1 什么是整洁数据?
2 tidyverse怎么使用?
tidyverse是由RStudio首席科学家Hadley Wickham开发的R套装的集合。 这些包作为大数据分析管道的一部分可以很好地协同工作。要了解这些工具及其协同工作的更多信息,请阅读R for data science。 对于R的新手,请查看我之前的Storybench教程:RStudio笔记本中的R入门。
以下教程将介绍tidyverse中用于构建和分析数据集的一些基本功能。 这是关于清理数据的三部分系列中的第一部分,使用tidyverse在R中对其进行可视化。
加载包
首先,安装tidyverse,然后加载tidyverse和magrittr。
suppressWarnings(suppressMessages(install.packages( "tidyverse")))
suppressWarnings(suppressMessages( library(tidyverse)))
suppressWarnings(suppressMessages( library(magrittr)))
学习“管道”
我们将在本教程中使用“管道”。 管道使您的代码读起来更像一个句子,从左到右分支。 所以像这样:f(x)变成这样:x%>%f和这样的东西:h(g(f(x)))变成这样:x%>%f%>%g%>%h
“管道”来自magrittr包。 请阅读此处的使用方法。
什么是整洁的数据?
“整洁数据”这一术语描述了构建数据集以使分析和可视化更容易的标准化方法。 如果您使用过SQL和关系数据库,那么您将认识到大多数这些概念。 Hadley Wickham从Edgar F. Codd的正常形式中获取了许多技术术语,并将其应用于单个数据表。 更重要的是,他将这些原则转化为几乎任何进行数据分析的人应该能够识别和理解的术语。
整洁数据的核心原则
整洁数据有三个原则:
- 变量构成列
- 观察组成行
- 值放在单元里面
如果您处理了前两个原则,第三个原则几乎是给定的,因此我们将重点关注这些原则。
一个假设的临床试验来解释变量
变量是可以采用多个值的任何度量。根据数据集来自的字段,变量可以称为自变量或因变量,特征,预测变量,结果,目标,响应或属性。
变量通常可以分为三类:固定变量(在收集数据之前已知的特征),测量变量(包含研究或调查期间捕获的信息的变量)和派生变量(在现有变量分析过程中创建的变量)。
这是一个例子:假设临床医生正在测试一种新的抗高血压药物。他们招募了30名患者,他们都接受了高血压治疗,并将他们随机分成三组。临床医生给三分之一的患者服用药物八周,另外三分之一的人服用安慰剂,最后三分之一照常照顾。在研究开始时,临床医生还收集有关患者的信息。这些测量包括患者的性别,年龄,体重,身高和基线血压(BP前)。
对于该假设研究中的患者,假设他们被随机分组的组(即药物,对照组或安慰剂组)将被视为固定变量。前BP(和后BP)测量将被视为测量变量。
假设在试验结束后 - 收集了所有数据 - 临床医生想要一种方法来确定试验中血压降低的患者数量(是或否)?一种方法是创建一个新的分类变量,用于识别血压低于140 mm Hg的患者(1 =是,0 =否)。这个新的分类变量将被视为派生变量。
我所描述的虚构研究的数据也包含时间的基本维度。如描述所示,在服用药物(或安慰剂)之前和之后测量每位患者的血压。因此,可以想象这些数据可以包括入组日期(患者进入研究的日期),血压前测量日期(基线测量),给药日期(患者服用药物),血压测量日期(在研究结束时进行血压测量)。
什么是观察?
观察是分析的单位,或者是由变量描述的“事物”。 坚持我们假设的血压试验,患者将成为分析的单位。 在整洁的数据集中,我们希望每行代表一个患者。 观察有点像名词,从某种意义上说,确定一个确切的定义可能很困难,而且它往往很大程度上取决于数据的收集方式以及您尝试回答的问题类型。 观察的其他术语包括记录,案例,示例,实例或样本。
什么是数据表?
