本文根据 2016 年 8 月清华大学颉伟研究员在复旦大学「表观基因组学暑期国际讲习班」中的报告整理而成,本文采用第一人称叙述,文中的“我”皆指颉伟研究员。报告原视频详见:系列视频5 | 清华颉伟:表观遗传的遗传与重编程,视频全长约 2h30min,文字约 2 万字(不含提问)。且听颉伟教授由浅入深,娓娓道来。
本文正确打开方式:阅读 2 万字长文确实需要花点时间,不过本文语言通俗,逻辑严密,建议收藏当成小说读,花半天或更多的时间慢慢消化。想要全面了解一个研究方向,这点时间还是要舍得花的。如果嫌文字太枯燥,可以看视频,并结合文字来消化。
颉伟研究员,青年千人,求是杰出青年学者,HHMI 国际研究学者。2003 年本科毕业于北大,2008 年博士毕业于加州大学洛杉矶分校,博士期间同时取得了统计学硕士学位,2008~2009 年在加州大学洛杉矶分校进行博士后训练,2009~2013 年在美国圣地亚哥 Ludwig 肿瘤研究所、加州大学圣地亚哥分校任兵教授实验室进行博士后训练,2013 年加入清华大学,任清华大学生命科学学院研究员、清华北大生命科学联合中心研究员。
以下为正文:
我先来介绍一下我自己,尤其是我这个名字。这两个字"颉伟"念 Xie Wei,"愿君多采撷"的"撷"去掉提手旁就是这个字。等一会儿大家有什么问题要提问的时候,就不用太担心。

图 1. Epigenetic Inheritance and Reprogramming
Part 1: 表观遗传信息从何而来?
从遗传学说起
非常高兴今天能在这里跟大家分享一下表观遗传学的一些问题和之前很多年的研究成果,其实我今天讲的这个题目是表观遗传的一个非常基本的问题——表观遗传到底能不能遗传。这个问题听起来很奇怪,为什么表观遗传到现在还在研究这个问题?其实这个问题一直都不是很清楚,它是表观遗传非常重要且基础的,但又没有完全解决的问题。
今天在这里我跟大家介绍的东西,是很多年很多人研究成果的积累,很多问题仍然是 open question。但慢慢地随着研究的积累,我们对表观遗传的本质认识得更加清晰,这也是为什么表观遗传这个领域非常有意思。这也是为什么从 Ph.D. 到现在,我一直都在这个领域,就是因为很多很重要的问题没有研究清楚,包括表观遗传是否能遗传。
我的题目是Epigenetic Inheritance and Reprogramming,这其实是表观遗传的两个很重要的特征。我们先看看 epigenetic inheritance,先从 genetic inheritance 开始。

图 2. Genetics 具有很强的 power
这张图片大家可能都比较熟悉了,父母跟小孩的很多性状是比较类似的,但又不完全一样,这里面 genetics 扮演了非常重要的角色。这个例子在同卵双生的双胞胎中就变得更加明显了,她们外表会非常接近(但不完全一样),她们会有一些其他方面的差异,比如性格、习惯等。从这里可以看到,genetics 的 power 是非常大的,它可以影响一个个体很多的性状,但是也有一些东西很难用 genetics 来解释,或者至少我们现在不清楚它是不是由genetics 决定的。

图 3. 是否存在 science 基因呢?
举一个例子,Kornberg 家族是很有名的科学家家族。其中一个叫 Roger Kornberg,他是 2006 年诺贝尔奖化学奖获得者,他做了非常多杰出的工作,其中一个是他发现了核小体是 DNA 包装的基本单元;他还解析了 RNA 聚合酶 II 的结构;他还有很多其他重要的发现,包括 mediator,非常厉害!有意思的是,他的父亲也是个诺贝尔奖获得者,叫 Arthur Kornberg,是 1959 年诺贝尔生理学或医学奖获得者,他发现 DNA 聚合酶 I 。他的兄弟 Tom Kornberg,他没有得诺贝尔奖,但他是 UCSF 的教授,发现了 DNA 聚合酶 II 和 III。Kornberg 家族基本上把转录和复制领域的很重要的这些酶都给找出来了,我们作为 scientist,我们就会想,这里面有没有 inheritance。有没有可能存在 science 基因,从上一代遗传到下一代?
这个其实不光是我们 scientist 每天在想这些事情,你可以问问你的父母,周围的很多家长,包括上海有学区呀什么的,大家都想让自己的小孩变得非常出色。这个问题就来了,我们有什么东西能够传到下一代?或者有什么东西我们不想传到下一代?比如说,父母如果做科研的话,我们有没有 science gene 传到下一代?我们的小孩未来可能就是很杰出的科学家。另外一方面,我们在想,我们可能还可以做一些其他的事情,比如说早教呀,甚至胎教。

图 4. 为了让自己的后代更杰出,我们做的这些有用吗?
有些人会想,我们能不能做一些其他的事情,看看这些事情能不能遗传。比如说我可以尽量不抽烟,可以吃得很健康,这个还是很重要的,现在已经有一些研究表明,父母的饮食有可能影响到下一代的性状。每天锻炼的多一点,身体好一些;经常读一些书,当然作为科研工作者呢,或者是多读一些 papers。这里面一个很重要的问题,到现在为止仍然不是很清楚,does it work?如果我们去做这些事情,哪些东西有可能遗传,哪些东西不可以遗传?或者说,这种遗传机制我们是不是真正清楚?
这些都是一些 open questions。首先回顾 epigenetics——表观遗传。因为我们刚才讲到了,除了 DNA 以外,我们还想做一些其他事情,我们希望也许有一些东西可以对下一代产生一些影响。
表观遗传信息独立于 DNA 的三个经典案例
表观遗传,英文 epigenetics。如果你要仔细看,它是两个词组成的:genetics 前面加了一个 epi。Genetics 大家都知道,表示"遗传学",尤其是以 DNA 为基础的遗传。那么 epi 是什么意思?这个其实是希腊的词根,意思是 over、around、outside,独立于 genetics 之外的东西。所以 epigenetics 的一个相对比较正式的定义呢,就是inheritable information that is not encoded in DNA,这个信息可能是可以遗传的,我觉得这里面需要加一个词"可能是可以遗传的",但是它又不在 DNA 序列里面,那么这种信息我们可以叫做 epigenetics——表观遗传。
在今天的课程中,我主要会 cover 几个部分:首先我会介绍 epigenetic information 的概述,下面我会介绍 epigenetic information 从哪里来的呢?既然它不是从 DNA 来的,它必须是从某些地方来的。接下来,它(表观遗传)是怎么遗传的呢?最后我会介绍,有的时候 epigenetics 跟 genetics 不一样的地方,它可以被 reprogrammed?它是可以变的,一方面它不变(inherited),一方面它又可以变(reprogrammed),这是 epigenetics 非常重要的两个特性。
首先一个问题是,它的一个核心定义是它不是 DNA 里边的,那么我们怎么知道它肯定不是从 DNA 来的?刚开始我们举的那个例子,我们很难界定 Kornberg 家族的性状是不是跟 DNA 相关的。当然我们可以去测他们的基因组,测完之后我们去看看它们之间有没有差别,一般来说,肯定会有一些差别。但是还有一些现象呢,我们比较确定它们应该是独立于 DNA 之外的。
1: Parental information not encoded in DNA

图 5. 80 年代经典的双雄/雌原核实验
这是一个很经典的例子。在 80 年代的时候就发现,精卵结合形成受精卵,在受精卵中把雄原核/雌原核拿掉,换成另外一方,放两个雄原核或两个雌原核,胚胎是发育不下去的。在这个实验中使用的是小鼠,基因组的 background 可以非常纯,可以保证在实验中它的基因组序列基本上是没有变化的,但即使在这样的情况下,用两个雄原核或两个雌原核是不能发育的。只有一个雄原核和一个雌原核才能发育下去,这说明除了 DNA 以外,一定有一些信息可以代表父亲或者母亲,它们知道基因组是从哪里来的。
2: Remembering gene activation and repression
之前遗传学的研究发现在果蝇中有一类对发育重要的基因,叫 Hox 基因,这些基因跟体节的发育相关。在胚胎发育过程中,果蝇存在很多体节。对 Hox 基因来说,在有些体节中表达,有些中不表达。一开始,这种表达或不表达是由转录因子来调控的;但很有意思的是,当胚胎发育到后期的时候,转录因子已经不在了,由原来不表达(Hox 基因)的细胞 derived 来的后代呢,这些基因仍然不表达;表达那些 Hox 基因的细胞 derived 来的细胞,仍然表达。细胞记住了那些基因表达还是不表达,而且是在没有最开始的那些转录因子的情况下。

图 6. 果蝇中细胞可以记住 Hox 基因的表达状态
这个实验当时是做了一个 lacZ 的 reporter,Ubx 是 Hox 基因的启动子,它在这里 drive,这样我们就可以清晰地看到它在那些细胞里表达哪些里面不表达。
3: Animal fate not encoded in DNA
蜜蜂是一种社会性的昆虫,它们是有分工的:有一些是蜂后,它的工作是每天在家里吃好吃的,休息,生蜜蜂;另外,还有一类叫工蜂,顾名思义,是要干活的,每天要出去采蜜。它们的形态和社会分工非常不一样,就像两个物种似的。但是它们出生的时候是一样的,出生后并不知道未来是要变成工蜂还是蜂后。到底是什么决定了它们非常大的命运呢?蜂王浆(royal jelly),看来吃的东西非常重要!如果能吃到蜂王浆,就变成蜂后;吃不到就变成工蜂。

图 7. 对蜜蜂而言,饮食改变命运
在这个例子中,遗传学基本上是一致的,后天的环境、食物、营养不同,对它造成了非常显著的表型的差别。对于蜜蜂来说,all bees are born equal, but after that, it depends on how they are fed.
表观遗传信息的载体
刚才我们看到了这么多现象,在某种程度上是可以遗传的,又有一些记忆,这些东西又不在 DNA 里面,到底在哪里呢?很多信息是从 DNA 的微环境(染色质)里面来的,DNA 不是裸露的,在细胞核里面它有高级结构、包装蛋白,无时不刻处在一个 environment 里面的。在很大程度上,DNA 不能作为一个单独的分子来研究,一定要跟微环境结合起来。这种微环境很多时候是染色质,包括它在核里面的分布,对基因表达是非常重要的。
之前很多研究已经证明了,表观遗传信息很多是化学修饰,包括 DNA 甲基化以及组蛋白修饰,也就是说 DNA 本身或者它的包装蛋白都可以附加一些信息,这些信息是由一些化学修饰来承载的。还有,包括 RNA 也可以作为表观遗传的载体,后面有很多老师来讲 RNA,今天我的课程里面就不会太多的介绍 RNA。我主要介绍 DNA 甲基化和组蛋白修饰这部分。

图 8. DNA 甲基化作为细菌的防御系统
DNA 甲基化最早是在细菌里面作为防御系统出现的。在环境里面,细菌经常受到噬菌体的侵扰,它需要有一套机制来攻击入侵的噬菌体,它就进化出很多限制性内切酶,一旦噬菌体进来以后,就可以把它基因组切碎了,有点像 CRISPR 的意思。但是,这个酶可以切噬菌体的基因组,那么理论上也可以切自己的基因组,杀敌一千,自损八百。DNA 甲基化作为防御机制,把自己的 DNA 用甲基化标记出来,来告诉这个酶,这是我自己的 DNA,不能切。

