作者:Carson 数据分析师,R语言中文社区专栏作者。知乎专栏:https://zhuanlan.zhihu.com/carson-0814
数据源:朝阳医院2016年销售数据
分析指标:1、月均消费次数;2、月均消费金额;3、客单价;4、消费趋势
打开excel数据源,数据的基本字段如下:

一、将excel数据源导入R中

二、对数据进行预处理
“数据是一件麻烦的事——一件非常非常麻烦的事。”,数据分析工作中,我们可能有多达60%的数据分析时间都花在了实际分析前数据的准备上。
主要体现在:a、操纵日期和缺失值; b、数据类型的转换; c、变量的创建和重编码; d、数据集的排序、合并与取子集; e、选入和丢弃变量
本例中首先依据具体的分析思路,对数据进行预处理
1、变量重命名
首先,将列名重命名,有两个方法,第一,编程的方式,用names()函数来重命名变量。
"time", "cardno", "drugId", "drugName", "saleNumber", "virtualmoney", "actualmoney"
代码如下:

也可以指定向量对单个变量进行重命名。
第二,用fix(excelDate)调用一个交互式的编辑器,单击变量重命名也可以。

第三,plyr包中有一个rename函数,可以用于修改变量名。
2、缺失值
R中缺失值以符号(NA)表示,函数is.na()允许检测缺失值是否存在。
例如:y <- c(1,2,3,NA)
用函数 is.na(y) 将返回c(FALSE, FALSE, TRUE),也就是如果某个元素是缺失值,相应的位置将返回TRUE,不是缺失值的返回FALSE。关于缺失值有两点要注意:1)、缺失值被认为是不可比较的,即便是与缺失值自身的比较,这意味着不能用比较运算符来检测缺失值是否存在。
2)、R并不把无限的或者不可能出现的数值标记成缺失值。

这里的excelData[,1:7]将数据框限定在第1到第7列,用is.na()函数识别缺失值。
下面的代码,我们删除了time列的缺失值,代码中将下标留空(,)表示默认显示所有列。
3、处理日期数据
使用R语言中字符串处理包stringr,install.packages("stringr"),library(stringr)载入stringr包,

用class()函数查看日期的格式,日期值通常以字符串的形式输入到R中,可以用as.Date()函数执行转化成以数值形式存储的日期变量。语法as.Date(x, "input_format")

4、数据类型转换
R中提供了一系列用来判断某个对象的数据类型和将其转换为另一种数据类型的函数。
比如,is.numeric() 和 as.numeric() ,is用于判断数据属于哪种类型,对于处理复杂的业务逻辑,例如销售金额,判断是否为数值; as用于各个类型值直接的转换,转换成你想要的类型。
以下代码使用as.numberc从销售数据里的字符串转换为数值类型。

5、数据排序
用order()函数对数据框进行排序,默认的排序顺序是升序,在排序变量的前边加一个减号即可以得到降序排序的结果,或者使用decrease = TRUE来完成。以下代码我们按照销售时间对数据进行降序排序。
得到结果

三、分析具体的业务指标
1、月均消费次数
月均消费次数=总消费次数/月份数 (同一天内,同一个人发生的所有的消费算作一次消费)
用duplicated()函数是从数据框中选出重复的数据。我们的需求是将重复的数据删除,因此我们用了逻辑运算符!来去掉多余的数据。

2、月均消费金额
月均消费金额=总消费金额/月份数,月均消费金额为实收金额(actualmoney)

na.rm表示移除缺失值 ,na代表缺失值,rm代表remove,在计算的时候,只计算有值的数据。
3、客单价
客单价=总消费金额/总消费次数,客单价是指门店每一个顾客平均购买商品的金额,也就是平均交易金额。
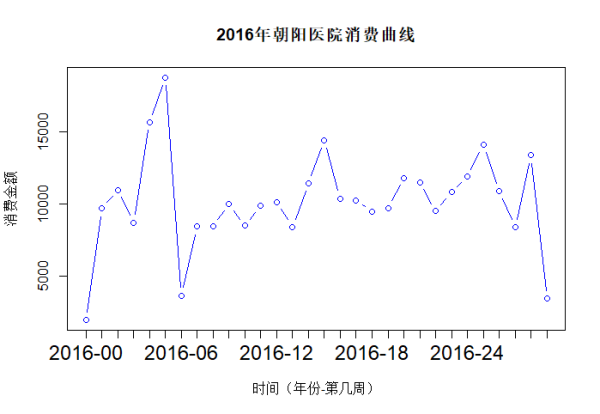
4、消费趋势
绘制图表,确立横坐标为周数,纵坐标为销售金额。
计算每周的销售金额。我们使用分组函数tapply()

绘制图形

数据处理具体代码如下:
#导入数据源
library(openxlsx)
readFilePath <- "C:/Users/shuer/Desktop/朝阳医院2016年销售数据.xlsx"
excelData <- read.xlsx(readFilePath, "Sheet1")
#重命名变量
names(excelData)<-c("time","cardno","drugId","drugName","saleNumber","virtualmoney","actualmoney")
fix(excelData)
names(excelData) [2] <- "cardno1"
#rename()函数修改变量名
install.packages("plyr")
library(plyr)
excelData <- rename(excelData, c(time="Time", drugid="drugId")
#判断是否是缺失值
is.na(excelData[,1:7])
#删除缺失值
excelData <- excelData[!is.na(excelData$time),]
#处理字符串
install.packages("stringr")
library(stringr)
timeSplit <- str_split_fixed(excelData$time," ",n=2)
excelData$time <- timeSplit[,1]
excelData$time
#查看数据类型
class(excelData$time)
excelData$time <- as.Date(excelData$time, "%Y-%m-%d")
#转换数据类型
attach(excelData)
saleNumber <- as.numeric(saleNumber)
virtualmoney <- as.numeric(virtualmoney)
actualmoney <- as.numeric(actualmoney)
detach(excelData)
#数据框按时间降序排序
excelData <- excelData[order(excelData$time,decreasing = TRUE),]
#月均消费次数=总消费次数/月份数
kpi1 <- excelData[!duplicated(excelData[,c("time", "cardno")]),]
#总消费次数
consumeNumber <- nrow(kpi1)
#最大时间值
startTime <- kpi1$time[1]
#最小时间值
endTime <- kpi1$time[nrow(kpi1)]
#天数
day <- startTime - endTime
#月份数
month <- as.numeric(day) %/% 30
#月均消费次数
monthConsume <- consumeNumber/month
#月均消费金额
totalMoney <- sum(excelData$actualmoney, na.rm = TRUE)
monthMoney <- totalMoney/month
#客单价
pct <- totalMoney/consumeNumber
#按销售时间分组,将销售时间按周分组
week <- tapply(excelData$actualmoney, format(excelData$time,"%Y-%U"),sum)
#将数据转换为数据框结构。
week<-as.data.frame.table(week)
#对列名重命名
names(week)<-c("time","actualmoney")
week$time<-as.character(week$time)
week$timeNumber<-c(1:nrow(week))
#绘制图形
plot(week$timeNumber,week$actualmoney,
xlab="时间(年份-第几周)",
ylab="消费金额",
xaxt="n",
main="2016年朝阳医院消费曲线",
col="blue",
type="b")
axis(1,at=week$timeNumber,labels = week$time,cex.axis=1.5)- 本文固定链接: https://maimengkong.com/learn/936.html
- 转载请注明: : 萌小白 2022年5月25日 于 卖萌控的博客 发表
- 百度已收录
