随着生物科技的迅速发展,每天都会有海量的生物学数据产生,如何有效的分析这些“生物学大数据”?生物信息学的应用变得尤为重要,在生物领域从基因测序,到基因编辑,再到基因疗法的精准医疗,由生物科技引发的又一场变革正悄然而至。试问大家做好准备迎接它到来了吗?
本次分享的主题为:如何快速获取海量数据?我们就从物种的DNA或蛋白质序列说起,在我们的科学研究中下载序列是一件简单不过的事情,无非就是联网NCBI等主页上,选择数据库后输入AC号或GI号后直接下载。
如果是少量的序列数据,我们可以通过一个个ID去查找,复制,粘贴方式保存到本地文件中。
但是如何大批量下载数据呢?再通过复制、粘贴方法虽然很精确但是对于大批量的数据下载效率实在是太低了。是否可以直接下载数据库准备好的序列文件?或者编写程序脚本进行批量下载?
本次小鹿分享的是2种热门物种(人和鼠)的无编程基础的下载方式。(我们后面会分享“如何使用代码批量下载生物学序列数据”)
物种 人
1.NCBI的GenBank数据库
基因:MYH9
物种:人Homo sapiens
(1)用浏览器登录NCBI数据库官网:https://www.ncbi.nlm.nih.gov/
(2)数据库选择框:选择Gene;在搜索框输入:MYH9,可以添加Homo sapiens或者Human,这样匹配更准确;
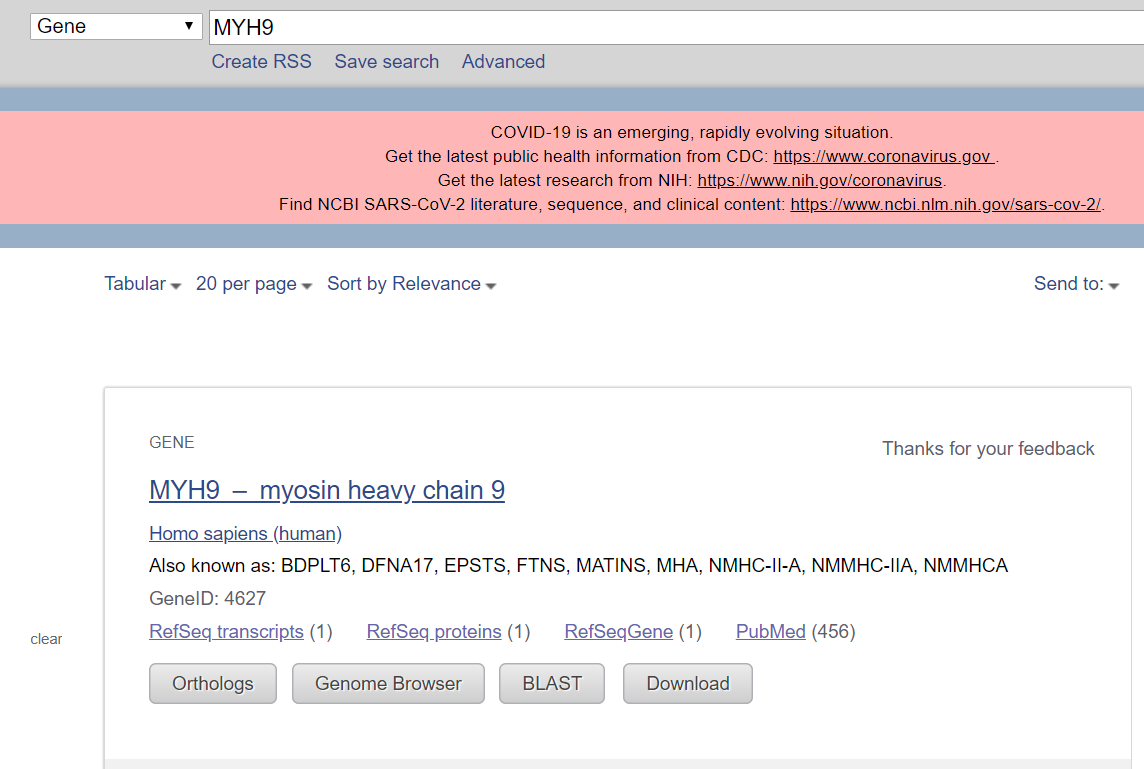
(3)点击MYH9 - myosin heavy chain 9,选择FASTA格式;
