封面来源于:Pixabay+易生信
生物信息学习的正确姿势
NGS系列文章包括、 高颜值在线绘图和分析 、转录组分析 )、ChIP-seq分析 ()、单细胞测序分析 ()、DNA甲基化分析、重测序分析、GEO数据挖掘() 、 批次效应处理 等内容 。
所以关注火山图(其它类型图也是),先理解 每个点是什么 (点代表基因、样品、通路或其它的,这个认识可以来自于常识,更准确的是看作者的描述),然后看 横轴代表什么 、 纵轴代表什么 ,再看图例中展示的其他信息,如颜色、大小和形状分别代表什么。 这些都理顺了,图理解就不难了。
如图一:
- 每个点代表一个检测到的 基因 。
- 横轴和纵轴用于固定点在空间的位置。
- 一般横轴是 Log2(fold change) ,点越偏离中心,表示差异倍数越大。
- 纵轴是 -Log 10 (adjusted P-value) ,点越靠图的顶部表示差异越显著。
- 点的大小和颜色也可以表示更多的属性,如下图中点的颜色标记其对应的基因是 上调 , 下调 还是 无差异 。 大小也可用于展示基因表达的平均丰度,一般我们关注表达水平较高且差异较大的基因用于后续的分析和验证。
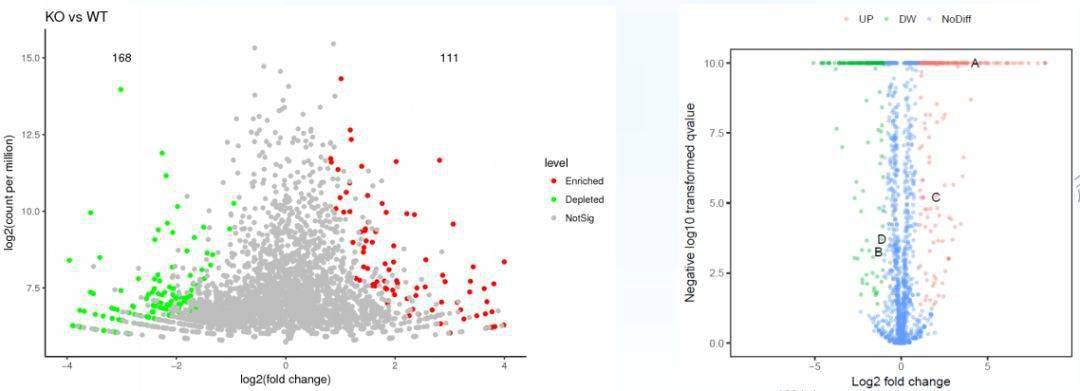
图一( 图源:易生信PPT)
火山图理解常见的几个问题
但没想到,在我们易生信培训过程中,对火山图的问题还是比较多的,我们一个个的说一下。
- 什么是 fold change ? 翻译成中文是 差异倍数 ,简单来说就是基因在一组样品中的表达值的均值除以其在另一组样品中的表达值的均值。 所以火山图只适合展示两组样品之间的比较。
- 为什么要做 Log 2 转换? 两个数相除获得的结果 ( fold change )要么 大于 1,要么 小于 1,要么 等于 1。 这是一句正确的废话吧? 那么对应于基因差异呢? 简单说,大于1表示上调(可以描述为上调多少倍),小于1表示下调(可以描述为下调为原来的多少分之多少)。 大于1可以到多大呢? 多大都有可能。 