文库构建
样品质检合格后,Input样品,使用去核糖体转录组建库,IP样品,核糖体含量低,采用全转录组建库。
文库构建完成后,随后使用 Agilent 2100 Bioanalyzer 对文 库大小范围进行检测,插入的目的片段大小符合预期后,使用 Q-PCR 方法对文库的有效浓度进行准确定量(文库有效浓度 >3nM),以保证文库质量
库检合格后,将不同文库按照有效浓度及目标下机数据量的需求 pooling,采用 Nova PE150 模式进行测序。测序数据量 6G。
分析流程
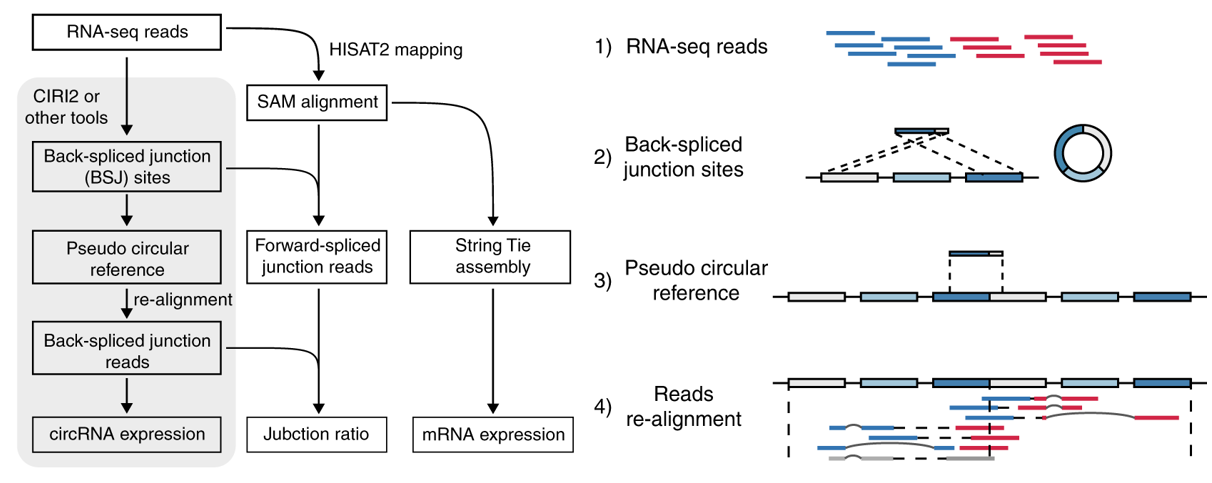
circRNA的分析,我们采用最新circRNA分析软件CIRIquant。 首先对Raw reads进行过滤,去除接头序列、含N较多的序列及低质量的reads,获得高质量 数据(Clean reads)。然后通过与核糖体数据库进行比对,去除核糖体RNA 序列,获得effective reads,一方面,将effective reads 通过hisat2与参考基因组进行比对(mapping)通过string将mapping的reads组装成mRNA,产生mRNA表达矩阵。另一方面,effective reads 通过CIRI2预测circRNA的反向剪切位点(Back-splicing junction),得到预测的circRNA,再将预测的circRNA重新匹配回反向剪切位点的reads,得到circRNA的表达矩阵,于此同时,两个方面联合分析可得到circRNA的剪切比率。
- 本文固定链接: https://maimengkong.com/zu/1295.html
- 转载请注明: : 萌小白 2022年11月20日 于 卖萌控的博客 发表
- 百度已收录
