作者介绍:
黄升,普兰金融数据分析师,从事数据分析相关工作,擅长R语言,热爱统计和挖掘建模。
目录
-
使用Logistic和NaiveBayes建模
-
Score Card原理
-
Naive Bayes评分卡
-
Logistics评分卡
信用评分是指根据客户的信用历史资料,利用一定的信用评分模型,得到不同等级的信用分数。根据客户的信用分数, 授信者可以分析客户按时还款的可能性。据此, 授信者可以决定是否准予授信以及授信的额度和利率。
虽然授信者通过分析客户的信用历史资料,同样可以得到这样的分析结果,但利用信用评分却更加快速、更加客观、更具有一致性。
使用logistic和NaiveBayes建模
本文中建模所用到的数据是关于德国公民的信用相关数据,接下来我们针对这个数据集进行模型。
# 加载第三方包
library(ggplot2)
library(klaR)
library(sqldf)
# 数据读取
german_credit <- read.csv(file.choose(),stringsAsFactors = TRUE)
# 数据结构展示
str(german_credit)
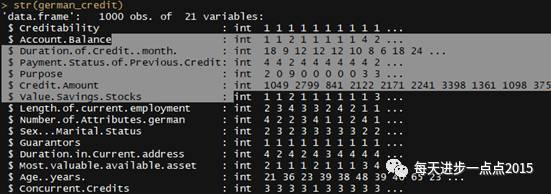
数据中的字段主要包含信用(模型中的因变量1为好客户,0为坏客户),账户余额,信用月数,贷款目的等。由于上面的数据大都都是数值型的,故需要根据实际情况将数值变量转换成因子型变量。
# 自定义函数
fun <- function(x) {as.factor(x)}
# 数据类型转换
for( i in1: 21) german_credit[,i] <- fun(german_credit[,i])
# 个别数据再转换为数值型
german_credit$Duration.of.Credit..month. <- as.numeric(german_credit$Duration.of.Credit..month.)german_credit$Credit.Amount <- as.numeric(german_credit$Credit.Amount)german_credit$Age..years. <- as.numeric(german_credit$Age..years.)
接下来,我们把读取进来的数据集划分为两部分,一部分为好客户(变量Creditability为1)的信息,另一部分为坏客户(变量Creditability为0)的信息。
good <- german_credit[german_credit$Creditability== 1,]bad <- german_credit[german_credit$Creditability== 0,]
# 取出数据集的变量名
a <- colnames(german_credit)
为了了解数据,我们对数据集中的各变量绘制条形图,这里仅以客户的存款余额为例,如果想了解更多其他变量的分布信息,可以稍作修改下方的代码。
# 整体用户的存款余额条形图
ggplot(german_credit,aes(german_credit[, 2])) + # 条形图geom_bar(aes(fill = as.factor(german_credit[, 2]))) + # 填充色scale_fill_discrete(name=a[ 2]) + # 主题设置theme(axis.text.x=element_blank(),axis.ticks.x=element_blank()) +
# 添加轴标签和标题labs(x= a[ 2],y= "Frequency", title = "german_credit")

#好客户的条形图
ggplot(good, aes(good[, 2]) ) + geom_bar(aes(fill = as.factor(good[, 2]))) + scale_fill_discrete(name=a[ 2]) + theme(axis.text.x=element_blank(), axis.ticks.x=element_blank()) + labs(x= a[ 2],y= "Frequency", title = "good")
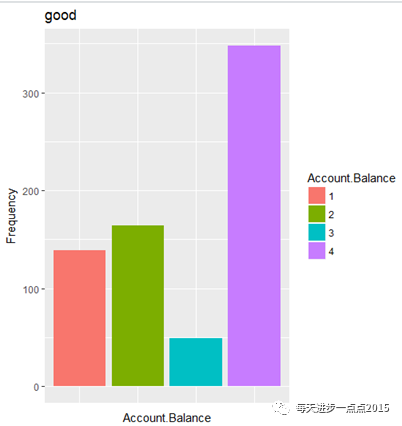
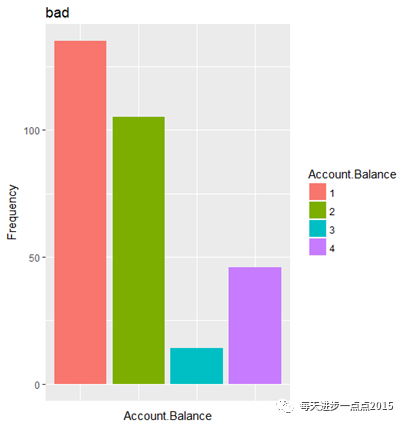