小于1可以到多小呢? 最小到0。 用原始的 fold change 描述上调方便,描述下调不方便。 绘制到图中时,上调占的空间多,下调占的空间少,展示起来不方便。 所以一般会做 Log 2 转换。 默认我们都会用两倍差异 ( fold change == 2 | 0.5 )做为一个筛选标准。 Log2 转换的优势就体现出来了,上调的基因转换后 Log2 (fold change) 都大于等于 1 ,下调的基因转换后 Log2 (fold change) 都小于等于 -1 。 无论是展示还是描述是不是都更方便了。
- P-value 都比较熟悉,统计检验获得的是否统计差异显著的一个衡量值,约定成俗的 P-value<0.05 为统计检验显著的常规标准。
- 什么是 adjusted P-value ? 这里面就涉及到一个统计学问题了。 做差异基因检测时,要对成千上万的基因分别做差异统计检验。 统计学家认为做这么多次的检验,本身就会引入假阳性结果,需要做一个多重假设检验校正。 这个校正怎么做呢? 最简单粗暴的方法是每一次统计检验获得的 P-value 都乘以总的统计检验的次数获得 adjusted P-value (这就是 Bonferroni correction )。 但这样操作太严苛了,很容易降低统计检出力,找不到有差异的基因。 后续又有统计学家提出相对不这么严苛的计算方法,如 holm , hochberg , hommel , BH , BY , fdr 等。 BH 是我们比较常用的一个校正方法,获得的值是 假阳性率 FDR ( false discovery rate )。 FDR 筛选时就可以不用遵循 0.05 这个标准了。 我们可以设置 FDR<0.05 表示我们容许数据中存在至多 5% 假阳性率; FDR<0.1 表示我们对假阳性率的容忍度至多是 10% 。 当然如果说我们设置FDR<0.5,即数据中最多可能有一半是假阳性就说不过去了。