图 9. 启动子区域 DNA 甲基化的沉默作用
后来伴随着进化的过程,DNA 甲基化有了的新功能,包括基因沉默。一般来说,如果启动子区域被甲基化,这个基因大部分时候是沉默的。为什么被启动子甲基化之后基因就不表达呢?有好几种机制,有的时候它会阻断一些转录因子的结合;有的时候,它可以招募一些甲基化结合蛋白,这种蛋白过来可能会抑制基因。
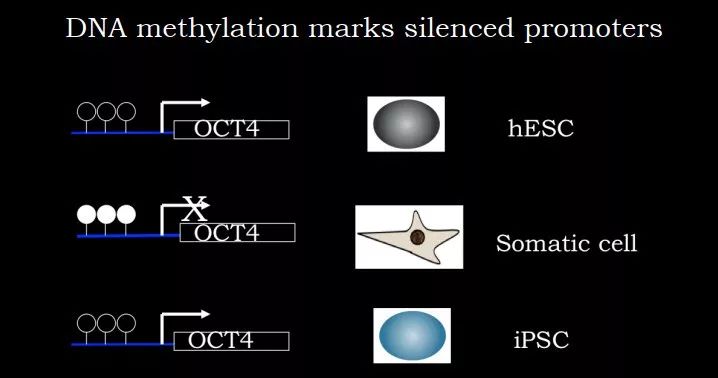
图 10. Oct4启动子区域甲基化与其表达间的 correlation
由于这几种机制,在各种细胞中DNA 甲基化被广泛用作基因沉默的标志。比如 Oct4,在 hESC 中,启动子区域没有甲基化,Oct4 表达;细胞分化后在体细胞中,启动子区域被甲基化,Oct4 不表达;如果用 Yamanaka 因子进行重编程,把它变成 iPSC 细胞后,启动子区域甲基化又会去掉,Oct4 表达。这个案例中启动子甲基化状态与基因表达状态具有很好的 correlation。
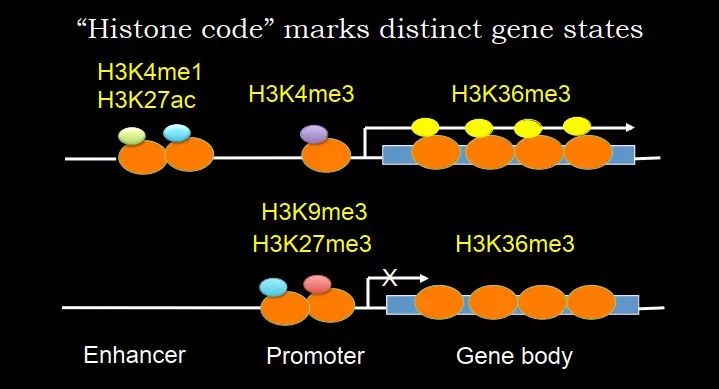
图 11. 组蛋白修饰标记不同的染色质状态
类似地,组蛋白修饰也可以标记不同的基因状态。相比 DNA 甲基化,组蛋白修饰种类更多。如果这个基因转录,启动子区域通常会有 H3K4me3;genebody 会有 H3K36me3;在增强子区域,有 H3K4me1 和 H3K27ac。对于抑制性的基因,启动子区域通常会有 H3K9me3 和 H3K27me3。可以看到,组蛋白修饰和它们的组合能够反映染色质的状态。一方面它们作为 marker,另一方面,它们代表了 DNA 的微环境是不一样的,代表了一种属性。
在人类基因组计划完成之后,epigenome 的主要功能是去注释基因组。当基因组的序列知道后,我们发现我们对它的了解仍然很少。基因组的序列只有一套,但是每个人研究的细胞、组织千差万别,这一套基因组不可能解释我们看到的这么丰富多彩的大千世界。表观基因组的出现,在很大程度上来研究个体、细胞的多样性;在分子水平是什么东西来承载这种多样性?这种信息的遗传和不能遗传正是我们非常希望研究的对象。
表观遗传解释前述三个案例
我们可以回过头来看看我们最开始提到的几个问题。
比如受精卵一定需要一个基因组来自父亲,一个基因组来自母亲,为什么需要这样?这其实是因为基因印记(imprinting)。在基因组里父源和母源的基因组绝大部分是一致的,有不到 100 个区域的 DNA 甲基化不一样。比如母源的基因组是甲基化的,父源的是非甲基化的,虽然同一个核中父源和母源的基因组基本相同,但 DNA 甲基化不一样。这个时候,当修饰不一样时,就会带来表达的差别。比如母源的基因有甲基化,基因沉默;而父源中基因是激活的。因此,如果是两个雌原核,两个基因 copy 都被沉默;如果是两个雄原核,两个基因都表达。正好这些基因都是剂量依赖性的,它们的表达一定要控制在非常精确的范围之内,过高和过低都不行。所以子代的基因组一定要是一个母源的,一个父源的,这样胚胎才可以发育。
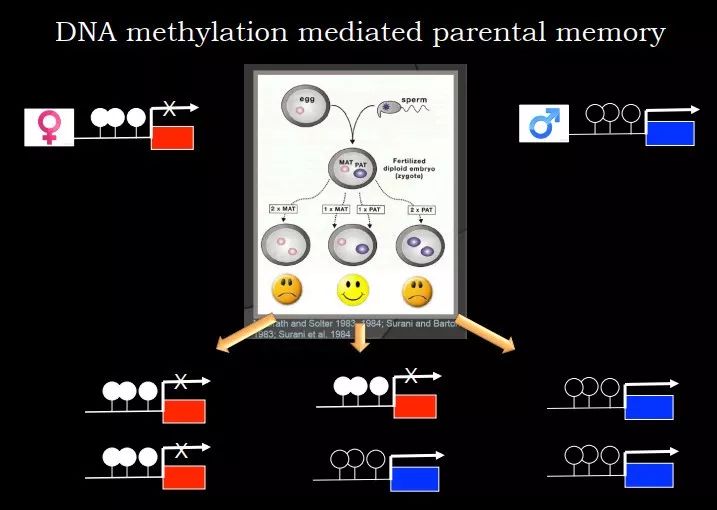
图 12. 印记基因的甲基化决定了子代基因组
需要一个父源一个母源
第二个例子,在果蝇发育中,有些细胞能够记住 Hox 基因的表达状态。这是什么原因呢?在实验中,lacZ 前面是 Hox 基因的启动子 Ubx,Ubx 之前有一些元件,下图 13 中菱形的元件叫 Polycomb response element (PRE),它是来招募 Polycomb 蛋白复合物的。如果我们把 PRE 去掉,细胞就没有记忆能力了,不管之前是表达的还是不表达的,最终所有的子代细胞都表达了,变成了一个 constitutive 的基因。
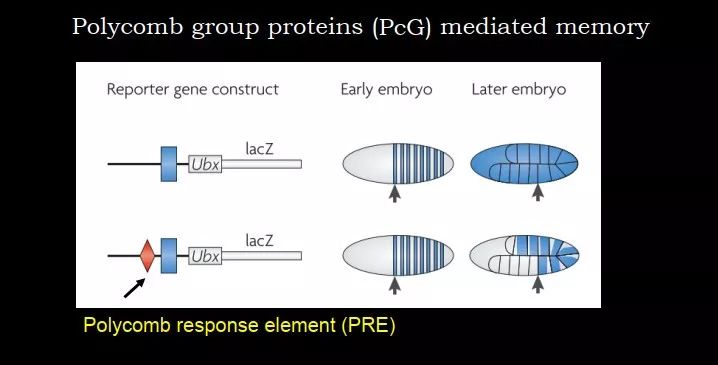
图 13. PRE 对于细胞记忆非常关键
如此说来,PRE 是用来维持这种细胞记忆的。这是如何做到的呢?PRE 可以招募组蛋白修饰酶的复合物 Polycomb,在附近位点进行 H3K27me3 修饰。H3K27me3 是一个抑制性的 mark,可以记住哪些基因被沉默掉的;并且在细胞分裂和分化过程中,有一定的机制可以维持住。这样即使原来的转录因子不表达,它仍然能够知道这个基因是沉默的。
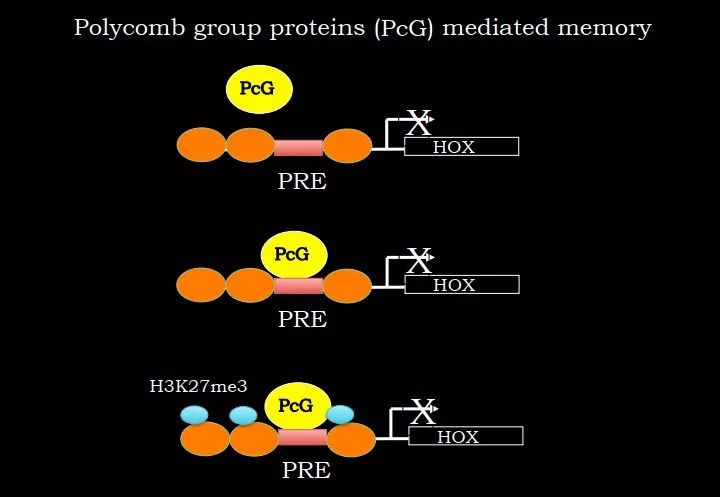
图 14. H3K27me3 参与细胞记忆的维持
第三个例子,蜜蜂命运的问题,为什么有些蜜蜂吃了蜂王浆之后就会变成蜂王呢?蜂王浆里面到底有什么东西?这个现在可能还在研究,蜂王浆不是单一的组分,是很多东西的 mixture。2008 年在 Science 上有一个很有意思的工作,文章发现,如果在蜜蜂的幼虫中敲低 DNA 甲基转移酶DNMT3,基本上不用喂蜂王浆就可以变成蜂后,这个实验证明了,蜂王和蜂后的分工与 DNA 甲基化很有关系的。之前有一些证据说蜂王浆里面有跟 DNA 甲基化反应相关的化学成分。