#坏客户的条形图ggplot(bad, aes(bad[, 2]) ) + geom_bar(aes(fill = as.factor(bad[, 2]))) + scale_fill_discrete(name=a[ 2]) + theme(axis.text.x=element_blank(), axis.ticks.x=element_blank()) + labs(x= a[ 2],y= "Frequency", title = "bad")
Logistic模型
在建模之前,需要多数据集进行拆分,一部分用作建模,另一部分用作模型的测试。
# 设置抽样的随机种子
set.seed( 1234)
#抽样(训练集和测试集的比例为7:3)
index <- sample( 1: 2, size = nrow(german_credit), replace = TRUE, prob = c( 0.7, 0.3))train_data <- german_credit[index == 1,]test_data <- german_credit[index == 2,]
# 建模
model1 <- glm(formula = train_data$Creditability ~ ., data =train_data, family = 'binomial')
# 模型信息概览
summary(model1)
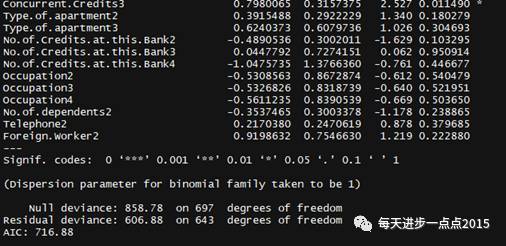
从上图的模型结果来看,Logistic模型中很多自变量都没有通过显著性检验,接下来,我们利用逐步回归的方法,重新对模型进行建模。
# 重新建模
model2 <- step(object = model1, trace = 0)
# 模型信息概览
summary(model2)
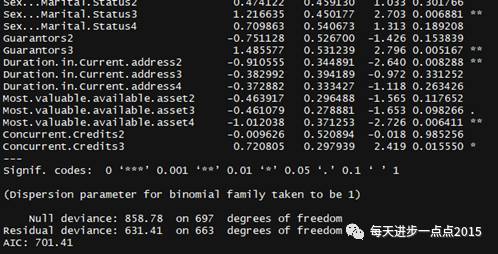
经过逐步回归之后,模型效果得到了一定的提升(留下来了很多显著的自变量,同时AIC信息也下降了很多)。我们知道,通过Logistc模型可以得到每个样本的概率值prob,该概率值是可以根据实际的业务进行调整的,如果风控要求的比较严格,那么就需要将prob值调节的更大。
下面,我们对模型的效果作一个评估,这里就使用混淆矩阵作为评估标准:
# 返回模型在测试集上的概率值
prob <- predict(object = model2, newdata= test_data, type = 'response')
# 根据阈值,将概率值分为两类
pred <- ifelse(prob >= 0.8, 'yes', 'no')
# 将pred变量设置为因子
pred <- factor(pred, levels =c( 'no', 'yes'), order = TRUE)
#混淆矩阵
f <- table(test_data$Creditability, pred)f
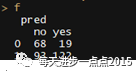
结果显示,模型的准确率为62.9%【(68+122)/(68+122+19+93)】,其中19指的是实际为坏客户,预测为好客户的数量;93指的是实际为好客户,预测为坏客户的数量。上面是将prob的阈值设置为0.8时的结论,下面再将阈值设置为0.5时,看看是什么结果。
# 返回模型在测试集上的概率值
prob <- predict(object = model2, newdata= test_data, type = 'response')
# 根据阈值,将概率值分为两类
pred <- ifelse(prob >= 0.5, 'yes', 'no')
# 将pred变量设置为因子
pred <- factor(pred, levels =c( 'no', 'yes'), order = TRUE)
#混淆矩阵
f <- table(test_data$Creditability, pred)f
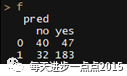
通过改变概率的阈值,模型的准确率有所提升,达到73.8%【(183+40)/(183+40+32+47)】,其中47指的是实际为坏客户,预测为好客户的数量;32指的是实际为好客户。当然,我们还可以更换模型,根据实际的业务进行变量的筛选,这个过程会比较繁琐,我们就以下面这个模型为例:
# 建立新的模型
model3<- glm(formula=Creditability~Account.Balance+Duration.of.Credit..month.+Payment.Status.of.Previous.Credit+Purpose+Value.Savings.Stocks+Sex...Marital.Status,data=train_data,family = 'binomial')
# 模型概览信息
summary(model3)
# 测试集上的预测
prob <- predict(object = model3, newdata= test_data, type = 'response')pred <- ifelse(prob >= 0.8, 'yes', 'no')pred <- factor(pred, levels =c( 'no', 'yes'), order = TRUE)f <- table(test_data$Creditability, pred)f
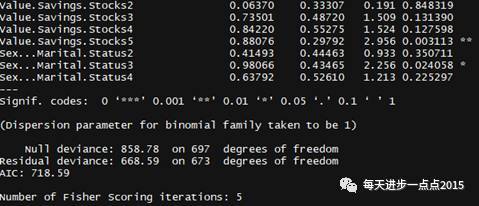
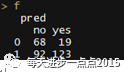
上图显示,相比于model2模型对应的0.8的阈值,这次新建的模型要比逐步回归的准确率提高了一丁点(0.3%),我相信模型的变更应该还会使准确率提升。上面的这些模型结果全都是基于Logistic得到的,下面我们再用贝叶斯模型做一次效果的对比。
贝叶斯模型 #贝叶斯模型
model4<- NaiveBayes(formula=Creditability~Account.Balance+Payment.Status.of.Previous.Credit+Duration.of.Credit..month.+Purpose+Value.Savings.Stocks+Sex...Marital.Status,data=train_data)
# 预测
pre <- predict(model4, newdata = test_data)
# posterior存储每个样本为坏客户和好客户的概率值
str(pre$posterior)
# 将好客户的概率阈值设置为0.8+
pre$posterior[, 2]pred <- ifelse(pre$posterior[, 2] >= 0.8, 'yes', 'no')f <- table(test_data$Creditability, pred)f

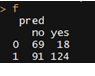
Well Done,同为0.8的阈值,相比于model2和model3,贝叶斯模型得到的测试效果最佳,准确率达到了64%【(69+124)/(69+124+18+91)】。由于在风控领域,人们对待错误的判断会有不同的感受,例如原本一个好客户被判为了坏客户和原本一个坏客户被判为了好客户,也许你会对后者的错判带来的坏账损失而后悔,对前者的错判只会感到遗憾。不妨我们根据这种感受来规定一个错判的损失表达式:
lost=5*(坏预测为好的数量)+(好客户预测为坏客户的数量)
-
Model2在prob>0.8的 lost=19*5+93=188
-
Model2在prob>0.5的 lost2=47*5+32=267
-
Model3在prob>0.8的 lost3=19*5+92=187
-
Model4在prob>0.8的 lost5=18*5+91=181
虽然在建模过程中发现model2在0.5的阈值情况下准确率最高,但它带来的的损失值也是最高的,损失值最低的模型则是贝叶斯模型。
Score Card原理
评分卡模型在国外是一种成熟的预测方法,尤其在信用风险评估以及金融风险控制领域更是得到了比较广泛的使用,其原理是将模型变量离散化之后用WOE编码,在建立模型。ScoreCard用IV值来筛选变量,而且ScoreCard输出为分值。
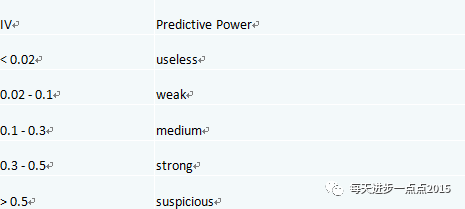
对IV的直观理解
IV的全称是Information Value,中文意思是信息价值,或者信息量。从直观逻辑上大体可以这样理解“用IV去衡量变量预测能力”这件事情:我们假设在一个分类问题中,目标变量的类别有两类:Y1,Y2。对于一个待预测的个体A,要判断A属于Y1还是Y2,我们是需要一定的信息的,假设这个信息总量是I,而这些所需要的信息,就蕴含在所有的自变量C1,C2,C3,……,Cn中,那么,对于其中的一个变量Ci来说,其蕴含的信息越多,那么它对于判断A属于Y1还是Y2的贡献就越大,Ci的信息价值就越大,Ci的IV就越大,它就越应该进入到入模变量列表中。