- 同样为什么做 -Log 10 转换呢? 因为FDR值是 0-1 之间,数值越小越是统计显著,也越是我们关注的。 -Log 10 (adjusted P-value) 转换后正好是反了多来,数值越大越显著,而且以 10 为底很容易换算回去。
理解完这些之后,再来看火山图。
- 整体来看,基因有上调就有下调,图整体是以 X=0 的垂线左右对称的。 如果数据中大部分点都是上调或下调,成偏态分布时,需考虑标准化步骤没有处理好,或数据存在批次效应,导致数据存在系统偏差。
- 图的左上角和右上角是差异基因集中的地方,也是我们关注的重点。
- 图一中左侧的火山图还展示了基因表达的平均丰度,即基因在所有样品中表达的均值。 一般变化倍数大、平均表达也比较高的基因会更可信,更适合后期实验检测,否则就算变化倍数再大,表达低的基因也难以被检测到。
番外:
- 差异倍数 fold change 还有另外一种处理方式。假如有两个样品 A 和 B 。如果某个基因在 A 中表达比较高,则计算 fold change 是用 A/B ; 。如果某个基因在 B 中表达比较高,则计算 fold change 是用 B/A ,然后乘以 -1 ; gtools::foldchange 是这么操作的。
- adjusted P-value , q value , fdr 一般代表相同的含义,都是多重假设检验校正后的 P-value ,可能的区别就在于校正算法的不同。
几个代表性火山图
火山图虽然用的多,但其实能提供的信息算不上多,一般是在上面标记一些关注的基因的名字,然后在正文中做下描述。标记基因名字的方式也比较多,图二中左图的颜色标示是一个不错的选择。
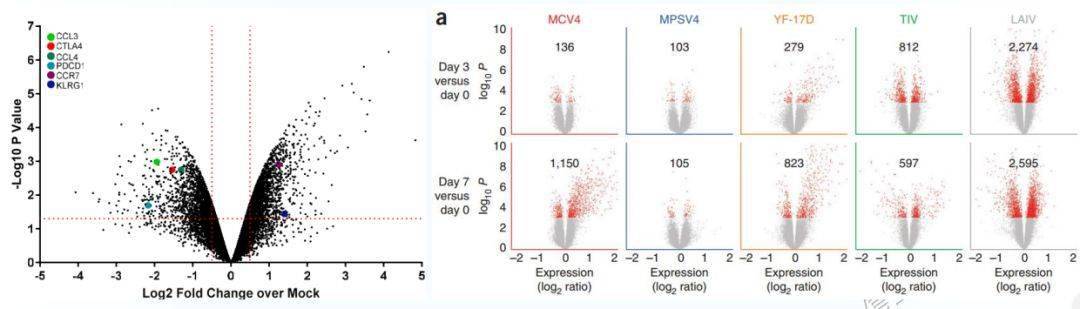
图二( 图源:易生信PPT)
图二右图来自2017年发表在 Cell 的一篇文章- Epigenetic Therapy Ties MYC Depletion to Reversing Immune Evasion and Treating Lung Cancer 。