图 15. DNA 甲基化可能是蜜蜂命运决定的关键因素
小结:表观遗传信息独立于 DNA 之外,而且是可以遗传的;这种信息有的来自 DNA 甲基化,有的来自组蛋白修饰,还有的来自 RNA(这部分我们没有讨论)。当然这个不是 full list,其实可以想象,在 DNA 的微环境里边,任何一种机制,如果它能够承载信息,又有可遗传的机制的话,都可以作为 epigenetics 的一种 mark。当然,现在研究的最多的是 DNA 甲基化、组蛋白修饰和 RNA 等,很有可能还会有其他的 players。
Part 2: 表观遗传信息究竟能否遗传?
表观遗传信息遗传的三种类型
我们接着看一下下面这个问题,当有这些表观遗传信息之后,它到底能不能遗传?这是一个研究了很长时间仍然没有解决的问题,这个取决于你研究的是哪一种分子。
遗传本身其实是分为好几种,很多时候大家会把它们 mix 到一块儿,但其实是不一样的。遗传可以指细胞分裂的过程中 inheritance,叫 mitotic inheritance。当细胞从 1 到 2,2 到 4 的过程中,细胞种类没发生变化,它的 epigenome 是可以遗传到下一代的。
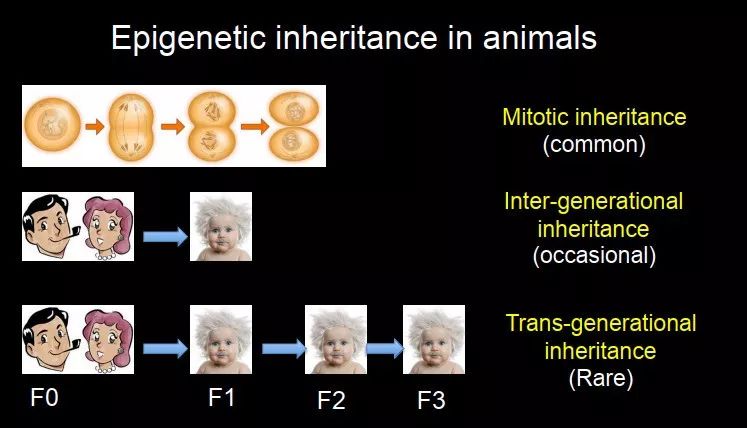
图 16. 表观遗传信息遗传的三种类型
还有从上一代到下一代的,比如说有一些东西遗传到下一代以后,出现了一些性状,这个叫做inter-generational inheritance(通常译为"代际遗传")。还有一种,叫做trans-generational inheritance(通常译为"跨代遗传"),这是指在 F1 代看到了性状,这个是不够的的,很多东西如果要作为遗传的机制和分子,它一定要还能传到下一代去,如果我们在第二代和第三代同样看到了这个现象,这种才叫 trans-generational inheritance。跨代遗传是比较少的;mitotic inheritance 是非常常见的,在细胞分裂和分化过程中都会看到这种现象;代际遗传介于两者之间,有时候能够看到父母获得的性状传递到下一代,但是很多性状再到下一代就不见了,它是不稳定的,并没有到 germline 里面。
每次我们在讨论 epigenetic inheritance 的时候,首先要区分我们到底在讲哪一种?在今天的 lecture 里面,我主要会讲 mitotic inheritance,因为这个比较常见,而且研究的最多;还会讲一部分 inter-generational inheritance,trans-generational inheritance 介绍很少,因为它非常罕见,基本上如果有人发现的话,就会发表在非常好的 paper 上。
为什么 inter-generational inheritance 和 trans-generational inheritance 比较少?这个主要是在动物里面,植物不太一样,植物里面 trans-generational inheritance 还是比较常见的。这里面主要涉及一个现象,动物在发育过程中,会主动地或有意识地把上一代的信息擦掉。从进化的角度,大部分获得的信息、性状,不一定是有利的,比如突变,大部分是中性的,要么是有害的,真正有利于生存的突变其实不是很多。在这种情况下,它可能希望把上一代获得的对自己不太有利的表观遗传修饰去掉。
表观遗传的可遗传性
Epigenetics 有两个很有意思的特征:可遗传(inheritable)、可编程(programmable),就像一个银币的两面。它跟遗传学不太一样,遗传学更多的是强调可遗传性。Inheritable,是要保证它不变;programmable,是它要变。这两种力量一直在打架,在有些时候,我需要 inheritance 非常强,在另外一个时期,我需要它能变,该擦除的时候擦除,该建立的时候建立,一定要控制好这个balance。对于 epigenome 来说,inheritance 和 reprogramming一直都是存在的,就看你研究的系统、细胞、或任何一种状态中最显著的是哪一部分。
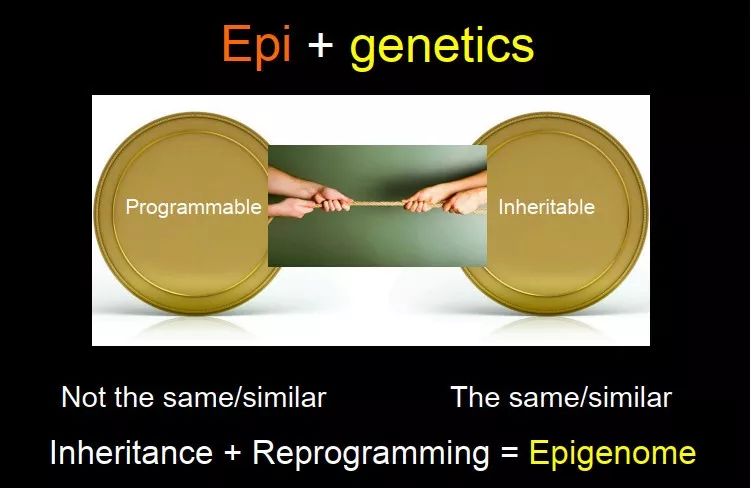
图 17. 可遗传性和可重编程是表观基因组的两大特征
比如受精卵可以发育到细胞 A、B、C,在这个过程中,比较重要的是 reprogramming,需要把全能性的胚胎变成各种各样的组织和细胞,比如心脏、肺、肾等等,在这个过程中,需要改变细胞的命运、功能、状态;当这些细胞都成熟之后,很多时候需要增殖,同样的细胞,只是需要把它扩增出来,细胞变多而已,在这个过程中,发挥的是 epigenome 的 inheritance 的特性,我要保证我产生的细胞不能再变成其他的,如果是心脏细胞,复制后是心脏细胞;肺细胞呢,复制后是肺细胞。Reprogramming 和 inheritance 在不同的阶段发挥不同功能。
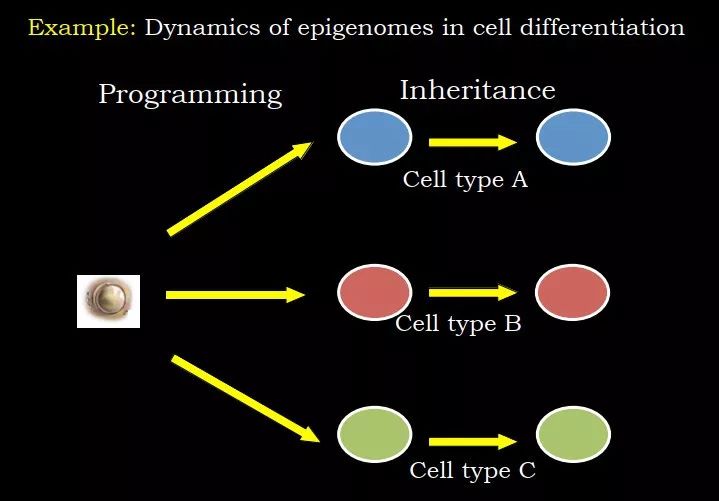
图 18. Reprogramming 和 inheritance 在不同阶段
发挥不同功能
mitotic inheritance 中 DNA 甲基化的遗传
我们首先看一下,有丝分裂中的表观遗传信息的遗传是怎么完成的。从一个细胞复制到两个细胞的时候,DNA 是很容易复制的,但是化学修饰,比如 DNA 甲基化,有没有碱基互补的形式,能够从上一代细胞传递到下一代细胞呢?答案是对有一些是存在的。
DNMT1 介导的 copy-paste
比如说像 DNA 甲基化,它可以进行 copy-paste,这主要依赖于 DNMT1。DNA 在复制过程中,一条链变成两条链,如果原来这个地方有 DNA 甲基化,老的那条链是有甲基化的,而新合成的这条链是没有甲基化的;在复制的过程中,随着复制叉的移动,DNMT1 会去看,当发现原来的链上是有 DNA 甲基化的,就会把新合成的这条链也加上 DNA 甲基化,这样就实现了 DNA 甲基化的 copy-paste。同样的道理,如果原来的 DNA 上是没有甲基化的,DNMT1 发现老的链上没有甲基化,那么 DNMT1 在新合成的链上不会加 DNA 甲基化。
这个看起来就很好,跟 DNA 复制差不多,非常简单,mitotic inheritance 可能就这么完成了。