IV,WOE的计算
前面我们从感性角度和逻辑层面对IV进行了解释和描述,那么回到数学层面,对于一个待评估变量,他的IV值究竟如何计算呢?为了介绍IV的计算方法,我们首先需要认识和理解另一个概念——WOE,因为IV的计算是以WOE为基础的。
-
WOE的计算
WOE的全称是“Weight of Evidence”,即证据权重。WOE是对原始自变量的一种编码形式。要对一个变量进行WOE编码,需要首先把这个变量进行分组处理(也叫离散化、分箱等等,说的都是一个意思)。分组后,对于第i组,WOE的计算公式如下:
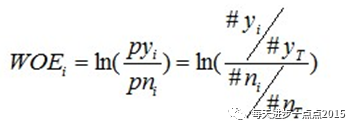
其中,pyi是这个组中响应客户(风险模型中,对应的是违约客户,总之,指的是模型中预测变量取值为“是”或者说1的个体)占所有样本中所有响应客户的比例,pni是这个组中未响应客户占样本中所有未响应客户的比例,#yi是这个组中响应客户的数量,#ni是这个组中未响应客户的数量,#yT是样本中所有响应客户的数量,#nT是样本中所有未响应客户的数量。
从这个公式中我们可以体会到,WOE表示的实际上是“当前分组中响应客户占所有响应客户的比例”和“当前分组中没有响应的客户占所有没有响应的客户的比例”的差异。对这个公式做一个简单变换,可以得到:
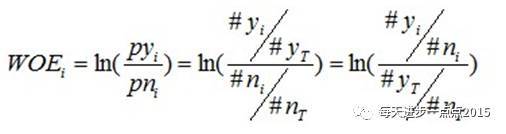
有了前面的介绍,我们可以正式给出IV的计算公式。
-
IV的计算
同样,对于分组i,也会有一个对应的IV值,计算公式如下:
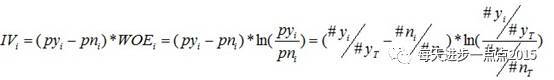
有了一个变量的各分组IV值,我们就可以计算整个变量的IV值,方法很简单,就是把各分组的IV相加:
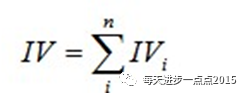
其中,n为变量分组个数。
-
分数的计算
我们将客户违约的概率表示为1-p,则正常的概率为p,可以得到优势比:
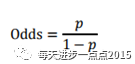
评分卡设定的分值刻度可以通过将分值表示为比率对数的线性表达式来定义,即可表示为下式:
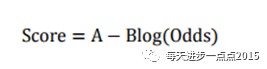
其中,A和B是常数。式中的负号可以使得违约概率越低,得分越高。通常情况下,这是分值的理想变动方向,即高分值代表低风险,低分值代表高风险。
-
逻辑回归的计算比率公式
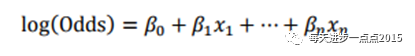
逻辑回归的分数计算:式中变量x1…xn是出现在最终模型中的自变量,即为入模指标。由于此时所有变量都用WOE进行了转换,可以将这些自变量中的每一个都写成如下形式:
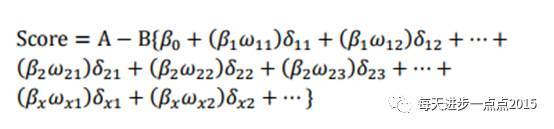
上式中ωij 为第i行第j个变量的WOE,为已知变量;βi为逻辑回归方程中的系数,为已知变量;δij为二元变量,表示变量i是否取第j个值。上式可重新表示为:
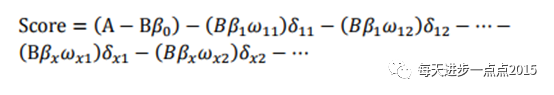
-
贝叶斯的计算比率公式
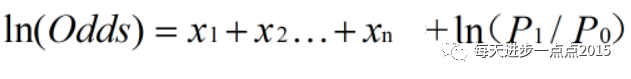
式中变量x1…xn是出现在最终模型中的自变量,即为入模指标。由于此时所有变量都用WOE进行了转换,可以将这些自变量中的每一个都写成如下形式(同逻辑回归模型,只不过β0=0其他β都为1)
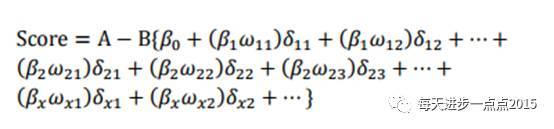
式中ωij 为第i行第j个变量的WOE,为已知变量;βi为逻辑回归方程中的系数,为已知变量;δij为二元变量,表示变量i是否取第j个值。上式可重新表示为:
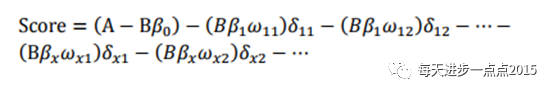
Naive Bayes评分卡
首先需要对部分变量作重编码的操作,这个操作在实际工作中需要不断的调试才能得到比较理想的效果。
