作者:伊莲小小小小仙女,R语言中文社区专栏作者。个人公众号:MeMyselfandYou
这篇文章大概在好几个月前就存在在脑海中。最开始是看了《迟到的情人节礼物:做一个与她微信聊天的词云吧》,觉得作者写的很好玩,那个时候因为工作的原因刚开始学习R语言,一窍不通,我就想着那就用R学着同样分析一遍好了,应该能收获不少。于是,我开始分析和男友的微信聊天记录,只不过正如原文作者所说,分析着,情人节变情人劫怎么办?Anyway, 今天是来交作业的。
获取数据源
首先《迟到的情人节礼物:做一个与她微信聊天的词云吧》一文中的作者已经写的非常详细了,我也完全按照原文章中的步骤操作。不过在这里给大家两小提示:
1)网上有各类提取微信聊天记录的软件或攻略,每个mac版都试过,都不可行,最后只有iMazing可以成功提取。
2)iMazing, 一定要下载正版,我就是因为误下盗版,差点把手机毁掉,到现在手机感觉还是有点坏坏的(后遗症)。这个软件功能强大,用不好的话IPhone变板砖。
原文是用Python写,下面是我的R代码,略有不同。本人代码能力为0,太复杂循环算法都写不了,只能按照自己的思路一点点拼出来。
conn <- dbConnect(dbDriver("SQLite"), dbname="MM.sqlite")//设置连接函数
doCountQuery <- function(conn,table){query <- paste("SELECT COUNT(name) FROM ",table,sep ="")t <- dbGetQuery(conn,query) return(t)}
table_name <- dbGetQuery(conn, "SELECT name FROM sqlite_master where type='table' and name like 'Chat_%' order by name")//取出所有表名,由于不会遍历,只能按照最笨的办法,计算哪个表的数据量最多,即是和男盆友的聊天记录表,如果不是和男盆友的聊天表,此方法是找不出来
counts <- numeric(0)for (i in 1:length(table_name) ){count <- doCountQuery(conn,table_name[i])counts[i] <-count[[1]] }//计算表长table_count <- data.frame(counts)
//排序,表长最大的表,即是和男朋友的聊天记录表table_count1 <- table_count[order(table_count$counts,decreasing=TRUE),]
//提取到聊天内容message <- dbGetQuery(conn, "SELECT * FROM Chat_XXXXXXXXXX ")
文本分析
拿到数据后就是进行文本分割,由于数据量实在庞大,我的电脑已经跑死好几次。后来,在完全不懂,也不知如何求解的情况下,靠部分代码和部分Excel互相切换,得到了想要的结果。
library(data.table)library(stringr)
cutter=workerwechat_content =messagewechat_content <- as.character(wechat_word$V1)///由于数据量过大,不知道为什么只用cuter无法把所有数据都遍历到,无奈只能写简单的函数每一条遍历切割
cut_y <- function (y){y=gsub(".","",y)cutter[as.character(y)]}//遍历切割每一条聊天内容y.out <- sapply(wechat_content,cut_y,USE.NAMES = F)
//去除数字y.out<-gsub("[0-9]+?","",y.out)
// 去除停止词s <- read.csv(‘stopwords.csv’)stopwords <- c(NULL)for (i in 1:length(s)){stopwords[i] <- s[i]}y.out <- filter_segment(y.out,stopwords)
//遍历计数后再组合到一起wechat_content_whole <- as.array(0)for (i in 1:length(y.out)){table_content <- count(y.out[[i]])wechat_content_whole <- rbind(wechat_content_whole,table_content)}
//最后计数wechat_content_whole <- count(wechat_content_whole,"x")
//从大到小排列wechat_content_whole<- wechat_content_whole[order(wechat_content_whole$freq,decreasing=TRUE),]
//提取前1000条做词云wechat_words_final <- table_content_whole_final[1:1000,]
//颜色从粉到白函数clufunc <- colorRampPalette(c("pink","white"))
//形成词云 wordcloud2(wechat_words_final, fontFamily = "HYTangTangCuTiJ", figPath = "love.jpg", size=1, color=clufunc(1000))
结果
一年零三个月
344442行
17万+
这次的分析一共收集了一年零三个月的聊天记录,总提取34442行数据,17万+个分词,下面的图就是最后提取的前1000个高频词的词云。

在过程中也发现了一些别样的东西:

“马老师”的字眼反复出现,这绝不是补习班的老师,更不是制服诱惑,马老师,一起加油

另外,在我们的聊天内容中,最常用的十大emoji竟是它们:
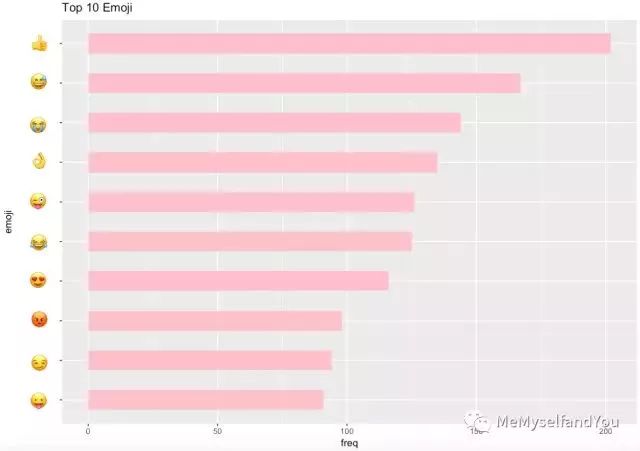
点赞最多,看来我们互相很认可对方,但是生气为啥也那么多?

此外,我还挑出过去N次吵架的聊天记录,做了下面的图。情人之间的吵架大概都大同小异吧,没有安全感,互相拒绝着对方,说着伤人的话。

后话
这个一次次丢掉又捡起来的小学习作业终于划上了一个句号。分析的过程的确痛苦,一方面要学习各种语法,另一方面,翻开聊天记录就像扒开自己的肉一样疼,回忆一幕幕,开心难过百感交集。这之间有自己的迷茫,有学术的无知,也有爱情的摸索,幸好,我们依旧,携手走在一起。
这个小分析同时也是一个起点,这几个月在R语言上收获颇多。没想到开始的机缘巧合燃起了对R的热情。学习过程,不像学校里的课程授课,几乎都是想实现一个功能,于是去查找,找到一个语法,联系到更多的知识,联系,联系,最后再串起来。
记得从最一开始rJava包在我的电脑上没法安装,在Google上翻过所有的问答,StackOverflow成了我泡得最多的网站,远在英国的同学也帮忙解答。。。每一次反复调代码的时候,都是深夜凌晨,可当调好的瞬间又那么欣喜如狂。
再回头看,这个小作业很简单,但是从中已经学到了R语言里几乎所有的基础语法,虽然中间部分的算法还很凌乱,至少为自己感到骄傲。现在可以任意用ggplot画一个漂亮的统计图,而不是千篇一律的Excel。当然,如果有大神能拯救我以上杂乱的算法,欢迎指导学习,也希望下一个学习项目能分享和发现更多有趣的东西
转自:R语言中文社区- 本文固定链接: https://maimengkong.com/morejc/1081.html
- 转载请注明: : 萌小白 2022年6月30日 于 卖萌控的博客 发表
- 百度已收录