图 19. DNMT1 介导的 DNA 甲基化的 copy-paste
但是整个 picture 就是这么简单么?当然不是的。有一个很有意思的实验是这样的,这是 2005 年 Rudolf Jaenisch 课题组的一个工作,在细胞中把 DNMT1 敲除,全基因组大概 70~80% 的 DNA 甲基化丢掉,然后把 DNMT1 重新表达回来。如果 DNMT1 只是简单地进行 copy-paste,我们可以预测一下,应该会发生什么:由于原来就没有甲基化,当 DNMT1 进来后,细胞分裂后甲基化仍然没有。但结果其实不是这样的,整个基因组又重新被甲基化了,而且 pattern 又重新恢复。Epigenome can be almost fully restored after eraser。这跟我们所说的记忆在某些程度上就不太一样了,细胞记忆的话是你把 DNA 甲基化去掉后,就没有了;如果恢复了,那就不叫记忆了,它是重新建立的。从这个实验我们其实可以看到,表观遗传的记忆其实没有那么简单,它可以重建。
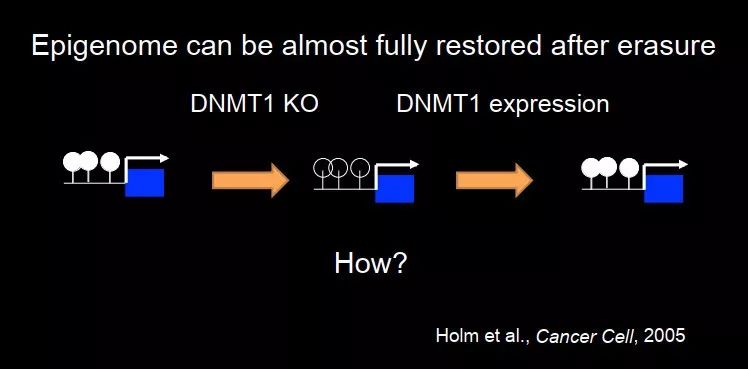
图 20. DNA 甲基化的重新建立
non-CG 甲基化是如何维持的?
还有另一个例子,DNA 甲基化大部分是在 CG 上,CG 的互补链是 GC,从 5' 到 3' 仍然是 CG,正好是对称的结构。但是在某些细胞的基因组里面,比如卵细胞、大脑中有很多 non-CG 甲基化,这种很多时候是在 CA 上,CA 的对面是 GT,对面是没有 C 的,DNMT1 看到 CA 甲基化就很头疼,没有东西可以加甲基化,因此 CA 甲基化是不能被 DNMT1 进行 copy-paste 的。
我们当时也做过实验,取小鼠大脑,父代和子代的大脑中 non-CG 甲基化 pattern 非常像。ES 细胞中 CA 甲基化也是比较多的,细胞传代后,你测前一代和后一代的,很多位点是类似的。那么这种甲基化又是如何维持的?
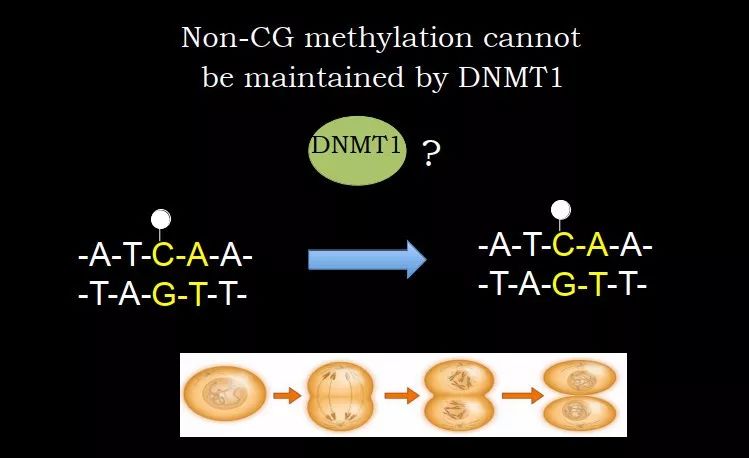
图 21. non-CG 甲基化 pattern 的维持
从以上这些结果来看,不光是 DNMT1 介导的 DNA 甲基化模式的 copy-paste。回到刚才的实验,DNMT1 敲低后 DNA 甲基化下降;DNMT1 回复后,DNA 甲基化水平又能回到原来的水平。这到底是为什么呢?
首先,DNA 甲基化又重新回来了,说明有其他的方式,加了新的 DNA 甲基化,这就要提到DNA甲基化的从头甲基化转移酶(De novo DNMTs)。在哺乳动物中,DNMT3A 和 DNMT3B 是两个最重要的从头甲基化酶,它不需要像 DNMT1 那样 copy-paste,在没有甲基化的地方就可以把甲基化加上来。那么在上述实验中,DNMT3A 和 DNMT3B 肯定是发挥作用的。
过去几年大家研究了很多 DNA 去甲基化酶。在哺乳动物细胞中,去甲基化酶也是在表达的,比如像 TET 家族蛋白——过去几年在 DNA 甲基化领域最大的发现之一。TET1/2/3 是 DNA 甲基化的氧化酶,可以把甲基化的 5mC 变成 5hmC、5fC、5caC,这些氧化产物又可以通过其他途径去掉,最终变成 C。
在细胞中甲基转移酶和去甲基化酶都是在表达的,这又是一种平衡。任何一个细胞的甲基化状态,存在于甲基转移酶和去甲基化酶的大环境中。那么问题来了,DNA 甲基化看起来是一个很动态的过程,如果想恢复原来的 epigenome,有些酶在那里去除甲基化,有些又在那里加,最后又怎么能恢复 epigenome?
组蛋白修饰介导的 DNA 甲基化恢复机制
在细胞中,很多都是动态变化的过程,在不同酶的作用下,仍然能够保证有些基因的启动子区域没有甲基化,有些是有甲基化的,这里边有很多原因,我在这里举一两个例子,这个是跟组蛋白修饰是有关系的。
比如对于转录的基因,启动子区域和 genebody 有不同的组蛋白修饰,这些修饰一方面可作为 marker;另一方面,它们的存在是有功能的,在发挥功能的过程中大家把它用作 signature。
H3K4me3 的存在可以很好地保证基因启动子区域不被 DNA 甲基化。对于 DNMT3A/3B 很重要的 co-factor DNMT3L 无法结合到 H3K4me3 附近的 DNA 上,DNMT3A/3B 就不能过来,即存在一种 active 的机制保证启动子区域不被甲基化。在 genebody 上有 H3K36me3,可以招募 DNMT3B。DNMT3B 里面有一个 domian,可以特异性结合 H3K36me3。最后就形成了一个非常有意思的 pattern,启动子区域没有甲基化,genebody 有甲基化。
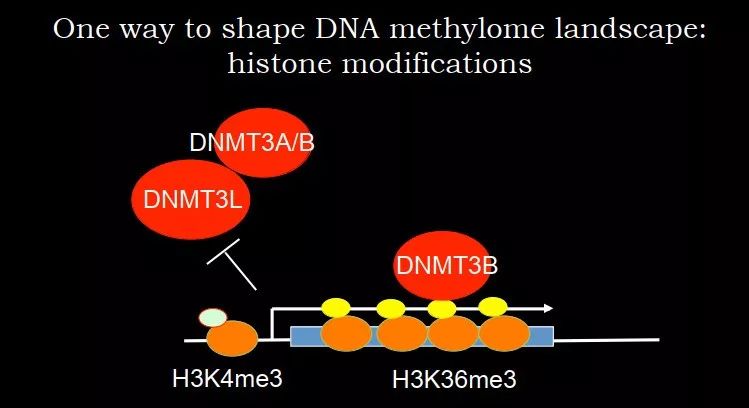
图 22. H3K4me3 和 H3K36me3 介导的
DNA 甲基化 pattern 形成
哺乳动物细胞全基因大部分地方都是甲基化的,包括转录的和没有转录的地方,没有甲基化的地方一般是在启动子区域和增强子区域。对于其他物种,比如植物,或者很特殊的哺乳动物细胞,比如卵细胞,会看到很明显的 genebody 的甲基化。一个基因是转录的,你会看到它的 genebody 是 fully methylated,它旁边的地方是没有甲基化的。通常在卵子和植物里面,有 DNA 甲基化的地方是转录的地方。
上面的例子提示,组蛋白修饰可以在某种程度上告诉 DNMT,DNA 甲基化的机器应该在什么地方工作,不应该在什么地方加,这样的话原来的 pattern 就可以保留下来。很多时候不能认为是被 copy 下来了,更像是一种 active maintanance,这个地方一直在动态地维持一个 pattern,这个 pattern 跟原来的是一致的,但又没有通过 DNMT1 介导的 copy paste 机制。
这里面又有一个问题,为什么组蛋白修饰还在这个地方?组蛋白修饰怎么知道我应该去哪里?组蛋白修饰也要经过细胞分裂,也要经过 DNA 的复制,组蛋白修饰是怎么维持它们的 pattern 的?
mitotic inheritance 中组蛋白修饰的遗传
相比于 DNA 甲基化,组蛋白修饰的遗传了解的相对没有那么清楚,取决于是哪一种组蛋白修饰,组蛋白修饰之间还不太一样。对于绝大多数的组蛋白修饰来说,copy-paste 机制还没有找到。但是对于亲代细胞和子代细胞而言,组蛋白修饰的 pattern 非常类似,这又是怎么形成的呢?
中科院生物物理所的朱冰老师在这方面做了很多非常出色的工作,这是 2012 年他们实验室发表的工作,他们研究 DNA 复制后组蛋白修饰是怎么加上去的,他们研究了四种修饰 H3K9me0/1/2/3。在这个实验中,把新加上来的做了标记,在复制之后能区分新的组蛋白和旧的组蛋白。
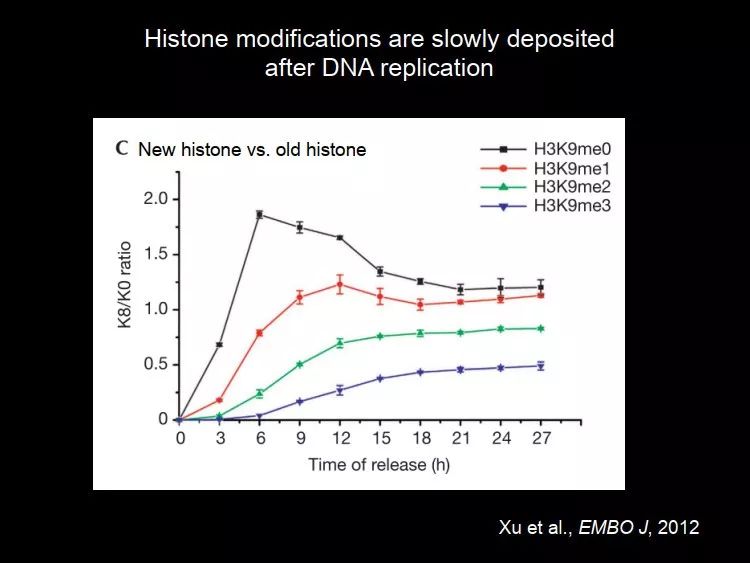
图 23. DNA 复制过程中新旧组蛋白中
H3K9me0/1/2/3 的动态变化
在图中我们可以看到,在 DNA 复制过程中,新的组蛋白 H3K9me0 逐渐上来,H3K9me0 上升的是比较快的;但是 H3K9me1/2/3 上升得很慢。这个实验在某种程度上已经证明了它不是 copy-paste 的机制。如果是 copy-paste,那么在 DNA 复制后很短的时间,H3K9me1/2/3 水平就会上来。
从这个实验我们可以看到,组蛋白修饰跟 DNA 甲基化不太一样。在复制过程中, H3K9me1/2/3 是一点一点加上来的。还有一些修饰,可能会更快一点。如果组蛋白修饰是一点一点加上来的,怎么能够维持原来的 pattern?如何知道哪些地方该加,哪些地方不该加?
朱冰老师在这方面有进一步的研究,比如 2016 年他们在 Gene & Dev 上的工作,解释了为什么知道在哪些地方加,哪些地方不加。H3K9me1 的催化酶是 G9A/GLP,在体外组装一些核小体,可以控制核小体上有没有修饰。如果一开始放的是没有修饰的组蛋白,加入 G9A/GLP,其活性是比较差的,H3K9me1 水平很低;如果放的是有一点组蛋白修饰的组蛋白,形成的组蛋白是有些位点有修饰,有些位点没有,再加入 G9A/GLP,发现其活性很强,大部分新的组蛋白上都加了 H3K9me1。
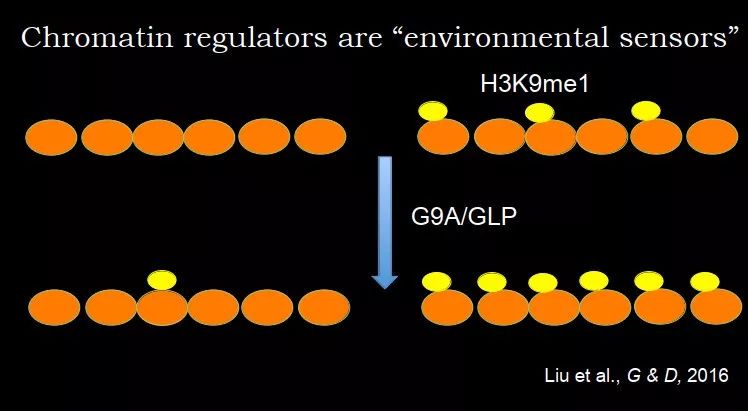
图 24. 细胞分裂中 H3K9me1 的遗传机制
这个实验在某种程度上,能够提供一种解释,组蛋白修饰的选择性,通过看原来组蛋白修饰有多少:当它水平比较高,就继续加;如果原来很低,就不加了,这其实就是一种记忆。当组蛋白修饰在 DNA 复制后,被稀释后还有些残留,利用这些残留的组蛋白修饰,再把整个表观基因组重现出来。
除了 H3K9me1,H3K27me3 也存在非常类似的机制。H3K27me3 是一种抑制性的组蛋白修饰,尤其是对发育相关基因(比如 Hox 基因)的抑制是很重要的。PRC2 复合物中就有 EZH2,负责催化 H3K27me3;还有一个亚基叫 EED,是复合物的重要组成部分。EED 可以识别 H3K27me3,利用 EZH2 把邻近的位点继续加上 H3K27me3,这又是一个正反馈的机制。当细胞复制后,只有细胞能够残留一部分 H3K27me3,PCR2 过来,在细胞周期中就可以把 H3K27me3 加到一定的水平。
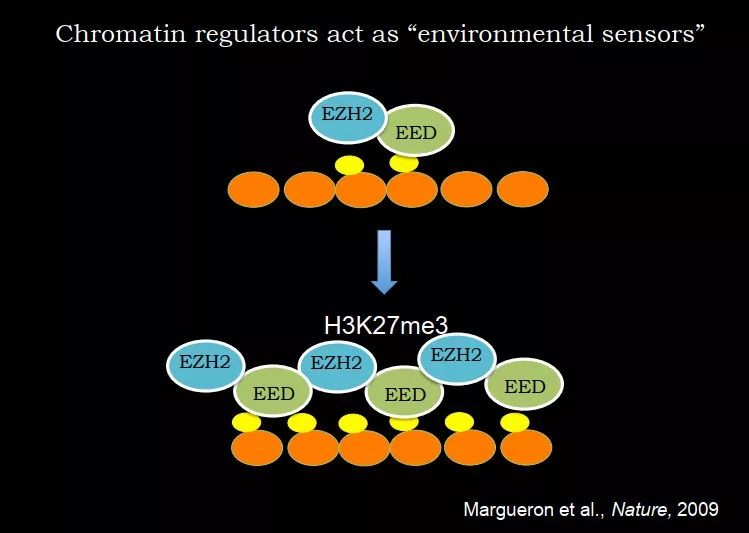
图 25. 细胞分裂中 H3K27me3 的遗传机制
如果把这个过程总结到一个 model 里面,在一定程度上可以解释组蛋白修饰的遗传问题:在 DNA 复制前,有老的组蛋白,上面存在各种各样的修饰;DNA 复制后,变成两个 copy,不可避免地很多组蛋白修饰被稀释掉,稀释的过程并不一定非常精确,稀释后有的地方的组蛋白稍微多一点,有的地方稍微少一点,但总体是下降的,新的组蛋白进来,上面的修饰相对较少;因为有了老的修饰,就可以在它们附近加修饰,新的组蛋白上面的修饰越来越多;细胞周期继续,修饰水平更高。这是组蛋白修饰遗传中比较普遍的机制——正反馈机制。