# 条件筛选(分箱)
index1 <- which(german_credit$Duration.of.Credit..month.> 40)index2<-which(german_credit$Duration.of.Credit..month.<= 40& german_credit$Duration.of.Credit..month. > 30)index3<-which(german_credit$Duration.of.Credit..month.<= 30& german_credit$Duration.of.Credit..month. > 20)index4 <- which(german_credit$Duration.of.Credit..month. <= 20)
# 重编码
german_credit$Duration.of.Credit..month.[index1] <- '1'
german_credit$Duration.of.Credit..month.[index2] <- '2'
german_credit$Duration.of.Credit..month.[index3] <- '3'
german_credit$Duration.of.Credit..month.[index4] <- '4'
german_credit$Purpose[german_credit$Purpose== 8] <- 1
german_credit$Purpose[german_credit$Purpose== 10] <- 0
german_credit$Purpose[german_credit$Purpose== 4] <- 3
german_credit$Purpose[german_credit$Purpose== 9] <- 5
#对month变量进行分组统计
a1=sqldf( "select `Duration.of.Credit..month.`,count(1) from train_data where `Creditability`=1 group by `Duration.of.Credit..month.` ")a2=sqldf( "select `Duration.of.Credit..month.`,count(1) from train_data where `Creditability`=0 group by `Duration.of.Credit..month.` ")
# 合并数据集
b1=cbind(a1,a2)
# 添加一列变量名称
b1[, 5]=colnames(b1)[ 1]
# 类型转换
b1=as.matrix(b1)
# 对Balance变量进行分组统计
a1=sqldf( "select `Account.Balance`,count(1) from train_data where `Creditability`=1 group by `Account.Balance` ")a2=sqldf( "select `Account.Balance`,count(1) from train_data where `Creditability`=0 group by `Account.Balance` ")b2=cbind(a1,a2) b2[, 5]=colnames(b2)[ 1]b2=as.matrix(b2)
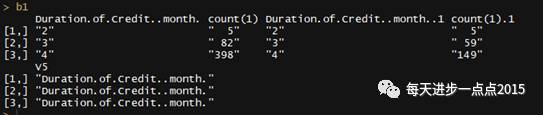
这样以此类推,把这些分组变量进行分组统计,这里就不再重复编写代码了。最后,需要把每个分组变量的统计结果进行合并。
# 合并结果
c=rbind(b1,b2,b3,b4,b5,b6,b7,b8,b9,b10,b11,b12,b13,b14,b15,b16,b17)
# 结构类型转换c <- as.data.frame(c)
#字段重命名
colnames(c) <- c( 'Bin', 'Good', 'Bin', 'Bad', 'Variable')
# 结果展现
c
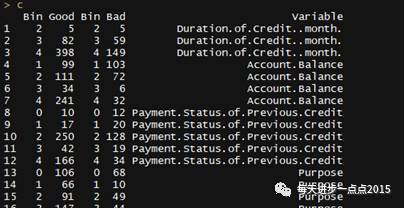
接下来还需要把数据框c中的Good变量和Bad变量的数据类型转换为数值型,用于后面的计算。
# 现在字符串再转数值
c$ 'Good'<- as.character(c$ 'Good')c$ 'Good'<- as.numeric(c$ 'Good')c$ 'Bad'<- as.character(c$ 'Bad')c$ 'Bad'<- as.numeric(c$ 'Bad')
# 各组好坏客户之和
c$ 'Total Number of Loans'<- c$Good+ c$Bad
# 各组坏客户的比例
c$ '% Bad Loans'<- c$Bad/c$ 'Total Number of Loans'