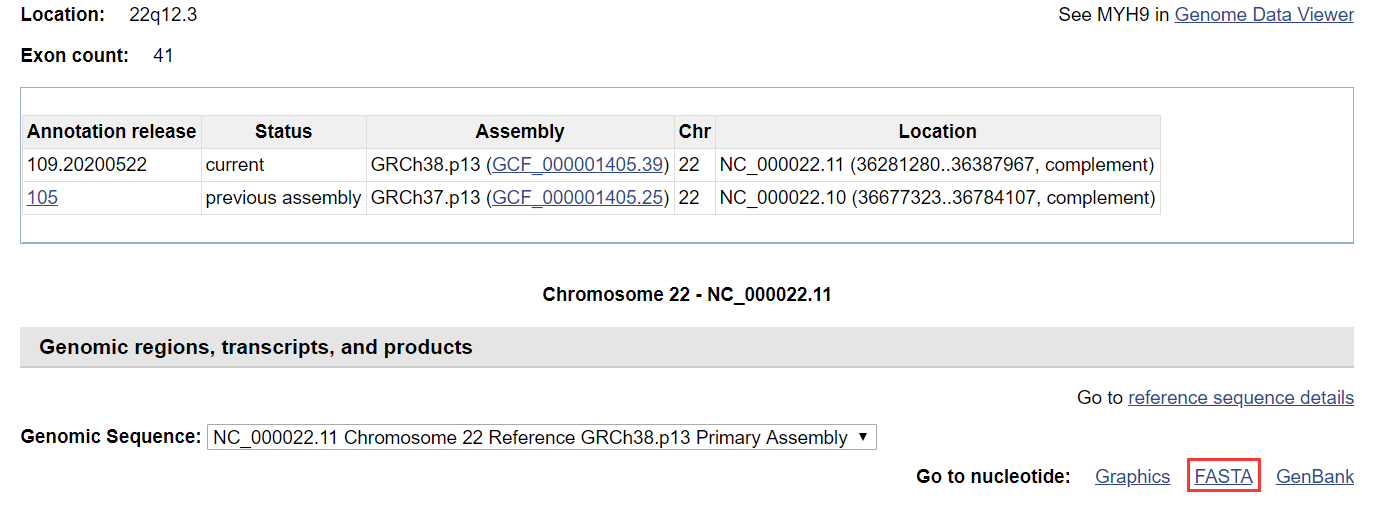
(4)点击下载MYH9基因序列NCBI Reference Sequence: NC_000022.11,起个合适的文件名,推荐使用基因名或者数据库登录号;
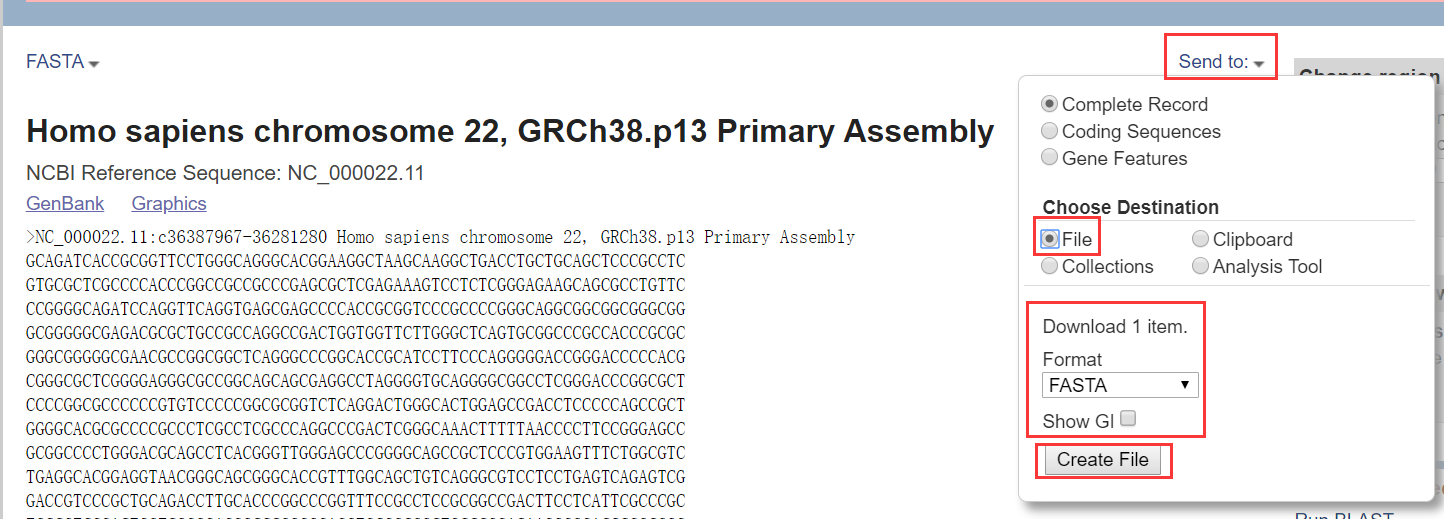
(5)物种基因组和蛋白组序列的下载
选择Genome子数据库,同样在搜索框输入物种英文名或拉丁学名,例如,输入human,我们查找人的基因组数据,如下所示:
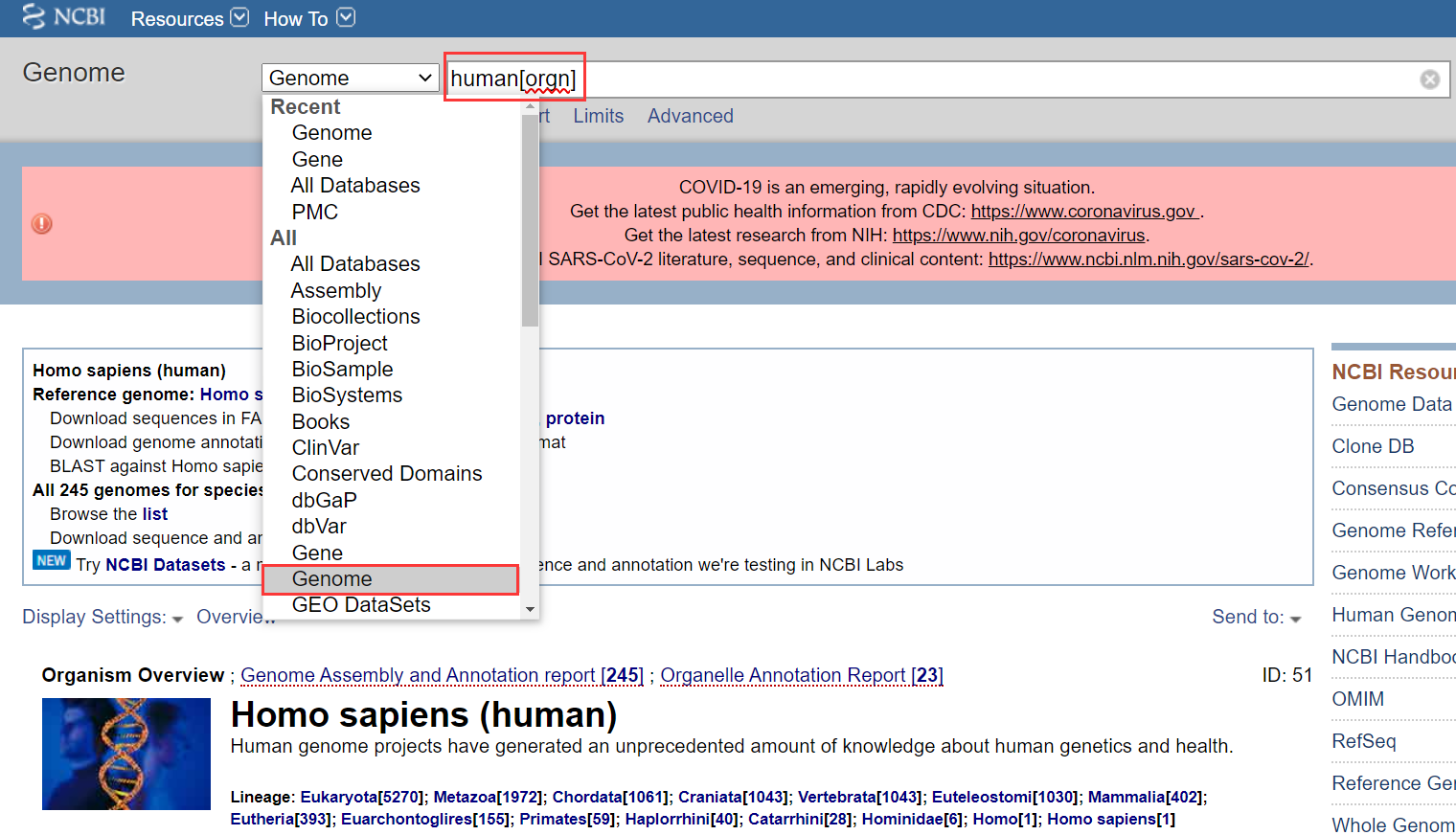
点击下载基因组或蛋白组FASTA序列,直接会弹出下载链接,选择保存文件的位置即可开始下载;