一排火山图放在一起是不是很有气势,更主要的是展示了5种疫苗诱导的差异基因数目显著不同,在图上红点多少展示出的视觉冲击还是优于图标中的数字表示的,更容易留下直观的印象。个人觉得是一个很有特色的火山图案例。
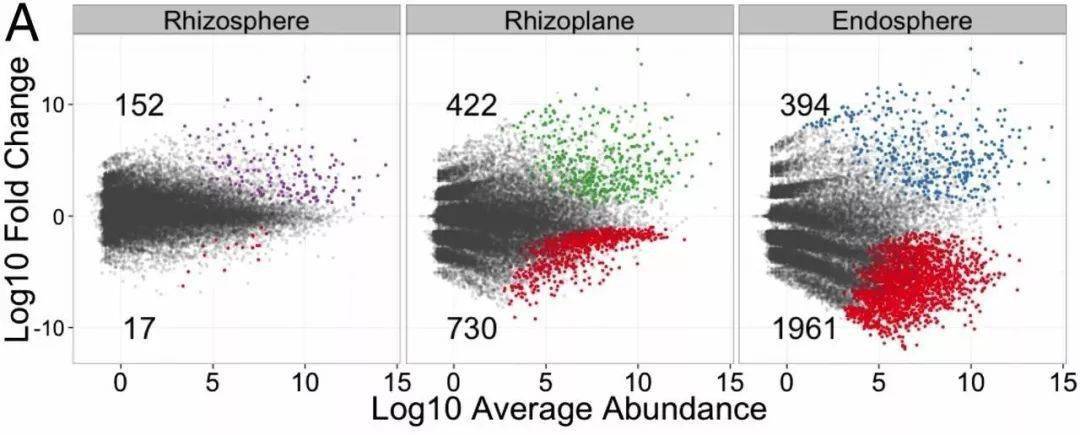
图三
图三来自文章 Edwards, J., et al. (2015). PNAS Fig. 2A 。
- http://www.pnas.org/content/112/8/E911.short
这是一篇16S分析文章较系统的作品,两年被引用147次,推荐阅读。上面的火山图展示了水稻根不同生态位相对于土壤中显著差异的 OTU ,横坐标是相对丰度平均值( Log10 转换),纵坐标是 Log10(fold change) ,整体类似于图一中的左图,只是转换了 X 和 Y 轴变量。
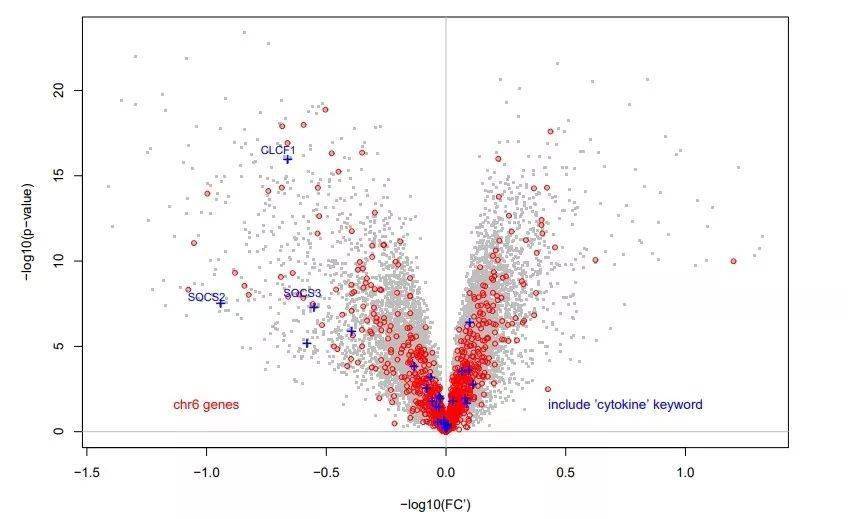
图四
火山图就是散点图,点的颜色可展示代表性属性。
图四来源— https://arxiv.org/pdf/1103.3434.pdf:
第6号染色体上的探针/基因用红色标记,在基因注释中带有“细胞因子”的探针/基因用蓝色标记。
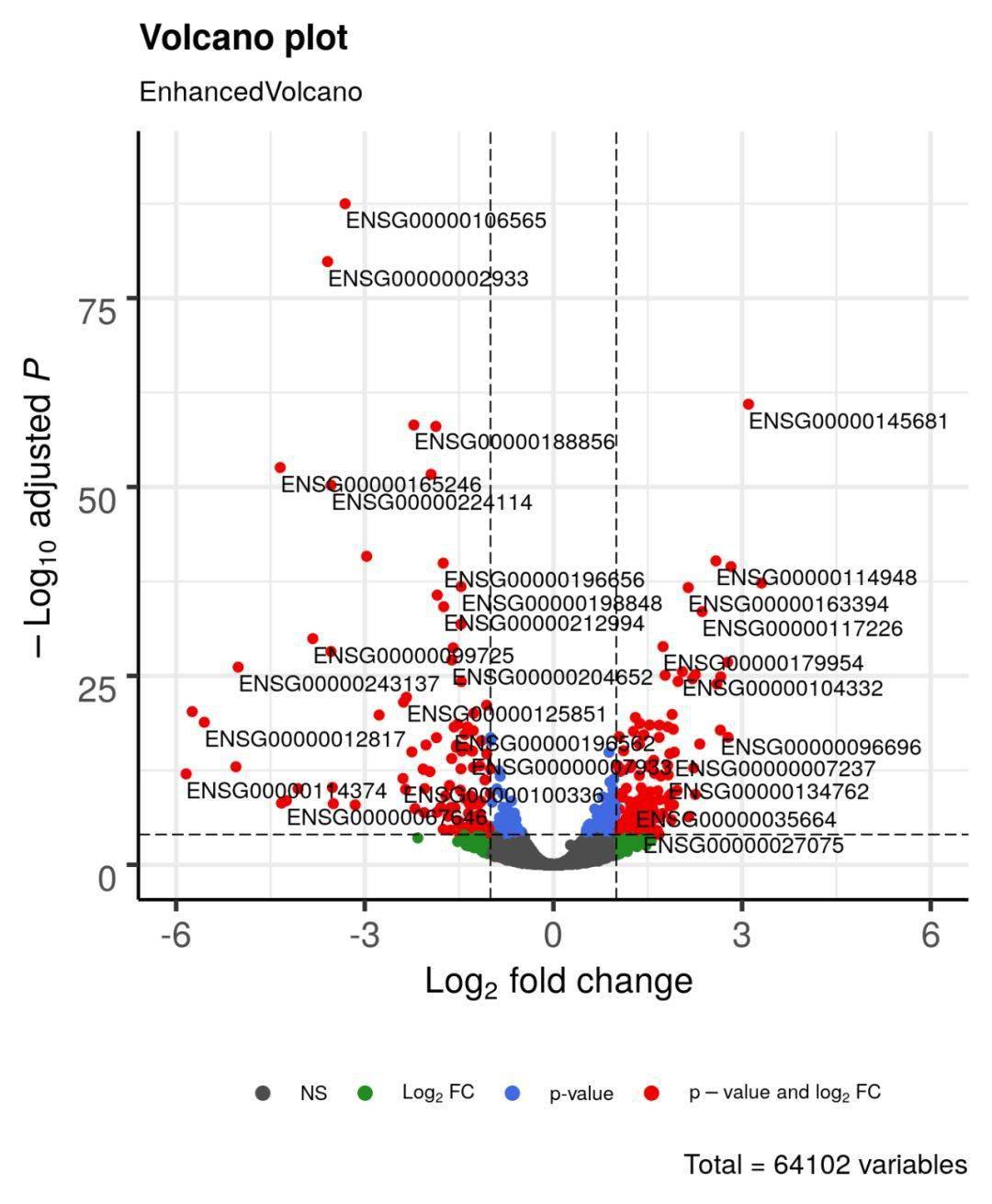
增强火山图之在基本火山图的基础上,标注有变量名。
上图共有64102个变量, 绿色的点的 |log2FC |>1 , 蓝色的点是在 P value <0.0001 的基础上,校正得到的符合要求的点。 红色的点是满足了以上两点要求的变量。
如有雷同数据,可大胆参照模仿,更多增强火山图见:
传送门(代码)➷➷
- 增强火山图,要不要试一下?
最简单的绘制方法是使用我们的在线网站—— imageGP(http://www.ehbio.com/ImageGP/)。
- 本文固定链接: https://maimengkong.com/image/888.html
- 转载请注明: : 萌小白 2022年5月1日 于 卖萌控的博客 发表
- 百度已收录