图 26. 细胞周期中组蛋白修饰遗传的正反馈机制
Epigenome 很有意思,有点像生态系统(ecosystem),它里面有 DNA 甲基化、组蛋白修饰等,它们之间有 crosstalk,可以相互影响。在某种程度,就是这样的 ecosystem 在维持 epigenome 的稳定,远比 DNMT1 依赖的 inheritance 要复杂得多。如果一个系统的稳定依赖于一个因子,当这个因子出现问题时,细胞就很危险了。但如果它是一个系统,尤其是其中组分有相互作用的 ecosystem 的时候,就会相对稳定,能够承受很多外界的扰动,可以保证大致的平衡。
细胞周期中染色质高级结构的遗传
这里还有一个很有意思的问题,除了 DNA 甲基化和组蛋白修饰,染色体还有高级结构。染色体是三维的,目前大部分研究一维和二维,对三维的了解非常少。染色质的三维结构可以遗传嘛?在显微镜下看细胞,亲代细胞和子代细胞,它们的 staining 和结构很多时候是差不多的;不同的细胞染色就不太一样。染色体的高级结构可以传递到子代细胞中吗?
最近几年,随着 3C 技术的发展,发现了染色体的高级结构的基本单元,包括 TAD(Topologically associating domain)以及 A/B compartments(几个 TAD 聚集到一块儿组成),这种 compartments 在空间上有固定的区域,有一种 compartment 主要在核膜附近,还有一种 compartment 在核中心,有一种比较 active,有一种是抑制性的;比 TAD 更小的结构包括 promoter-enhancer loops,增强子和启动子可以在空间上结合进而启动基因。
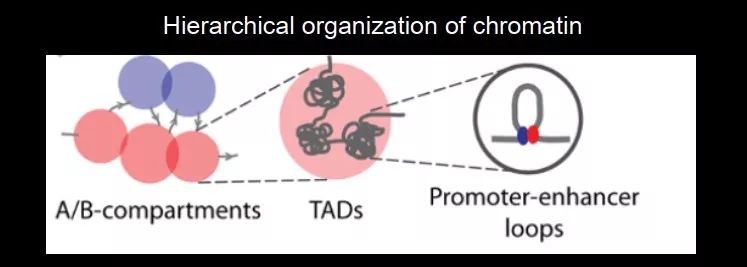
图 27. 染色质的三种结构
其中 TAD 是通过染色质的相互作用 define 出来的大的 domain,尺寸一般在兆 bp,而且 TAD 在不同物种中比较保守,是染色体的基本框架,不容易被破坏。像这种高级结构在细胞分裂中是否还在?
2013 年美国马萨诸塞大学医学院 Job Dekker 实验室的一篇 Science 回答了这个问题,把细胞阻滞到不同的周期,对 G1、S、M 期和非同步化的细胞做 Hi-C,研究不同时期的染色质的结构。
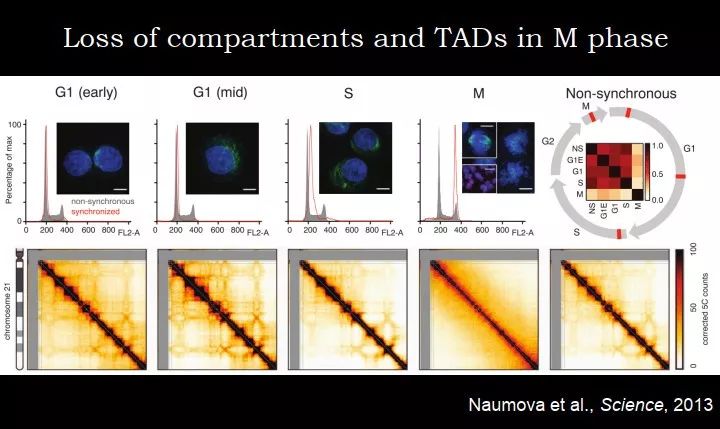
图 28. 细胞周期中 TAD 的动态变化
上图为染色质相互作用的热图,代表了两个染色质位点相互作用的强度。总体而言,如果看到一个类似格子的形状,说明这里存在固定的结构,这个结构决定了某些区域之间存在相互作用。对比 G1(early)细胞和非同步化的细胞,pattern 差不多,强度有差别;G1(mid)和 S 期也类似,跟非同步化的细胞的 pattern 相似。在 M 期,跟其他的所有时期都非常不一样。在 M 期,TAD、compartment 都不见了。
在 M 期,染色体要分开的时候,高级结构不见了;但是我们不能说它没有结构,它其实有自己独特的结构。如果在显微镜下观察 M 期的细胞,它非常 condense,染色会很亮,从细胞水平,我们之前就知道,M 期是不一样的,但这个实验第一次在分子水平证明 M 期很不一样,有自己很特殊的结构,原来的高级结构没有了。

图 29. 细胞周期中染色质高级结构的动态变化
细胞中具有 A/B-compartments、TAD、promoter-enhancer loops,经历 S 期,这些结构大体都还在;到 G2 期,由于 M 期不转录,很多转录因子和聚合酶剥离,染色体开始压缩折叠,变成了 linearly compressed stochastic loop array,有点像圆柱体,里面有很固定的折叠。在上面的 M 期的热图中,可以看到非常清晰的边界,染色体上每一个地方能够触及到的染色体另外一点的距离是固定的,它的结构是非常有意思的圆柱状,但是里面丧失了常见的高级结构。在 M 期,非常 condense;出了 M 期,就 decondense,重新形成 promoter-enhancer loops、TADs、compartments。
我们刚才看到了很多例子,这些例子都在指向一件事情,epigenome 的遗传在很多时候是非常动态的,称之为 dynamic stability。有点像崎岖不定的道路上开车,利用各种各样的机制,保证车身大体平衡;又像不倒翁,可以给外界的扰动,只要这种扰动没有强到把它翻倒或者破坏,就可以 bounce back,保证细胞状态处于相对稳定。任何一个细胞、个体与外界环境不断地在进行 interact。
小结:epigenetics inheritance 有很多机制来保证稳定,一种是 DNMT1 介导的直接的 copy-paste,这是最经典的、研究的最清楚的、最简单的机制;在这个基础上,一些表观因子不能马上把修饰 copy 过来,但是能够感知 local environment;最终把所有因素结合起来,会产生一个比较稳定的 ecosystem。
Part 3: 表观遗传的重编程
表观重编程的两种策略:提供驱动力+清除障碍
如果 epigenome 这么稳定,还怎么 reprogram?
我们刚才提到了 epigenome 的两个特性:inheritable 和 reprogramming。我们需要它变的时候,它要能够变。我们可以看一下经典的 Waddington's epigenetic landscape 的图,每个细胞分化到特定的谱系后,稳定地在山谷里,其实不是一直不动,可以来回晃,但是晃完了还得回去。但如果我们想让它晃出来,这个应该怎么做?这就是 reprogramming,把它的状态和命运都改变了。
这很像重力,为什么会回去呢,因为有一个相对稳定的力在 drive 它回去。如果要出来,需要克服重力。如何克服重力呢?比如发射火箭的时候,有两种方法:一种是提供驱动器;另一种是放到另外的星球上,没有重力,或者重力很低。我们想要 reprogram 细胞的时候很类似,第一我们得提供驱动力,比如 iPSC 中的 Yamanaka 因子,这四种因子的驱动力足够高,让一小部分细胞从成纤维细胞回到iPSC。

图 30. Yamanaka 因子提供细胞重编程的驱动力
但即使这个过程完成了,效率依然很低,提示有一些表观遗传的障碍。这里有一个例子,来自哈佛大学张毅教授的很漂亮的工作,他做的是体细胞核移植(SCNT),把表皮细胞的核放到卵子里,从成熟的体细胞变成多潜能性或全能性细胞。这个过程的效率非常低,胚胎发育到囊胚的概率很低。
为什么效率很低,卵子里面已经提供了大量的转录因子。受精具有很强大的 reprogram 能力,可能比 Yamanaka 的四个因子的作用更强,因为普通的受精的效率很高的。当我们提供了足够的推动力的时候,为什么效率还这么低?可能是组蛋白修饰,比如 H3K9me3,它的催化酶是 Suv39h。在正常的 SCNT 中,检测哪些基因应该被激活而没有被激活,结果发现很多基因有 H3K9me3 标记,因此推测可能是 H3K9me3 阻断了 reprogramming。于是在 SCNT 中过表达 H3K9me3 的去甲基化酶 Kdm4d,效率非常显著地提高,我印象中,发育到囊胚阶段的效率从 20~30% 提升到 90% 左右。
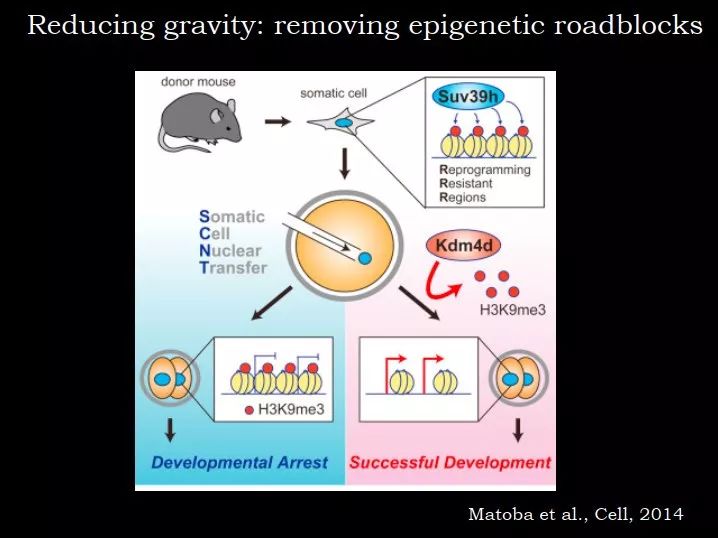
图 31. H3K9me3 是体细胞重编程的关键障碍
H3K9me3 是唯一重要的因子嘛?虽然有 90% 的细胞可以发育到囊胚,但是再往下,小鼠出生的概率依然比正常生理情况要低,其实这个 reprogramming 没有完成。但是这个案例很清楚地显示,表观遗传是一个障碍;如果在提供转录因子的同时,如果能把障碍去掉,reprogramming 的效率会显著提高。
早期胚胎发育过程中 DNA 甲基化的重编程
接下来我们主要介绍 reprogramming,最显著的 reprogramming 事件发生在早期胚胎发育过程中。在分化的过程中,一部分细胞要变成原始生殖细胞(primordial germ cell,PGC),是精子和卵子的前体;PGC 进一步发育变成精子和卵子;它们结合后变成受精卵。Reprogramming 和有丝分裂过程很不一样,在有丝分裂过程中,细胞类型是不改变的。而在精子和卵子形成过程中,细胞形态、功能发生非常大的变化。
在受精后同样会经历很显著的 reprogramming。精子和卵子是非常特化的两类细胞。精子的染色体高度浓缩,最主要的功能是游得快,轻装上阵,超越几亿的兄弟。为了保证轻装上阵,连组蛋白都不要,用的是鱼精蛋白,可以帮助染色质更好地折叠。组蛋白还剩了一点,保留了不到 5%;基本上不转录,fully ready,一声令下就跑。卵子也很特殊,虽然卵子不用拼命地游。卵子,尤其是准备受精的,其染色体是被阻滞到 M 期,一直在这待着,可以在这个时期待很长时间,因为女性的卵子可以在体内存活几十年。它也是基本上不转录的,但是在达到成熟之前做了大量的准备,储备了大量的 RNA 和蛋白。之后它们俩开始受精了,变成受精卵。
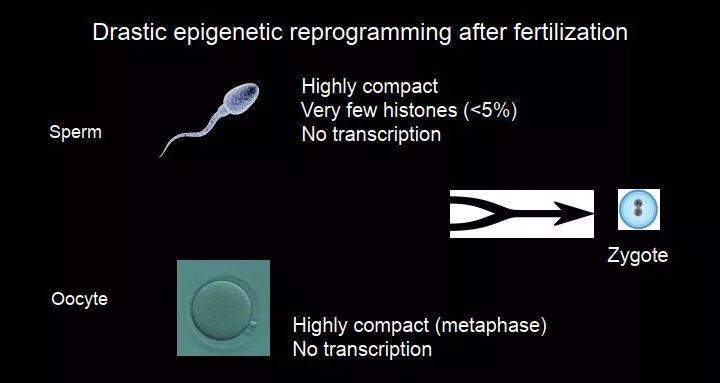
图 32. 精子和卵子是两种高度特化的细胞
哺乳动物中,把亲代的表观遗传信息去掉很重要。在哺乳动物发育过程中,DNA 甲基化经历了两次去除,一次可能还不够,最彻底的一次是在形成 PGC 的过程。
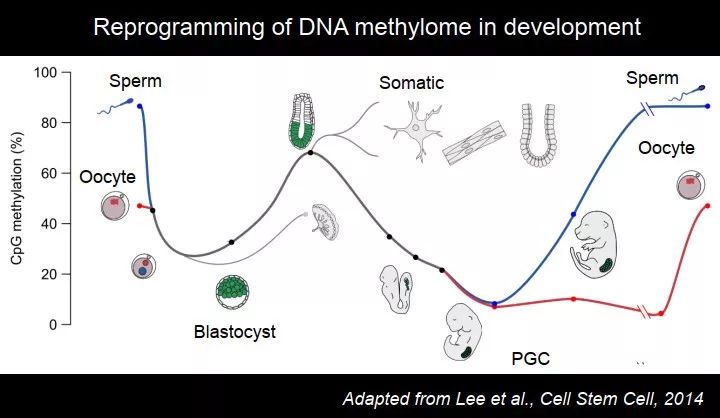
图 33. 小鼠早期胚胎发育过程中 DNA 甲基化的重编程
在体细胞中,DNA 甲基化是比较高的;在早期胚胎中,大约第 6.5 天时,一部分细胞朝着生殖细胞的方向走,剩下的都变成了体细胞;在特化为生殖细胞的过程中,DNA 甲基化一路下降。在小鼠里面,胚胎期 13.5 天的时候,DNA 甲基化非常低了。你要去看基因组里面的,基本上是没有了,除了一些重复序列区域。因为在个体里面,有一些重复序列仍然是活跃的,大部分被沉默掉,或者突变掉,已经失去功能,但是还有一些重复序列,可以跑来跑去(jump and run)。重复序列的抑制很多跟 DNA 甲基化相关,所以在这个时候,会保留一些 DNA 甲基化,主要在重复序列区域。有一些研究发现,不光 DNA 甲基化,组蛋白修饰也挪到那个地方,确保这些重复序列是不表达的。
再往后,形成精子和卵子,它们的形成过程不一样,有各自的特征。精子甲基化水平相对高一些,卵子的相对低一点,卵子的甲基化水平是在小鼠出生后才形成的,精子要早一点。有了 DNA 甲基化之后,受精之后又会经历第二次去甲基化过程,没有第一次这么彻底,保留了一部分 DNA 甲基化,大约 30%,这些保留的 DNA 甲基化到底有没有功能?现在有一些证据,稍后会提到。
这是 DNA 甲基化的重编程,染色体,包括组蛋白修饰,在整个发育过程中尤其是受精后是什么样子,现在仍然不是很清楚,主要受实验技术的限制。
染色质开放状态的重编程
我们实验室研究了早期胚胎发育过程中染色体是怎么重编程的,跟哈佛张毅实验室同时期发表,他们在 Cell 上,我们在 Nature 上。我们在这两个研究中,研究的对象是可及性染色质(accessible chromatin),也即开放染色质,我们希望探索受精后开放染色质状态的变化。