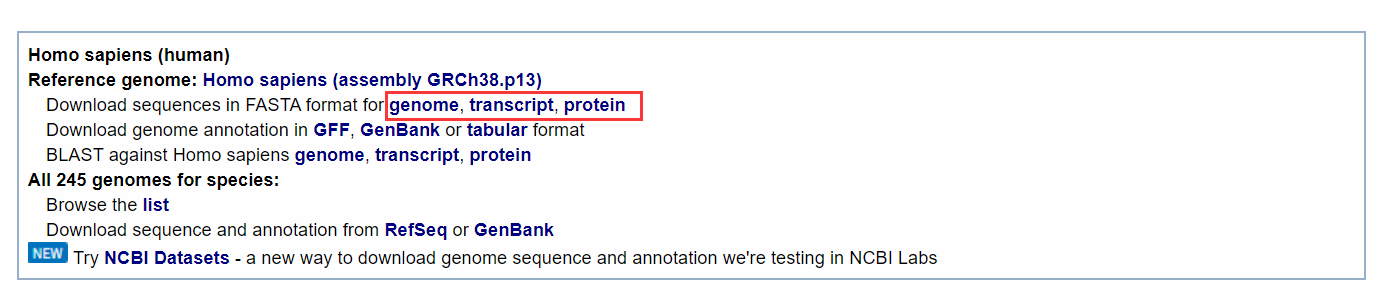
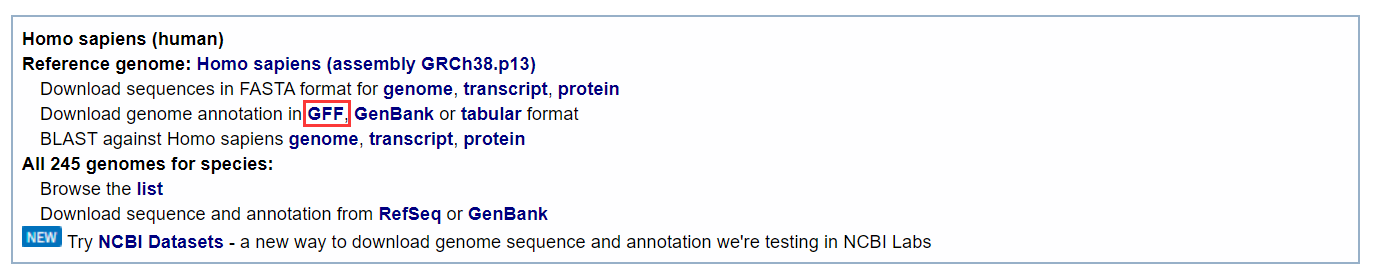
还可以下载NCBI上的基因组注释GFF文件(Ensembl数据库也可以下载物种的GFF文件,后面会给大家讲到)
物种 人和小鼠
2.Uniprot数据库
样例蛋白:P35579
物种:人Homo sapiens和小鼠Mus musculus
(1)用浏览器登录Uniprot数据库官网:https://www.uniprot.org/
(2)搜索框输入:P35579,点击Search;

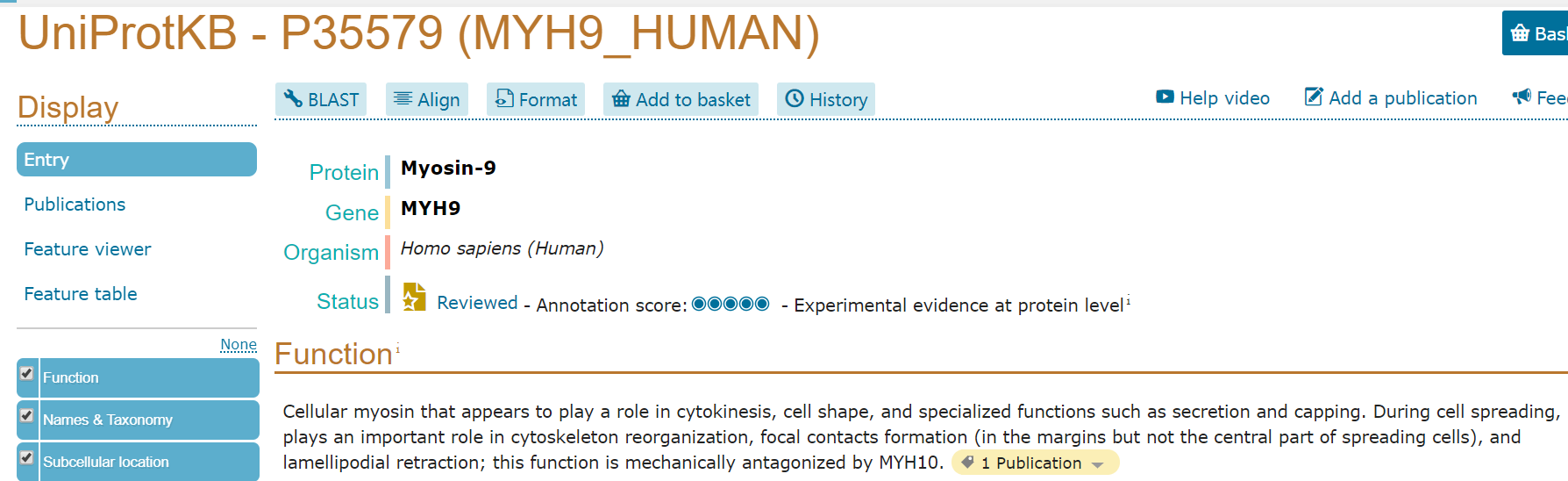
