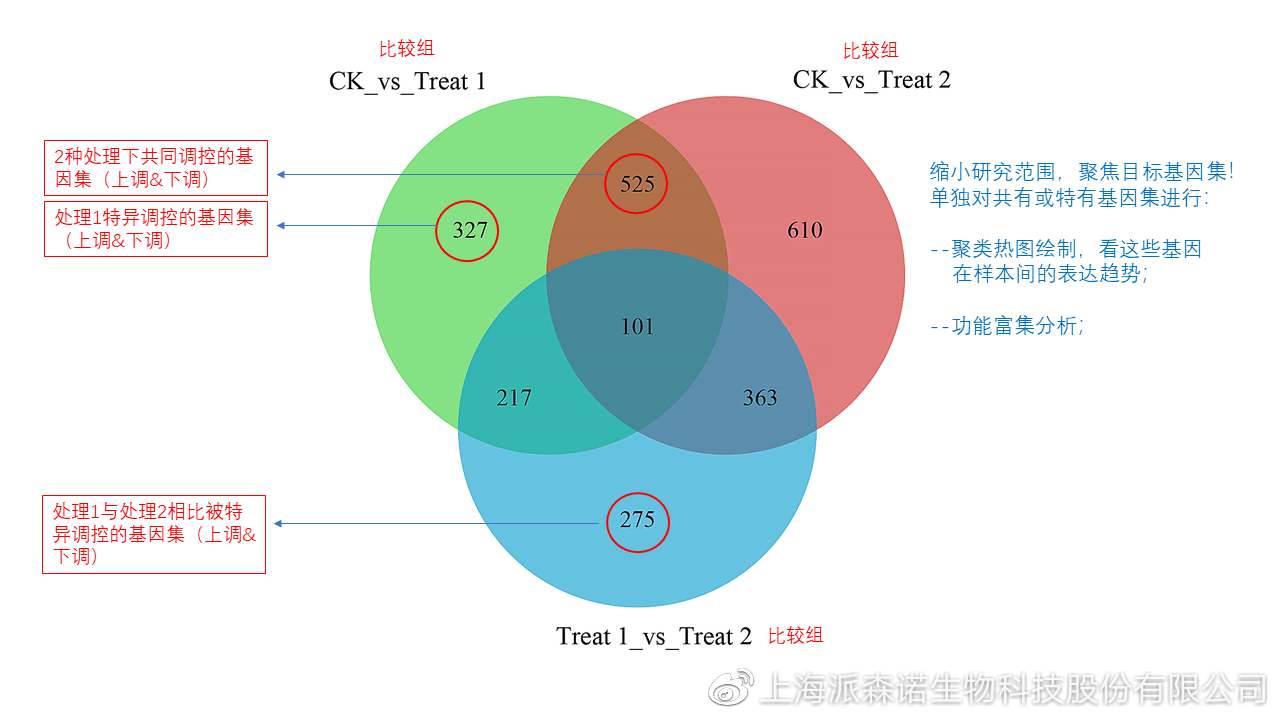
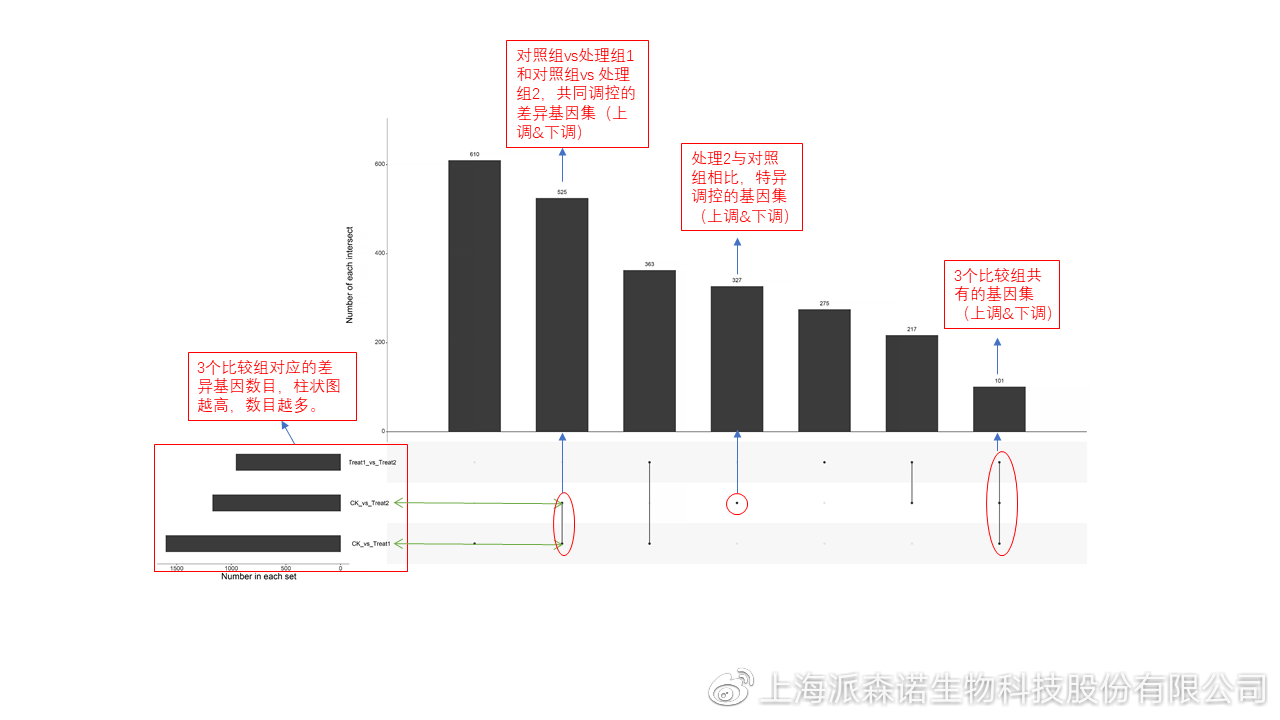
图说五、 多组差异表达分析比较——维恩图和upset图
1秒看懂维恩图,缩小研究范围,聚焦目标基因集 So easy!维恩图和upset图是都基于组与组之间比较得到的差异基因进行的集合,重叠部分即是不同处理下各组样本中被共同调控的基因集,单独的部分则是某种处理下特定调控的基因集,基于维恩图或upset图我们可以分别对共有或特有基因集进行深度挖掘,绘制聚类