图 34. 早期胚胎发育过程中开放染色质的 landscape 研究
为什么研究开放染色质呢?一个很简单的原因,如果一个基因要表达,它的启动子区域首先需要打开,转录机器和转录因子才可以进来。不光是启动子,它的增强子区域也有很多转录因子需要进来,来启动基因表达。如果我们能够看到染色质开放状态,就可以推测基因组的状态、基因转录的活性。

图 35. 开放染色质可以反映转录活性
在这个过程中,研究是比较困难的,主要是因为材料比较稀少。在这个实验中,使用了 ATAC-seq(Assay for Transposase-Accessible Chromatin using sequencing),原理是这样的,用 Tn5 转座酶去攻击(attack)染色质,转座酶可以切割 DNA,如果这个地方是打开的,那么它就可以进去把它切断。这个酶做过一些工程化,这个酶不光可以切,还可以连接用于测序的 adaptor,把测序的 adaptor 在一步反应里加上去。这样的话,这个实验只需要两步:第一步,拿 Tn5 去切;第二步,PCR 就结束了。

图 36. 用 ATAC-seq 研究染色质开放状态
这个技术是 2013 年的时候斯坦福大学的 William Greenleaf 和 Howard Chang 实验室开发出来的。它的好处是实验很简单,大概半天时间就做完了,而且它需要的材料就比 FIARE-seq 和 DNase-seq 少好几个数量级,大概 500 个细胞就可以做这个实验了。
当这个技术发明后,我们就非常 excited,终于有一个技术可以研究染色质的 reprogramming 了。我们就用它来研究胚胎发育,当时做了二细胞、四细胞、八细胞、囊胚。精子卵子其实我们也做了,但是信号比较弱,因为那两个细胞那两种状态是不转录的,我们猜它们的 open chromatin 比较 weak。
我们收集了细胞做了 ATAC-Seq,中间还有很多技术上的细节,包括卵子里面有大量的线粒体 DNA,我们用了一些很有意思的方法把它去掉。在解决了这样一个技术问题后,我们就可以看到受精之后染色体的状态究竟是一个什么样子。我们当时做了二细胞、四细胞、八细胞和 ICM(囊胚时期拿出来的内细胞团)。peak 代表开放染色质,有很多在启动子区域,最下边是 ES 细胞的开放染色质的状态。在二、四、八细胞期,有些位点的开放染色质跟胚胎干细胞很像,有些是不一样的。总体来看,染色体状态跟胚胎干细胞是很不一样的。
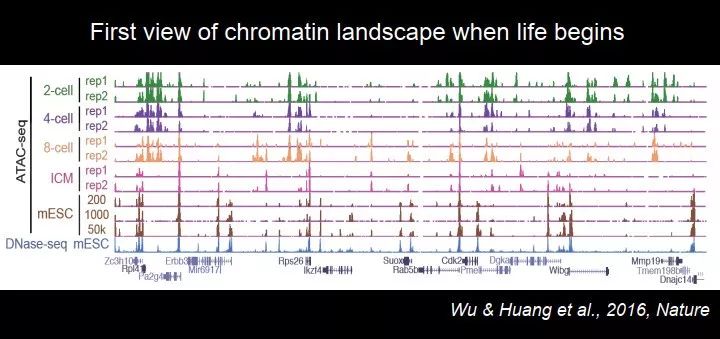
图 37. 早期胚胎发育过程中开放染色质图谱
我们想回答的一个问题是,精子和卵子的染色体的差别很大,这种差别在什么时候就变得类似了呢?我们发现到二细胞的时候,图 38 中这个绿色的就是 biallelic 开放染色质,两套染色体的开放染色质很快就变得非常类似了,这个重编程的效率非常高。
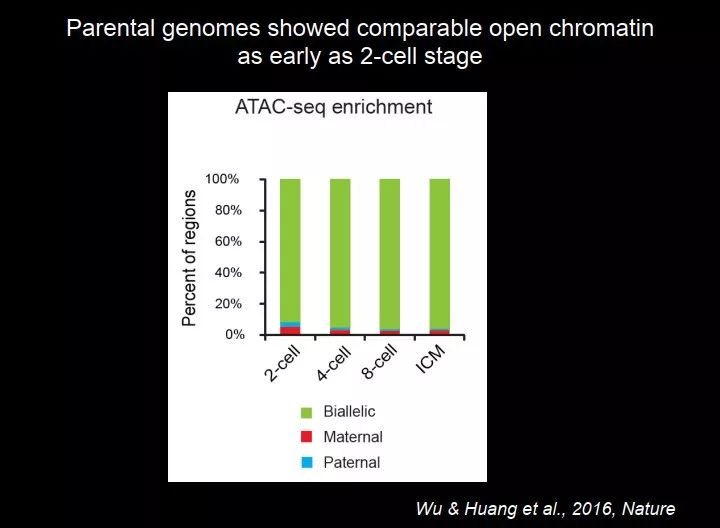
图 38. 在二细胞期雌雄原核的开放染色质就很类似
然后我们还想看看早期胚胎跟后面的 stage 有什么差别,我们发现,基因的启动子区域一般会有开放染色质,这个大家都是知道的;但是我们发现,在二细胞、四细胞、八细胞,转录终止位点也有开放染色质;而再稍晚一点,比如 ICM 和 ES 细胞中就很弱了。
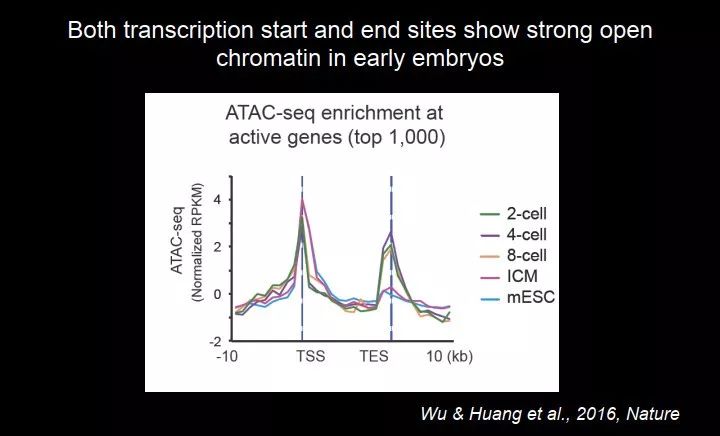
图 39. 转录起始位点和转录终止位点都出现开放染色质
由于一些原因,早期胚胎转录开始和转录终止位点,都是有开放染色质的,我们不是很清楚它到底具有一个什么功能。在合子(一细胞)的时候,有人证明过它的转录很不稳定,该终止的地方不终止,这个叫 minor ZGA,在一细胞时期大部分基因是沉默的,有一些基因是转录的,尤其一些重复序列。这种转录是杂乱的(promiscuous),很难终止,一开始转录就一直往下走,停不下来,它经常会转录到另一个基因那里去。我们猜,也许在转录终止位点需要有一些重要的因子,保证它转录要停下来。当然那个是在一细胞期,我们这个是在二细胞期。
在重编程过程中,很重要的一点是转录因子,转录因子推动细胞从一个状态到另一个状态。在早期胚胎发育过程中,哪些因子比较重要呢?当然,我们可以做遗传学,可以猜某个基因,然后敲除或敲低;但是我要是不知道呢?这个时候,开放染色质有它独特的优势。
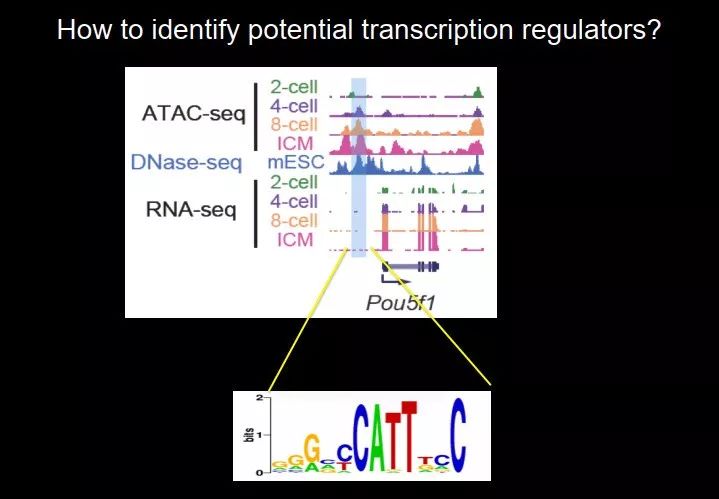
图 40. 鉴定开放染色质中潜在的转录因子结合位点
增强子区域呈现出开放染色质,有很多转录因子结合,现在不知道是哪个转录因子进来,但是可以看序列,因为序列里面通常会含有转录因子的结合位点。比如 Oct4,它开始转录了,我们发现在启动子上游有开放染色质;去看这一段序列有什么 motif,就知道转录因子在不在这个地方。这样我们把所有的开放染色质中的 motif 都看一遍,看在哪一个时期哪一个转录因子的 motif 富集得最多。
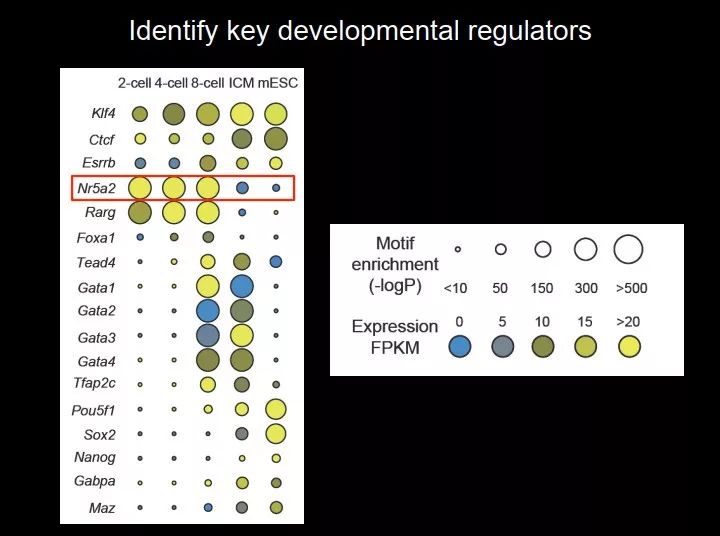
图 41. 鉴定发育过程中关键的调控因子
于是我们做了这样一个工作,我们把二细胞、四细胞、八细胞、ICM 和 mESC 都看了一遍。上图中左侧是各种转录因子,圆圈的大小表示 motif 在全基因组开放染色质中富集程度,圆圈越大,说明富集越多;颜色表示转录因子的表达水平,黄色表示表达比较高,蓝色代表表达比较低;这样我们看到,有些转录因子富集比较多,表达也很高。而且可以看到,在不同的时期使用的转录因子不一样。二细胞和四细胞所需要的转录因子比较接近,八细胞出现一个过渡态,此后,图中上面的一些转录因子(比如 Nr5a2、Rarg)不再用,在 ICM 时期,多了下面的一些转录因子(比如 Gata1、Gata2、Gata3、Gata4);从 ICM 到 mESC,Pou5f1 和 Sox2 又多出来了。Oct4、Sox2、Nanog 只在 ICM 和 ES 细胞里面比较富集,早期是没有的,而且这个跟它们的表达也是非常相关的。