(3)查看P35579蛋白的生物学信息:肌球蛋白9(Myosin-9);
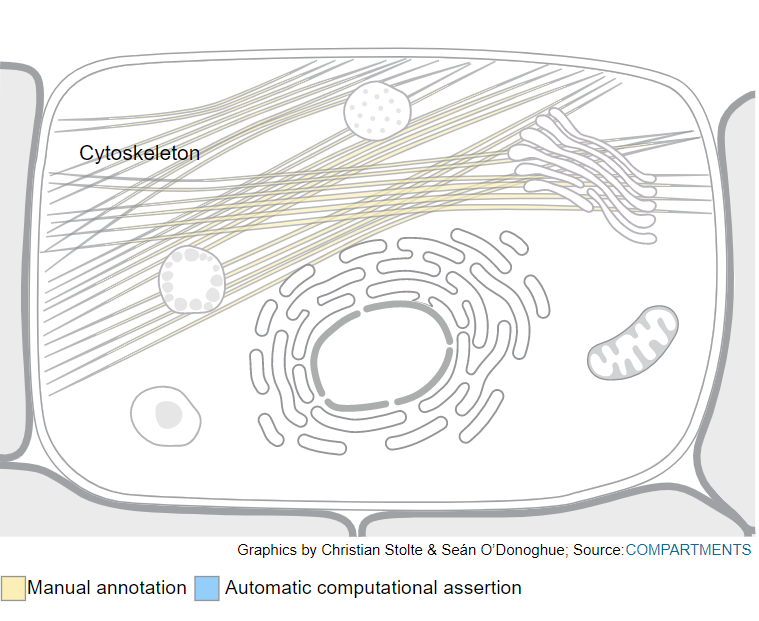
可以看到该蛋白主要分布在细胞基质中,是细胞的动力蛋白;
(4)下载序列数据,点击FASTA;
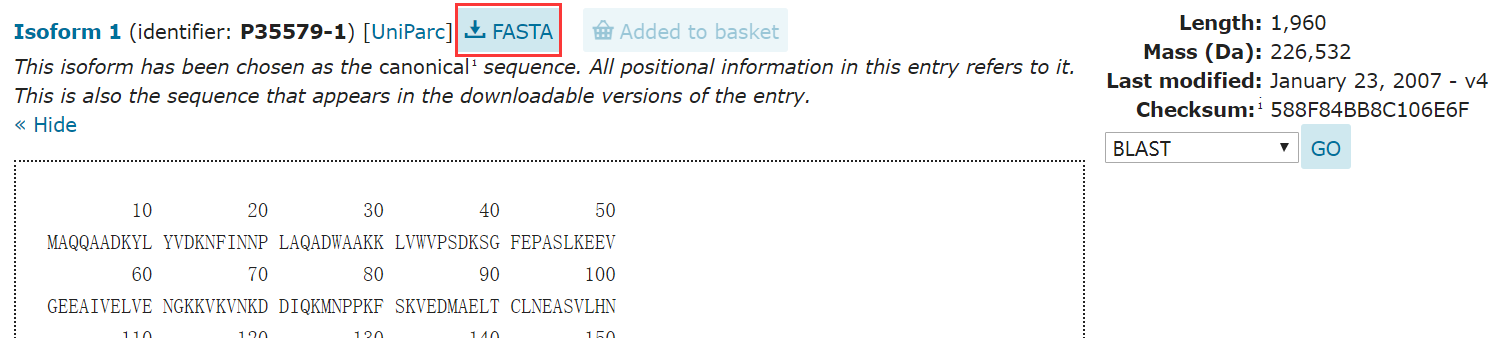
(5)下载物种蛋白质组序列文件(例如下载物种:小鼠mus musculus);

在Uniprot数据库官网选择Proteomes子库,然后在搜索框输入:mus musculus,选择Organism ID为10090的小鼠;

点击Protein Count: 55462,显示小鼠蛋白Entry,可以根据需要定制自己需要的数据:例如,我们需要GeneID,点击Columns进行个性化的定制;