表由值组成。 正如您可能已经猜到的那样,值是电子表格中不是行或列的东西。 我认为将值视为表中的物理位置是有帮助的 - 它们位于变量和观察的交叉点。
例如,假设一个数字,75,放在一个表里。
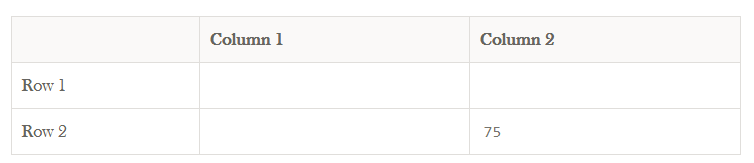
我们可以说这个数字的位置是第2列和第2行的交集,但这并没有告诉我们多少。 数据75在没有任何关于它代表什么的信息的情况下无意义地放在一个表中。 一张表上的一个数字引出了一个问题,“七十五是什么?”
这就是为什么将表视为变量(在列中)和观察(在行中)有助于获得每个单元格中值的背后的含义。 在添加变量(列)和观察(行)名称后,我们可以看到该75是患者3号(患者_3)的舒张前血压(Pre_Dia_BP)。

值得指出的是,同样的信息可以用另一种方式呈现:
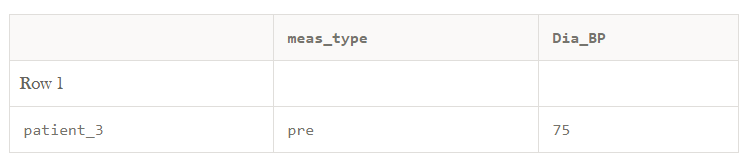
该布置显示相同的信息(即,对于患者编号3的舒张前血压),但是现在列meas_type包含关于75代表哪个血压测量的信息(预)。 哪一个很整洁? 为了回答这个问题,我们将建立一个宠物示例来建立一些基本的整理术语。
“tibble”如何比table更好
我们将使用下面的调用来创建键值对引用tibble。 在使用tidyverse的包时,tibbles是一种优化的存储数据的方法,你应该在这里阅读更多关于它们的信息。
我们将从头开始构建一个tibble,定义列(变量),行(观察)和每个单元格的内容(值)。 通过这样做,我们将能够跟踪重新排列这些数据时发生的情况。 这个简短练习的目标是使键值对更易于查看和理解。
我们的新对象(key_value)使用以下基础逻辑构建。
行使用数字(1-3)和下划线()编号,并始终显示在值的前面。 列使用下划线()和数字(1-3)编号,并始终显示在值的末尾。
library(tidyr)
library(tibble)
key_value <- tribble(
~row, ~key1, ~key2, ~key3, # These are the names of the columns (indicated with ~)
"1", "1_value_1", "1_value_2", "1_value_3", # Row 1
"2", "2_value_1", "2_value_2", "2_value_3", # Row 2
"3", "3_value_1", "3_value_2", "3_value_3"# Row 3
)
key_value
因此,key1和row = 1的值是1_value_1; key2和row = 2的值是2_value_1; 等等。
第一个数字#表示行(观察)位置,尾随数字#表示key_列(变量)位置。
使用tidyr包
tidyr是tidyverse的一个软件包,它可以帮助您构建(或重新构建)数据,从而更容易实现可视化和建模。 这是tidyr页面的链接。 整理数据集通常涉及将行转换为列(扩展)或将列切换为行(收集)的某种组合。
我们可以使用我们的key_value对象来探索这些函数的工作方式。
使用 gather
“Gather占用多列并折叠成键值对,根据需要复制所有其他列。 当你注意到你的列不是变量时,你可以使用gather()。“这就是tidyverse定义gather的方式。
让我们首先将三个关键列收集到一个列中,并使用包含其所有值的新列值。
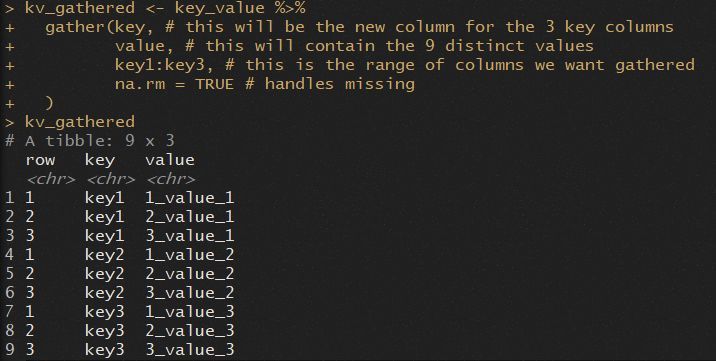
kv_gathered<- key_value %>%
gather(key, # this will be the new column for the 3 key columns