热图,观察这些基因在样本间的表达趋势;或者进行功能富集分析以及后续的功能验证实验。
1、 维恩图
维恩图只能基于2-5个比较组来做,6个比较组的维恩图非常不美观不建议做。另外,如果小伙伴们关注每组上调或者下调基因单独的相交情况而不是总的差异基因的相交,也可利用在线网站http://jvenn.toulouse.inra.fr/app/example.html 免费做维恩图。
2、 Upset图
可以提供2个比较组及以上的矩阵图,适用于6个比较组以上的情况,可以直观的展示不同比较组间共有和特有的差异基因数。
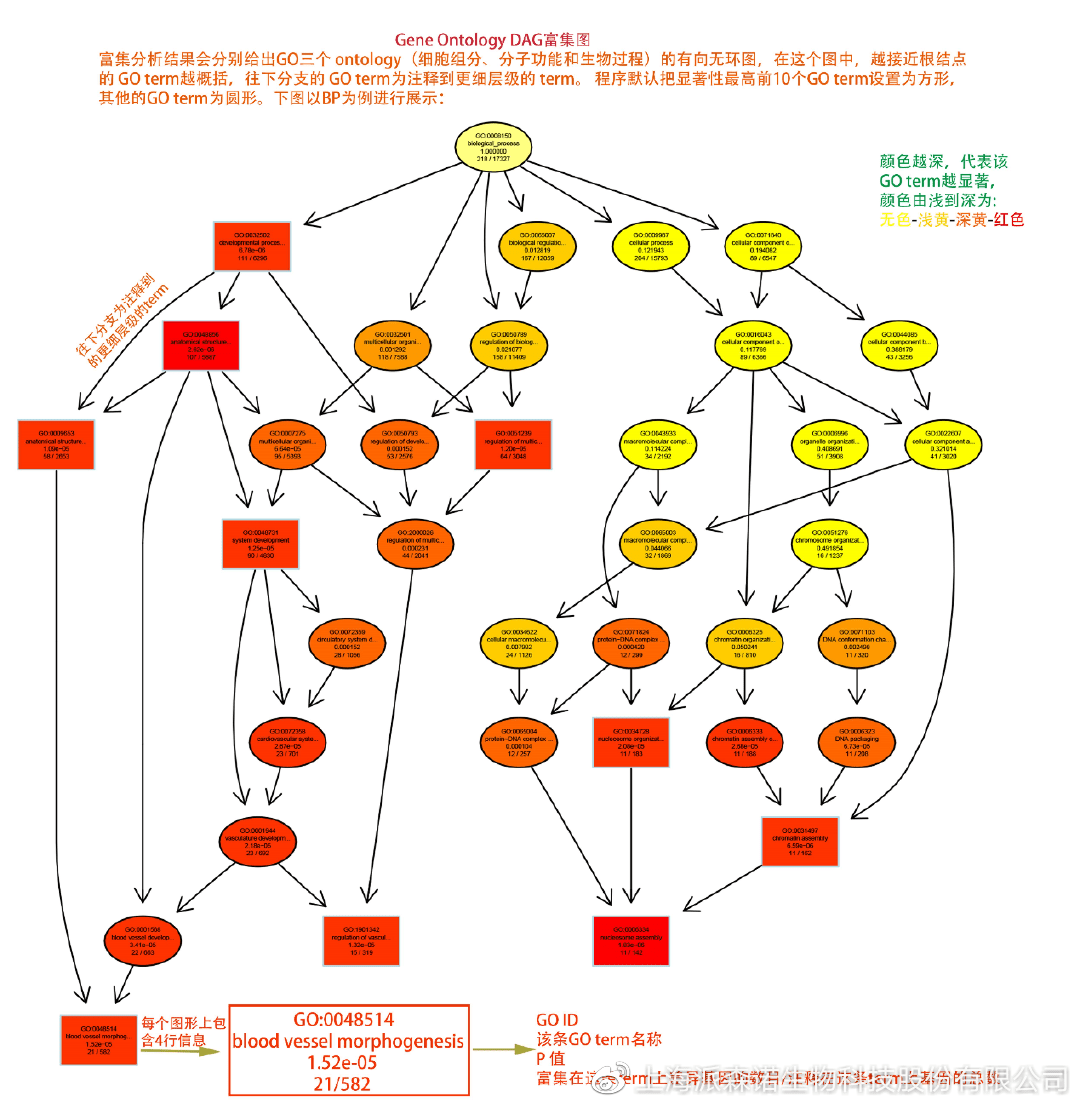
图说六、 差异表达基因功能富集分析——GO富集分析
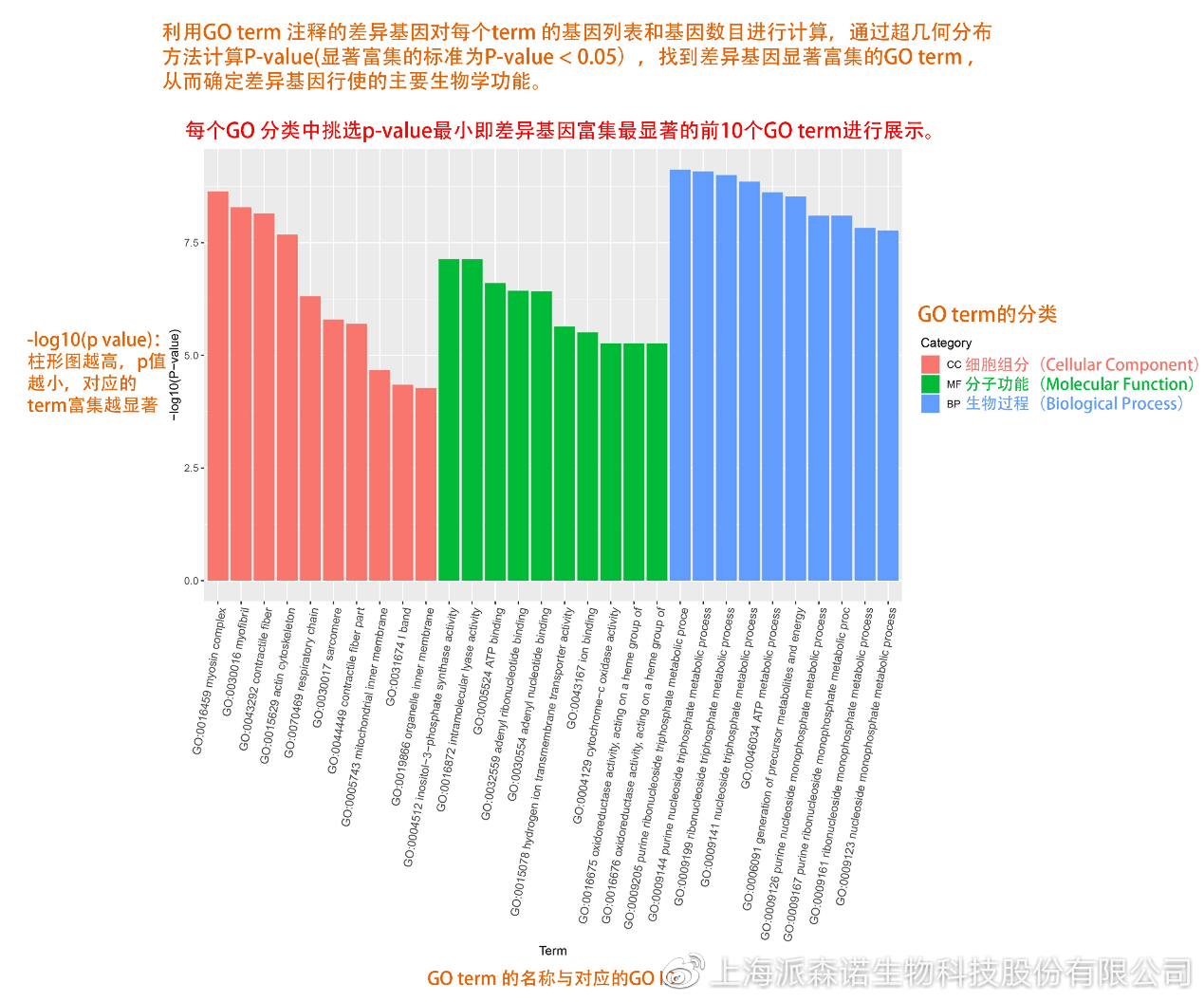
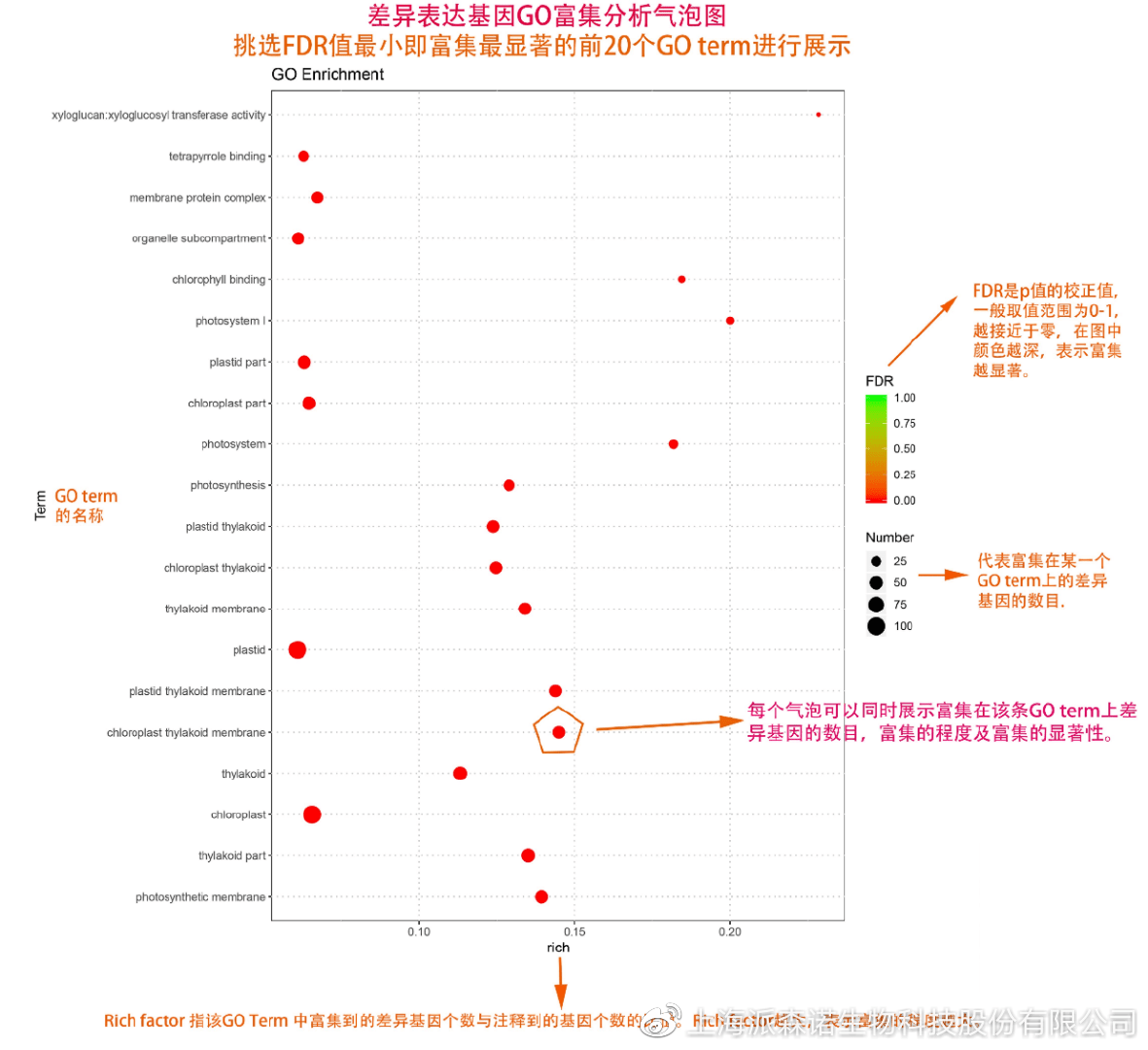
GO(基因本体论联合会建立的数据库http://geneontology.org/,Gene Ontology)是一个国际标准化的基因功能分类体系,提供了一套动态更新的标准词汇表来全面描述生物体中基因和基因产物的属性。