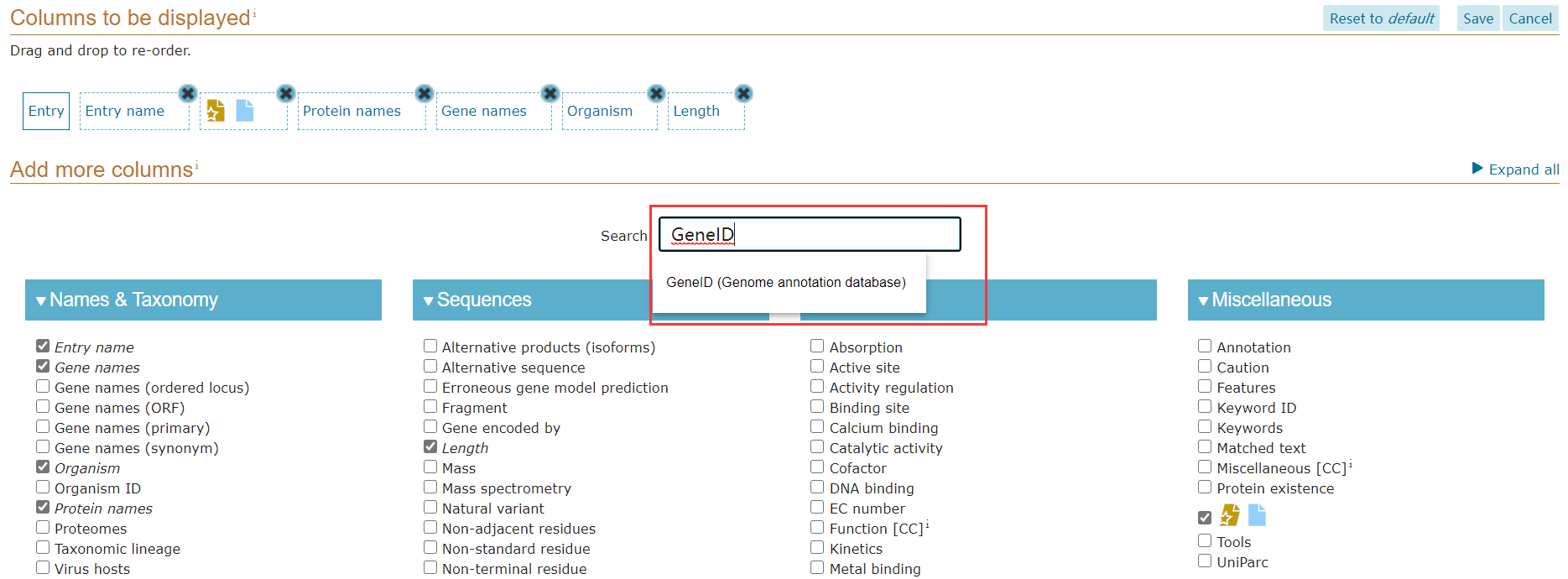
如下所示:

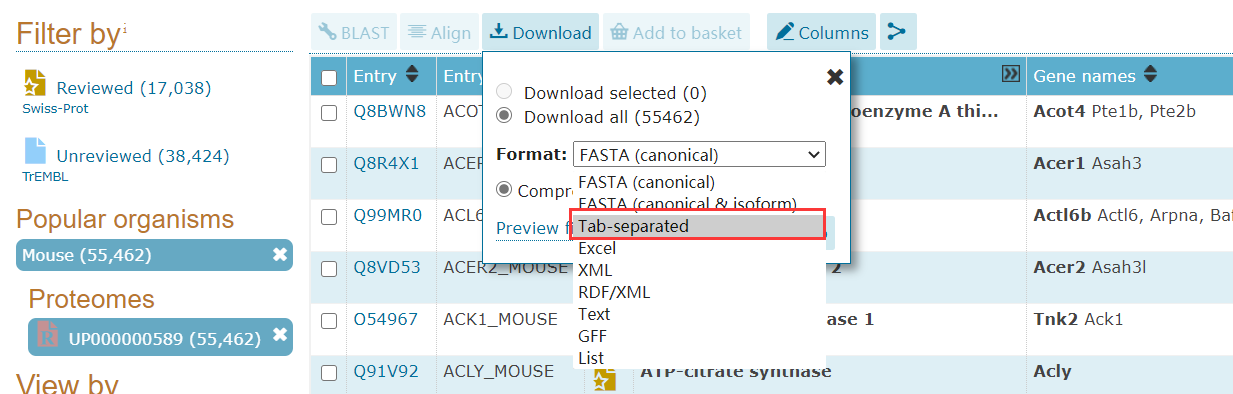
点击Download下载所需要的数据,选择文件格式。如果我们需要的是表格数据,我们通常下载为Tab分割符(Tab-separated)的txt文件,因为Excel表格有最大行数的限制,如果超出最大行数会导致数据丢失;
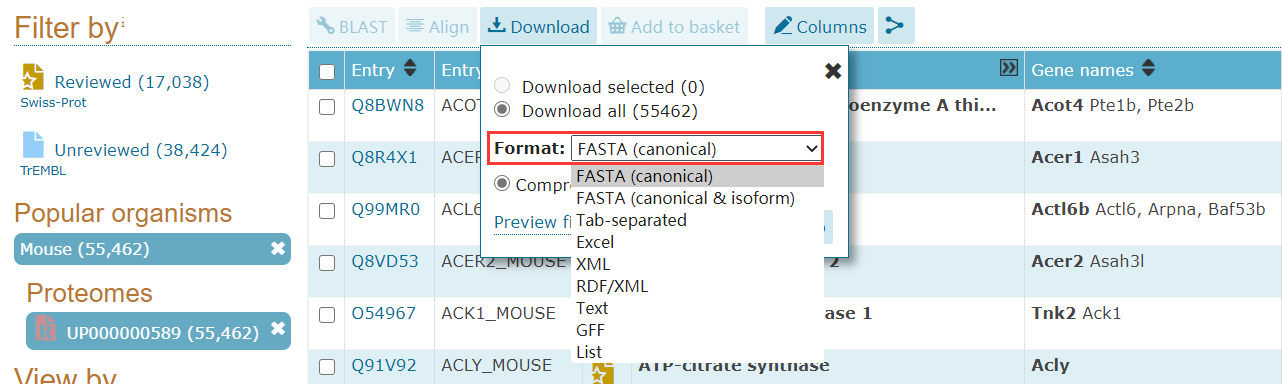
如果是序列文件,我们选择下载FASTA格式的文件;
物种 人
3.Ensembl(Ensembl Genome Browser)数据库