胚胎发育的特别早期很少人研究,我们想知道这个时期哪些因子比较重要。随后我们聚焦到 Nr5a2,它在二细胞到八细胞比较富集。八细胞的时候有一个特殊的细胞事件——第一次细胞命运决定,决定是分化到 ICM 还是滋养外胚层(trophectoderm,TE)。ICM 最终是要发育成胚胎的,TE 最后发育成滋养层,提供营养的作用。八细胞的时候还没有分化,最终分化为 ICM 还是 TE 主要取决于它在胚胎的里面还是外面,因为它是一个球,但是八细胞你是没办法看出来哪个在里面,哪个在外面,它是一个立方体。
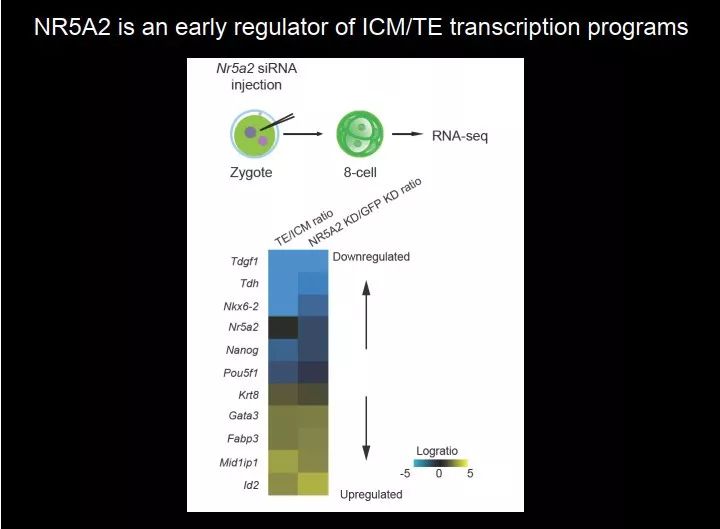
图 42. Nr5a2 是 ICM/TE 转录程序的早期调控因子
我们在想有没有可能在八细胞的时候,它就开始做准备工作了?所以我们做了这样一个实验:我们在胚胎里注射了 Nr5a2 的 siRNA 将它敲低,在八细胞期收胚胎做 RNA-seq,非常有意思,我们看到把 Nr5a2 敲低以后,图中上面是 ICM 的 maker 基因,表达下调;图下面是 TE 的 marker 基因,表达上调。最后我们发现,Nr5a2 是一个早期的调控因子,在八细胞的时候就开始调节 ICM 特异性的转录,到十六细胞、三十二细胞的时候就可以开始往下分化了。
总体而言,我们如何做表观重编程呢?首先,我们要有合适的转录因子来驱动它,来 drive 细胞 jump out。在这个过程中,我们如果能够找到是哪些表观因子在阻断细胞命运的转换,如果可以把这些 roadblock 去掉,我们就可以进一步提高它的效率。这个就是表观重编程。
表观遗传重编程中的"漏网之鱼"
印记基因 DNA 甲基化的遗传
前面我们讲了很多,重编程就是将表观遗传信息去掉,有没有一些信息仍然可以从上一代传递到下一代?当然,这样的案例是有的。经典的,最简单的就是我们刚才提到的基因印记。我们说过,基因组中有不到 100 个区域,父源和母源基因组的甲基化是不一样的,只在其中一方有甲基化。
受精后 DNA 甲基化下降,但印记区域 DNA 甲基化维持地非常好,到体细胞中也是维持地很好的,但如果走 PGC 这个路线,它是被去掉的,也就是说在这两个去甲基化的过程中,它只在一个过程里面被去掉,在另一个过程里面维持稳定,至少在受精过程中,它是从上一代到下一代中的甲基化的 mark。
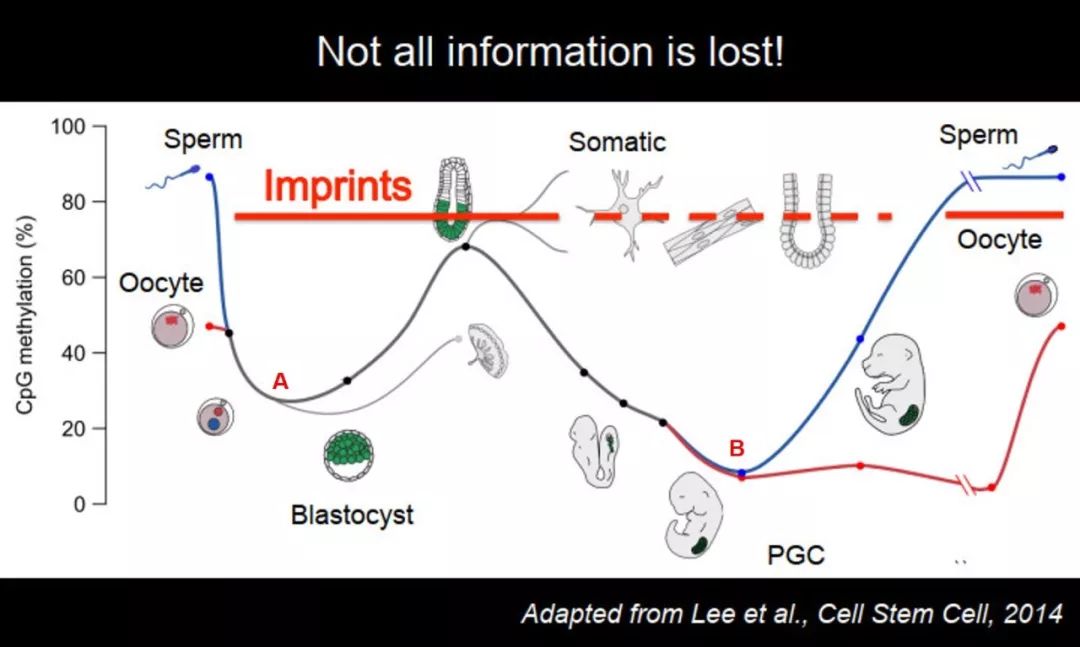
图 43. 部分印记基因 DNA 甲基化保留
基因组印记非常特殊,如果回到刚才我们那个例子,如果我们把细胞的 DNMT1 敲除,然后把 DNMT1 表达回来,可以重建 epigenome。但这里面很重要的一点是,基因组印记丢了。对于基因组印记,一边是甲基化的,一边没有,如果把 DNMT1 去掉,两边都没有;再把 DNMT1 放回来,仍然没有办法恢复。所以基因组印记是很特殊的一些类型,丢了就丢了,再也没有了。
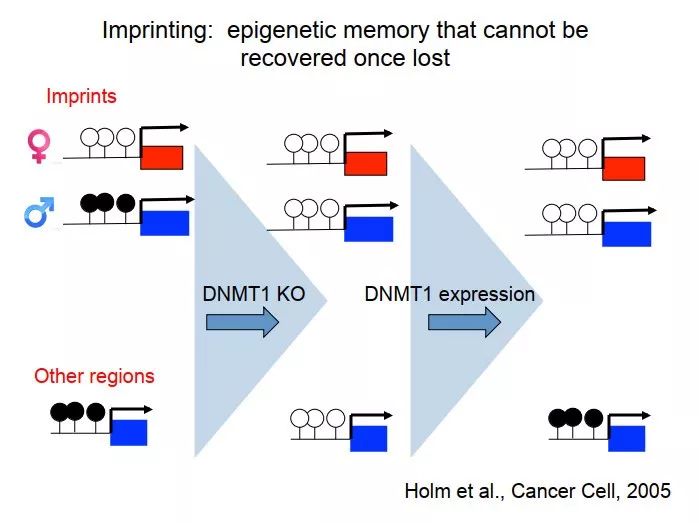
图 44. 基因组印记一旦丢失就难以恢复
非印记基因 DNA 甲基化的遗传
那么有没有基因组印记以外的信息也可以遗留下来呢?这个现在证据不是很多,但是也有一些了。
刚才我们提到的 DNA 去甲基化的过程,大部分 DNA 甲基化在精卵成熟过程中已经被去掉了,但是可以看到胚胎发育早期(图 41 中的 A 点)比出生后的小鼠(图 41 中的 B 点)中甲基化的要高,提示有一些 DNA 甲基化依然没有被去掉。那么这些 DNA 甲基化是不是有功能的?
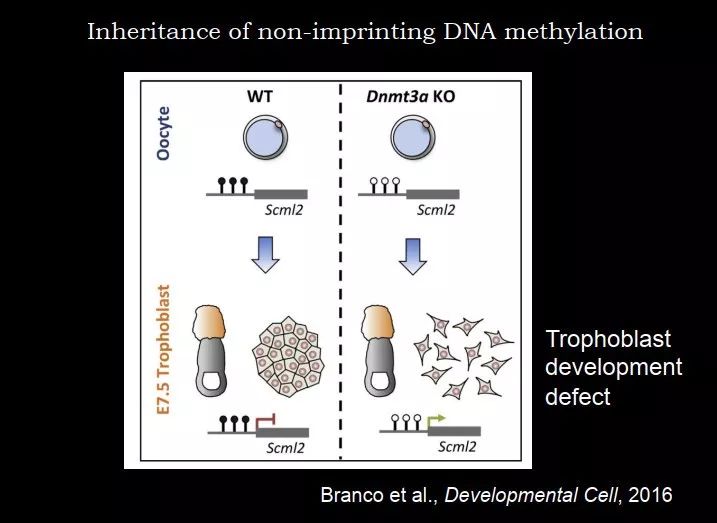
图 45. 非印记基因 DNA 甲基化的保留
2016 年英国的 Wolf Reik 实验室在 Dev Cell 报道,在卵子里面 Scml2 基因是有甲基化的,在着床前仍然保留了甲基化,Scml2 基因被沉默;如果在卵子中把 DNMT3a 敲掉,DNA 甲基化就没有了,这个时候再让去受精,再去看 trophoblast 的发育,它的发育就有问题,就开始出现缺陷,细胞比较散,不能聚集到一起。这个现象只有在卵子里面敲掉 DNMT3a 才可以看到,如果是在着床前做合子的敲除,是没有这个现象的。所以它是在卵子里面形成的 DNA 甲基化遗传到 trophoblast 后发挥这个功能,这是一个很有意思的证据,证明剩下的 20~30% 的 DNA 甲基化可能也是有功能的。
non-CG 甲基化的遗传
这里面还有一些其他的很有意思的现象。我们在 2012 年的时候也做过一个工作,这个工作是在小鼠的大脑里面做了甲基化谱,我们当时是想研究从上一代到下一代 DNA 甲基化的遗传,做了父代和子代的 DNA 甲基化图谱,意外地发现脑里面有很多 mCA 甲基化,这在当时是不知道的,当时认为在成熟的体细胞里面是没有 CA 甲基化的,我们当时发现了大量的 CA 甲基化(占整体甲基化的 35%)。
CA 甲基化是非对称的,它的互补链中没有 C。我们把父源、母源 DNA 分开,去看 DNA 甲基化。发现绝大部分基因组,父源和母源基因组的 CA 甲基化非常相似,但是在基因组的一些位置,在基因组印记区域附近,发现父源和母源 DNA 的甲基化是不一样的,有的时候一边高一边低,它也有"印记"的现象。这个很有意思,它是非对称的,不能被 DNMT1 维持的,理论上是不可能从上一代形成 CA 甲基化遗传到成熟的小鼠大脑中。