GO 涵盖三个方面,分别描述基因的分子功能(Molecular Function)、细胞的组件作用(Cellular Component)、参与的生物学过程(Biological Process)。GO 的基本单元是 Term,每个 Term 有一个唯一的标示符(由 “GO:” 加上7个数字组成,例如 GO:0072669)。
老师们进行数据分析时,可以通过找到对照组vs实验组的差异表达基因显著富集(P<0.05)在哪些GO term,从而确定差异基因行使的主要生物学功能;或通过查找关注的GO term,获得该条term上与对照组相比处理组中有哪些基因的表达有显著差异。
在转录组分析中,我们绘制了柱形图、气泡图和有向无环图,用于更好的展示差异基因GO富集分析的结果:
图说七、 差异表达基因功能富集分析——KEGG富集分析
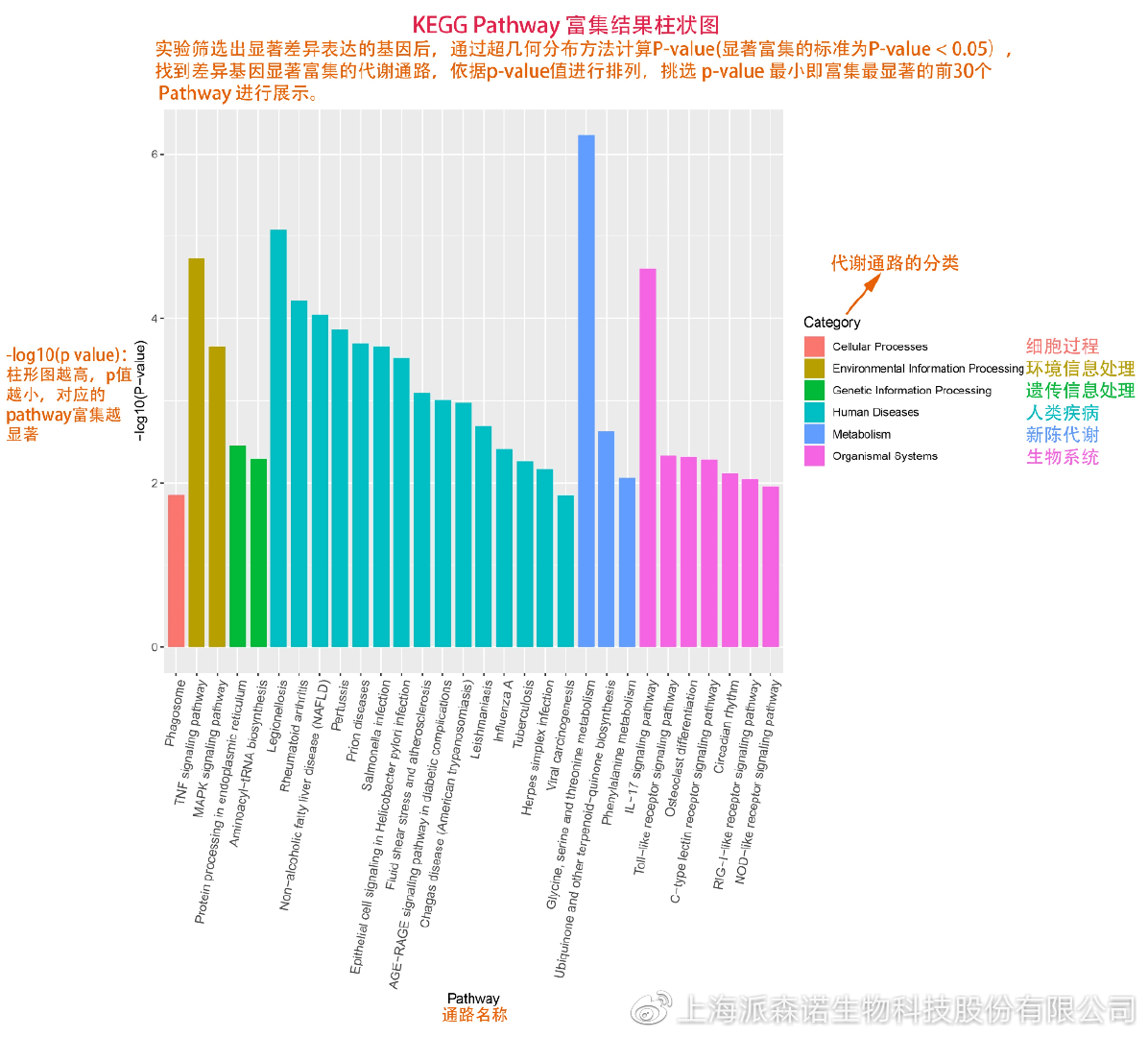
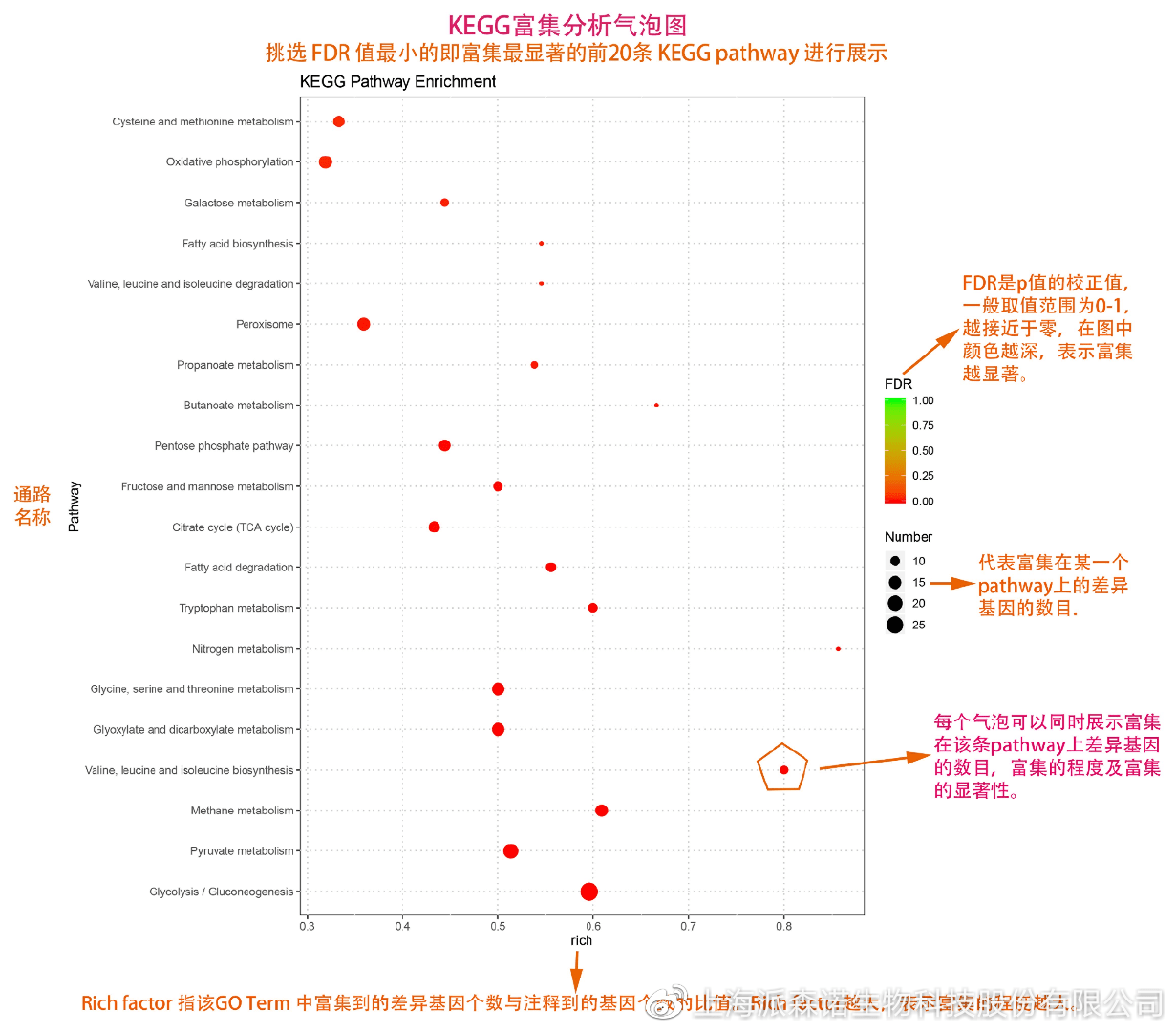
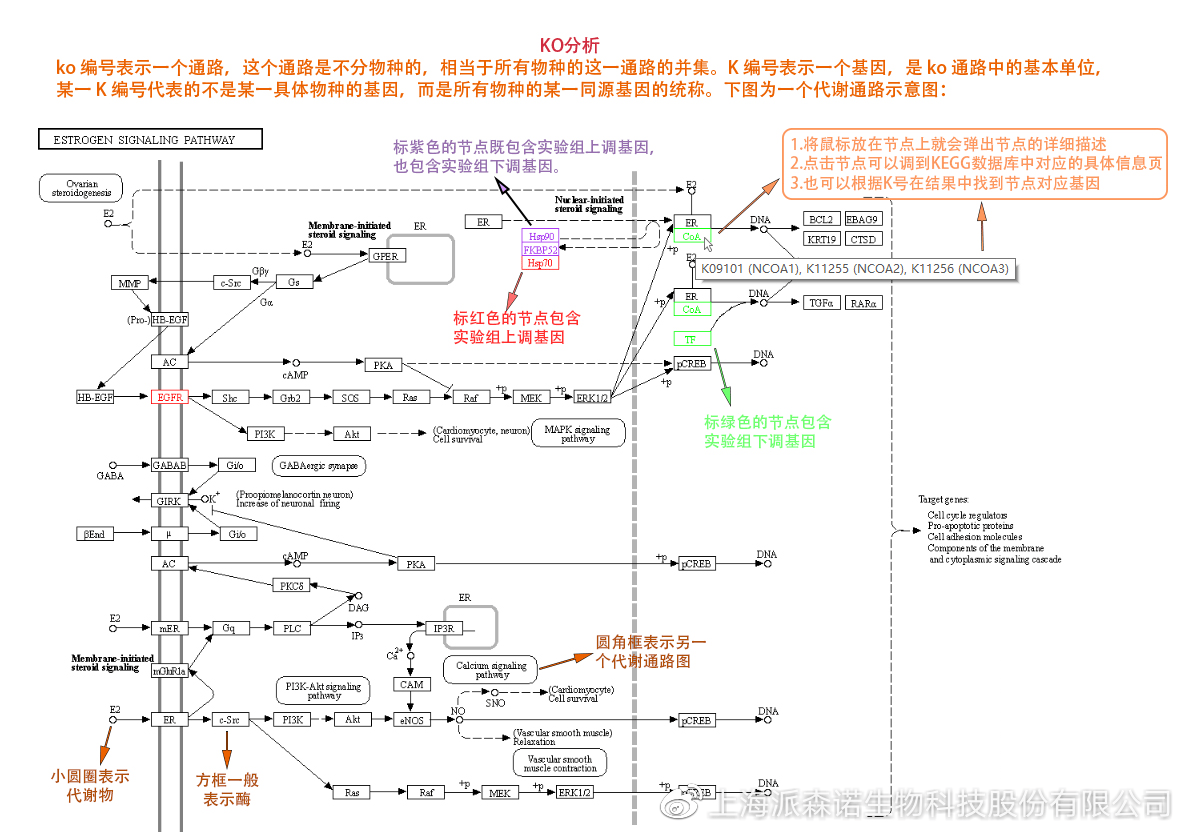