物种:人Homo sapiens
(1)使用浏览器登录数据数据库:https://asia.ensembl.org/index.html
(2)选择Human数据库,如下所示:
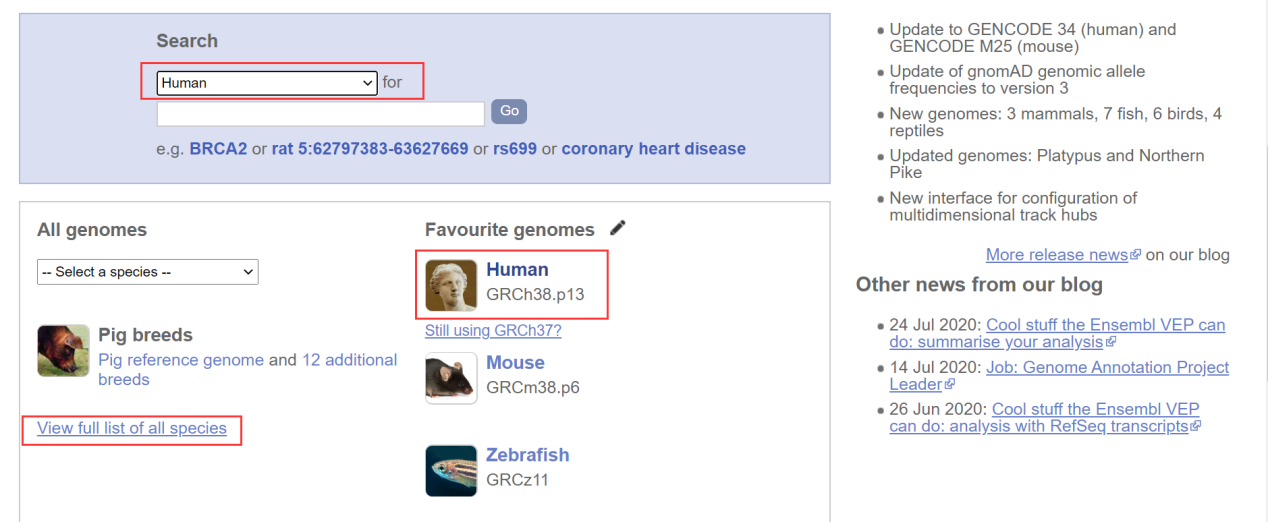
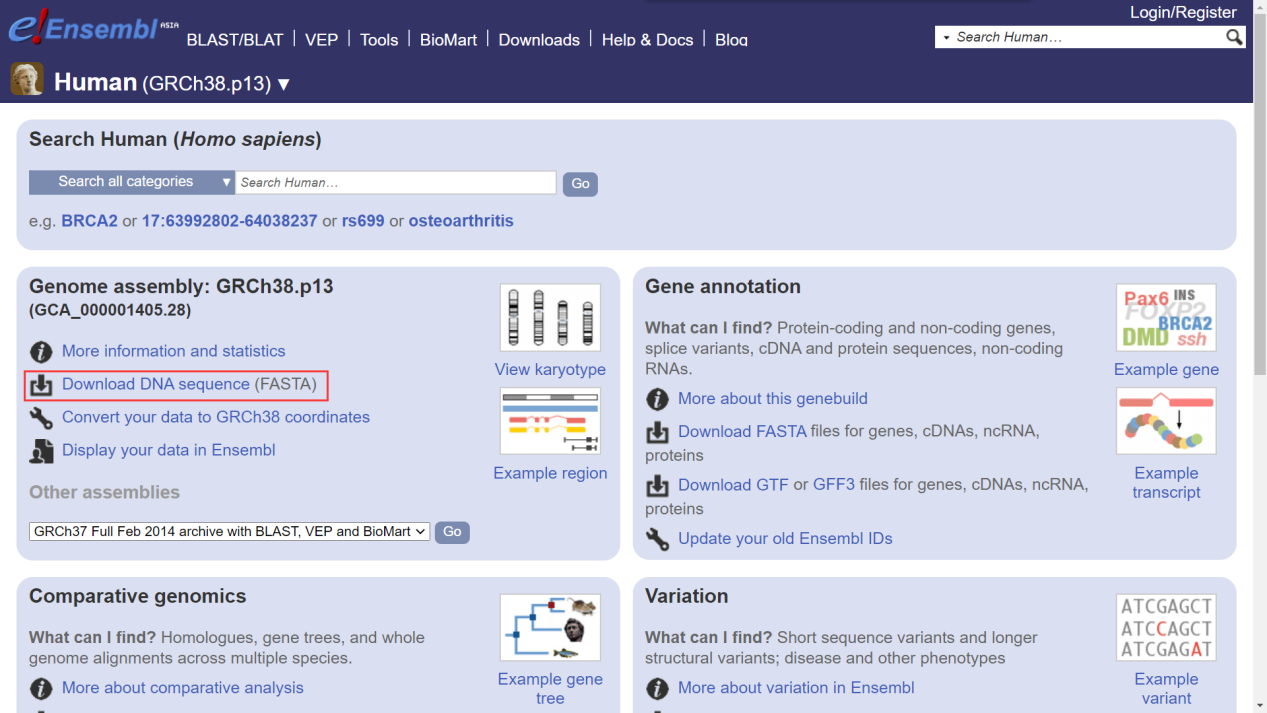
(3)选择下载基因组序列,见下图:
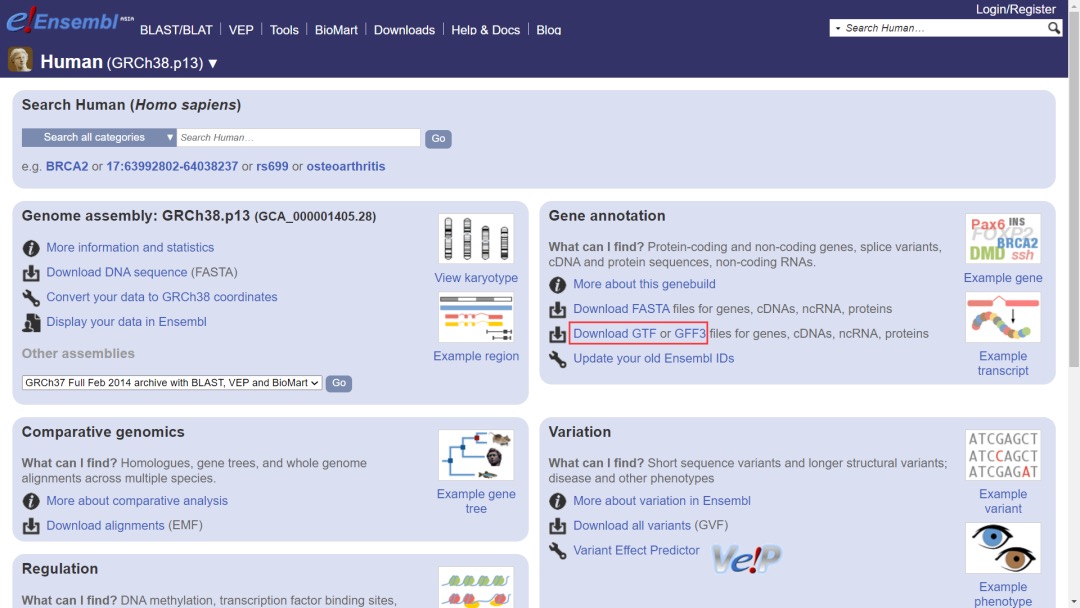
(4)在Ensembl数据库下载物种的GFF文件
前面我们讲到了在NCBI数据库中下载物种基因组注释GFF文件,其实我们还可以在Ensembl数据库中下载物种的注释文件,而且在Ensembl中下载的GFF文件更加标准,使用起来更方便。