# train_data数据集中好客户和坏客户的数量分别是485和213
# 计算每组好客户占总的好客户的比例
c$ 'Distibution Good P(G)'<- c$Good/ 485
# 计算每组坏客户占总的好客户的比例
c$ 'Distibution Bad P(B)'<- c$Bad/ 213
# 好坏客户比例差异
c$ 'P(G) - P(B)'<- c$ 'Distibution Good P(G)'-c$ 'Distibution Bad P(B)'
#计算WOE
c$WOE <- log(c$ 'Distibution Good P(G)'/c$ 'Distibution Bad P(B)')
#计算IV
c$IV <- c$WOE*c$ 'P(G) - P(B)'
# 查看统计的c数据集
c

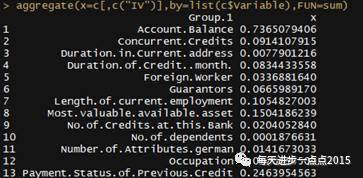
根据上面得到的数据框,对每组进行求和计算,得到总的IV值:
# 汇总计算
aggregate(x=c[,c( "IV")],by=list(c$Variable),FUN=sum)
#取出IV值比较大的变量
index5 <- which(c$Variable % in% c( 'Account.Balance', 'Duration.of.Credit..month.', 'Payment.Status.of.Previous.Credit', 'Purpose',
'Most.valuable.available.asset', 'Value.Savings.Stocks'))d <- c[index5,]
#算每个变量的最大,与最小WOE与其差值
f1 <- aggregate(x=d[,c( "WOE")],by=list(d$Variable),FUN=max)f2 <- aggregate(x=d[,c( "WOE")],by=list(d$Variable),FUN=min)f3 <- cbind(f1,f2)colnames(f3) <- c( 1, 'max', 1, 'min')f3

接下来我们再计算贝叶斯模型的评分:
f3$deff <- f3$max-f3$min
#将分数1设置为最大与最小差800分,分数1是用一个常量乘以WOE
ad <- 800/sum(f3$deff)d$Score1 <- d$WOE*add
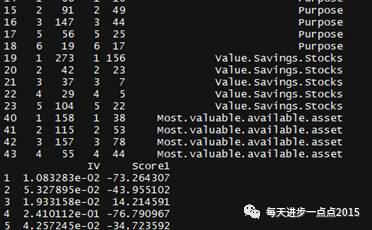
最后预测的总分为每个变量所在的Score1的和加上400分。
Logistic评分卡
同样,我们可以按照上面的逻辑,对Logistic模型构建评分卡:
# 数据类型转换
german_credit$Account.Balance <- as.character(german_credit$Account.Balance)german_credit$Duration.of.Credit..month. <- as.character.Date(german_credit$Duration.of.Credit..month.)german_credit$Payment.Status.of.Previous.Credit <- as.character(german_credit$Payment.Status.of.Previous.Credit)german_credit$Value.Savings.Stocks <- as.character(german_credit$Value.Savings.Stocks)german_credit$Purpose <- as.character(german_credit$Purpose)german_credit$Most.valuable.available.asset <- as.character(german_credit$Most.valuable.available.asset)
# 取出用IV值较大的变量
riskdata <- german_credit[,c( 'Creditability', 'Account.Balance', 'Duration.of.Credit..month.', 'Payment.Status.of.Previous.Credit', 'Purpose', 'Most.valuable.available.asset', 'Value.Savings.Stocks')] #取出WOE变量d1<- d[,c( 'Bin', 'WOE', 'Variable')]d1$Bin <- as.character(d1$Bin)name<-c ( 'Account.Balance', 'Duration.of.Credit..month.', 'Payment.Status.of.Previous.Credit', 'Purpose',