如何将得的差异基因与代谢通路联系起来?KEGG富集分析帮你轻松搞定。KEGG(Kyoto Encyclopedia of Genes and Genomes,http://geneontology.org/)是一个整合了基因组、化学和系统功能信息的数据库,其中KEGG PATHWAY是其核心数据库之一。通过对差异基因进行KEGG通路富集分析,可以了解差异基因富集的代谢通路,从而在代谢通路水平阐明样本间的差异。在转录组分析中,通过柱状图、气泡图和KO分析来全方位展示这部分的结果。
1、 柱状图&气泡图
根据p值由小到大进行排序,对前30个差异表达基因富集最显著的KEGG pathway使用柱状图进行展示,气泡图则展示差异富集最显著的前20个KEGG pathway。
2、 KO分析
通过KO分析,就可以直接在关注的代谢通路上,更直观的看到实验组和对照组差异基因表达的情况。
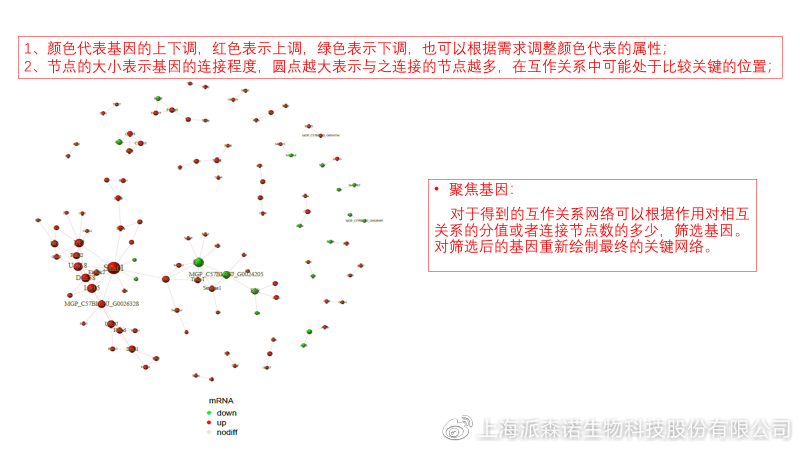
图说八、 蛋白互作网络分析
蛋白互作网络分析简称PPI分析,是揭示基因之间互作关系的分析。分析使用STRING 数据库进行互作关系的预测。STRING 数据库(Search3 Tool for the Retrieval of Interacting Genes/Proteins)是EMBL开发的蛋白质互作数据库,https://string-db.org/cgi/input.pl,该数据库从最有力的实验证据到数据挖掘、同源预测的蛋白质互作关系都有收录。
PPI分析可以对目标基因集进行互作关系的探索,从基因集中筛选关键基因,进一步缩小目标的范围,是数据挖掘的重要组成。
转自:派森诺
- 本文固定链接: https://maimengkong.com/zu/886.html
- 转载请注明: : 萌小白 2022年5月1日 于 卖萌控的博客 发表
- 百度已收录