(5)直接连接到ensembl的FTP服务器,
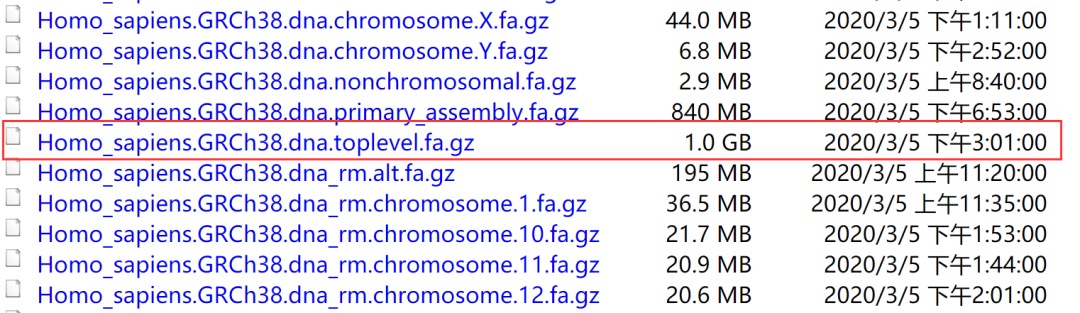
网址:ftp://ftp.ensembl.org/pub/release-100/fasta/homo_sapiens/dna/
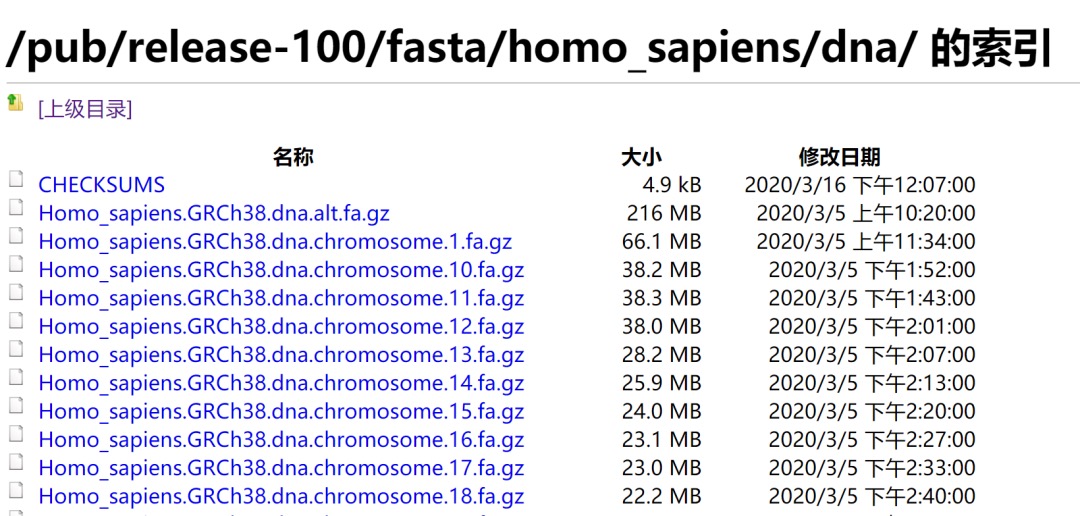
选择toplevel标签的序列文件进行下载,如下所示:
- 本文固定链接: https://maimengkong.com/zu/760.html
- 转载请注明: : 萌小白 2021年8月25日 于 卖萌控的博客 发表
- 百度已收录