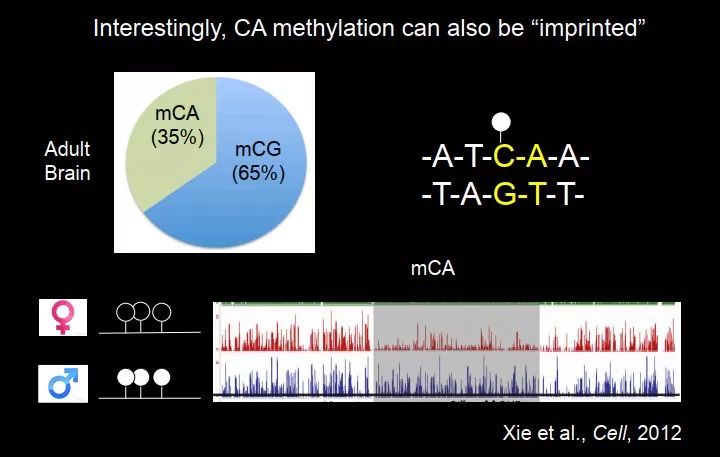
图 46. 小鼠大脑中存在大量可遗传的CA甲基化
这个我们当时感觉很困惑,2013 年索尔克研究所的 Joseph Ecker 在 Science 上报道,他们也在小鼠大脑中发现了 CA 甲基化,CA 甲基化在幼年时期很低,在成年时突触形成的时期出现,提示 CA 甲基化是后天形成的,而且它还知道父本和母本,它又不能从上一代遗传下来,那么这种等位基因特异性的 CA 甲基化在成年大脑中是如何发生的?它必须区分哪一条是父本的,哪一条是母本的。当然这个我们目前没有确切的答案,这是一个 open question。
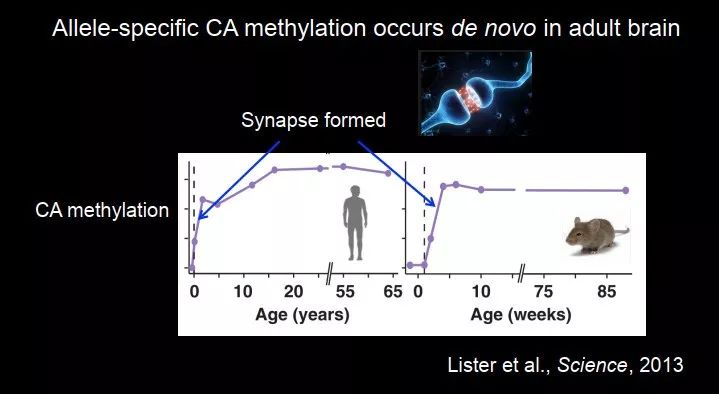
图 47. 等位基因特异性 CA 甲基化在成年大脑中从头形成
我们当时还有一些有意思的发现,也是跟遗传相关的。这个就是我们刚才提到的,我们之前做的那个实验,从父代到子代都测 DNA 甲基化,看 DNA 甲基化是怎么从上一代传递到下一代的。在基因中有一部分是跟基因组印记相关的,加在一起大约有 2000 个父源和母源基因组中 CG 不一样的位点,另外我们发现大量的等位基因特异性的位点其实不是父本或者母本决定的,而是序列决定的,这种类型更多,在等位基因特异性的 DNA 甲基化里面占了 98.5%,刚才提到的基因组印记只占了 1.5%。
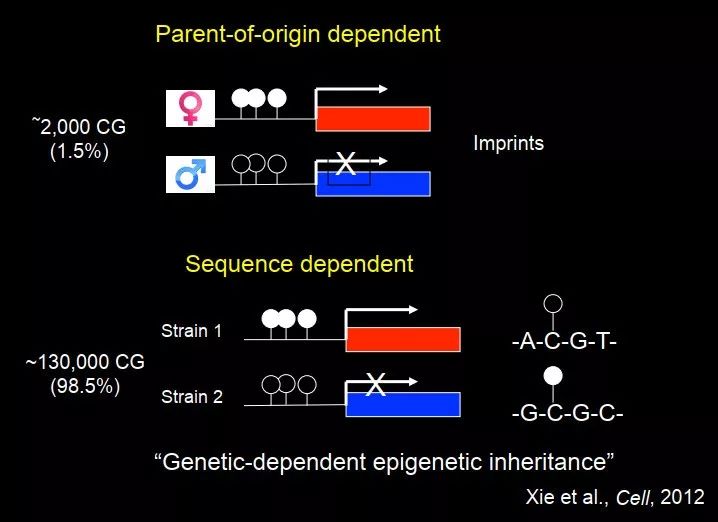
图 48. 亲源依赖性和序列依赖性的 DNA 甲基化遗传
我们后来去研究了,为什么这些等位基因特异性的DNA甲基化与 DNA 序列相关?发现甲基化高的那条等位基因的 mCG 位点两边是 G、C,甲基化比较低的那条等位基因的两边是 A、T,最终我们看到了类似 DNA 甲基化的 motif,即 DNA 甲基化其实是有一定的序列偏好性,不是很强但也是有的。在植物里面也是这样的,也就是说当序列为 ACGT 时,不太容易甲基化;当序列为 GCGC 时,容易甲基化。在某种程度上,这是一种遗传学依赖的表观遗传(genetic dependent epigenetics inheritance)。所以到最后,表观遗传和遗传在某种程度上又联系到一块儿去了。
生物体就是这样,比我们想象得更奇妙一些。上面我们讲到的主要是DNA甲基化的部分,那么又人会说,在胚胎发育的时候,刚才提到了 DNA 甲基化和开放染色质,组蛋白修饰能不能从上一代遗传给下一代呢?
胚胎发育过程中组蛋白修饰的重编程
这个之前没有一个明确的答案,在 2009 年有一篇 Nature 做了这样一个工作,在人的精子里面去做组蛋白修饰。刚才我们提到,精子为了包装自己的 DNA,组蛋白都不要了,那么组蛋白修饰是怎么来的?其实组蛋白还剩下了 5%,那上面有修饰,把这些组蛋白拿出来后去检测修饰,发现修饰很特异,比如图 49 上面的是 H3K27me3,下面是 H3K4me3,它们都分布在特定的基因上,比如说 H3K27me3 在 Hox 基因附近。2015 年英国的 Gavin Kelsey 实验室做了正在发育中的卵子里面的组蛋白修饰,包括 H3K36me3、H3K4me2、H3K4me3。
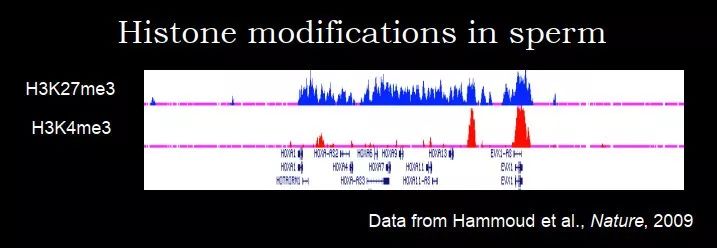
图 49. 精子中的组蛋白修饰
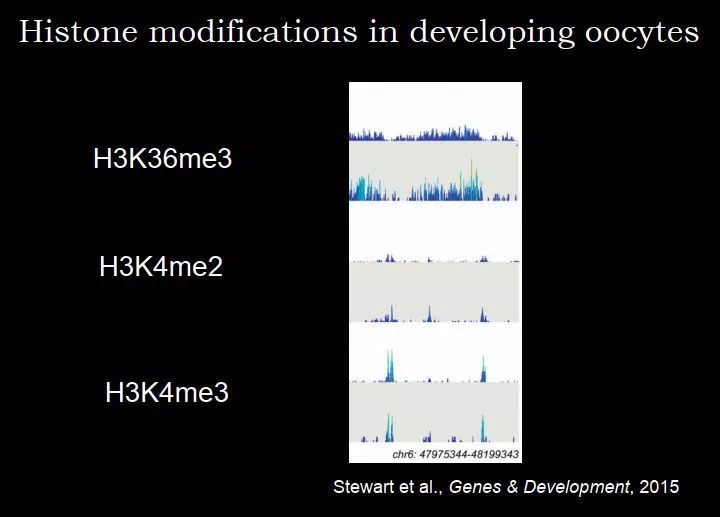
图 50. 发育中的卵子中的组蛋白修饰
这两个工作证明,配子里面是可以有组蛋白修饰的,这些组蛋白修饰能否传递给下一代?这个问题是相对比较难回答的,主要是材料的限制,很多时候做 ChIP 是需要大量的细胞的。之前的很多研究是利用了免疫荧光,如果去染组蛋白,雄原核和雌原核里面都是存在的;如果去染 H3K4me3,雄原核里面没有,雌原核是有的。从免疫荧光的结果来看,好像是精子中的组蛋白修饰被去掉了,卵子上的还在。有些实验室研究更多的组蛋白修饰,他们发现这个好像是一个规律:很多(但不是全部的)父源的标签倾向于去除,比如 DNA 甲基化、H3K4me3、H3K27me3、H3K9me2/3 都是父源的低、母源的高。那么问题来了:为什么这两个基因组是不一样的?
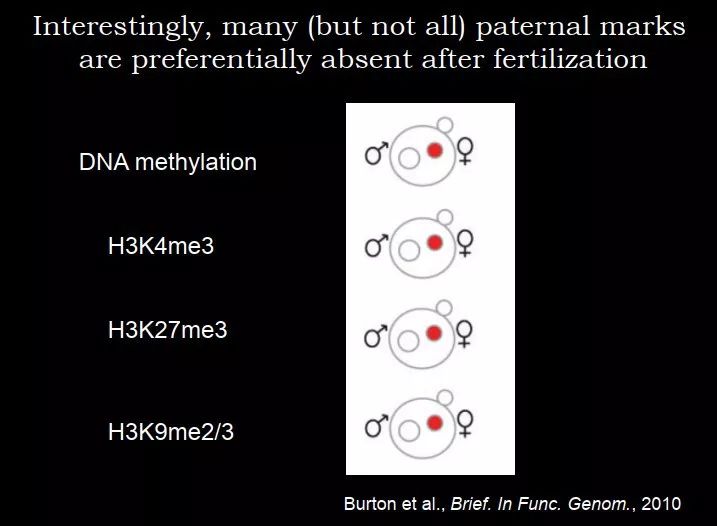
图 51. 雄原核和雌原核中表观遗传修饰的差异
男同胞可能会不高兴,我们的东西都丢掉了,母亲那边保留的还不错,这也是一个 open question。我们不知道为什么父源那边丢的比较多,这是在免疫荧光的水平,暂时还没有看到分子水平的证据;而且需要更多的功能性的研究来解释为什么父源和母源的表观遗传修饰是不一样的。
最后稍微总结一下最后一部分,我们聚焦到早期发育过程,这部分的表观遗传信息是如何重编程的?它有一个非常 extensive 的重编程过程,很多东西都去掉了。在这个过程中,有一些表观遗传标记被遗传给下一代,包括基因组印记、非印记的 DNA 甲基化,而且它们有可能也是有功能的,那么我们可以看到至少在代际遗传中可以看到有一些表观遗传信息可遗传的证据的。
以上就是我今天的报告。最后送大家一句话:Get a good genome. Make a better epigenome. 什么意思呢?Genome 是很难选择的,当然我们希望从父母遗传得到一个好的 genome;而 epigenome 方面,我们是可以发挥一些作用的,多跑跑步呀,做一些健康的运动,看看书,看看 paper。
转自:基因谷
- 本文固定链接: https://maimengkong.com/kyjc/984.html
- 转载请注明: : 萌小白 2022年6月7日 于 卖萌控的博客 发表
- 百度已收录