value, # this will contain the 9 distinct values
key1:key3, # this is the range of columns we want gathered
na.rm = TRUE # handles missing
)
kv_gathered
注意结构:
- 新的键列现在是9行,其中包含三个以前的key1,key2和key3列的值。
- 值列包含行的每个交集处的单元格以及key1,key2和key3列的所有内容
我把这种数据安排称为“堆叠”。 威克姆将此称为索引。 但重要的是,我们使用gather()来挖掘最初分散在三列中的数据,并将它们分为两列:键和值。
使用键值对
键值对将键和值配对。 这意味着当我们将key指定为新列的名称时,该命令将获取前三个键列并将其堆叠在其中。 然后我们将value指定为新列的名称及其对应的值对。
行列怎么样? 我们留下这列,因为我们希望它保持相同的安排(即1,2,3)。 当键和值列堆叠时,这些行会在列中重复出现,
在此过程中也没有任何损失。 我仍然可以查看行:3,键:2并查看结果值3_value_2。
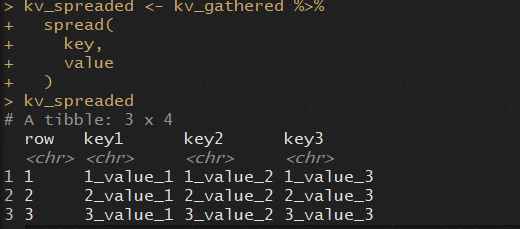
使用spread
现在我们将键和值列重新分配回原始排列(key_1,key_2和key_3三列)。spread描述显示:“跨多个列传播键值对。”
kv_spreaded <- kv_gathered %>%
spread(
key,
value
)
kv_spreaded
Spread将堆叠在两列(键和值)中的值移动到三个不同的key_列中。
键值对是我们可以用来重新排列数据以使其整洁的索引。
哪个版本的key_value很整洁? 我们说整齐的数据意味着“每列一个变量,每行一个观察”,因此满足这个条件的安排是key_gathered数据集。 但我想强调的是,如果不了解这些变量和观察结果实际包含的内容,我们就无法真正知道这些数据是否整洁。
完整代码library(tidyr)
library(tibble)
key_value <- tribble(
~row, ~key1, ~key2, ~key3, # These are the names of the columns (indicated with ~)
"1", "1_value_1", "1_value_2", "1_value_3", # Row 1
"2", "2_value_1", "2_value_2", "2_value_3", # Row 2
"3", "3_value_1", "3_value_2", "3_value_3"# Row 3
)
key_value
kv_gathered <- key_value %>%
gather(key, # this will be the new column for the 3 key columns
value, # this will contain the 9 distinct values
key1:key3, # this is the range of columns we want gathered
na.rm = TRUE# handles missing
)
kv_gathered
kv_spreaded <- kv_gathered %>%
spread(
key,
value
)
kv_spreaded
原文链接:
http://www.storybench.org/getting-started-with-tidyverse-in-r/
- 本文固定链接: https://maimengkong.com/kyjc/1167.html
- 转载请注明: : 萌小白 2022年8月21日 于 卖萌控的博客 发表
- 百度已收录