'Most.valuable.available.asset', 'Value.Savings.Stocks')
#将变量进行WOE转换
e1 <- d1[which(d1$Variable== 'Account.Balance'),]riskdata <- merge(riskdata,e1,by.y= 'Bin',by.x= 'Account.Balance')e1e2 <- d1[which(d1$Variable== 'Duration.of.Credit..month.'),]riskdata <- merge(riskdata,e2,by.y= 'Bin',by.x= 'Duration.of.Credit..month.')e2e3 <- d1[which(d1$Variable== 'Payment.Status.of.Previous.Credit'),]riskdata <- merge(riskdata,e3,by.y= 'Bin',by.x= 'Payment.Status.of.Previous.Credit')e4 <- d1[which(d1$Variable== 'Purpose'),]riskdata <- merge(riskdata,e4,by.y= 'Bin',by.x= 'Purpose')e5 <- d1[which(d1$Variable== 'Most.valuable.available.asset'),]riskdata <- merge(riskdata,e5,by.y= 'Bin',by.x= 'Most.valuable.available.asset')e6 <- d1[which(d1$Variable== 'Value.Savings.Stocks'),]
# 合并
riskdata <- merge(riskdata,e6,by.y= 'Bin',by.x= 'Value.Savings.Stocks')
# 得到WOE矩阵
riskdata <- riskdata[,c( 7, 8, 10, 12, 14, 16, 18)]
# 重命名
names(riskdata) <-c ( 'Creditability', 'Account.Balance', 'Duration.of.Credit..month.', 'Payment.Status.of.Previous.Credit', 'Purpose', 'Most.valuable.available.asset', 'Value.Savings.Stocks')riskdata
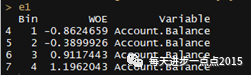
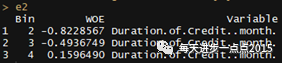

接下来,我们针对上面WOE矩阵(riskdata)构建Logistic模型:
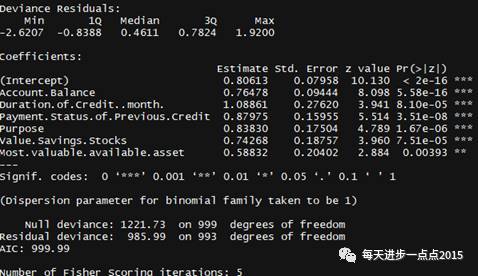
model_WOE<- glm(formula=Creditability~Account.Balance+Duration.of.Credit..month.+Payment.Status.of.Previous.Credit+Purpose+Value.Savings.Stocks+ Most.valuable.available.asset,data=riskdata,family = 'binomial')summary(model_WOE)
我们可以利用刚刚得到的Logistic模型计算评分:
# 取出回归系数
coefficients<-model_WOE$coefficients
# 计算分值
e1$Score2 <- e1$WOE*coefficients[ 2]e2$Score2 <- e2$WOE*coefficients[ 3]e3$Score2 <- e3$WOE*coefficients[ 4]e4$Score2 <- e4$WOE*coefficients[ 5]e5$Score2 <- e5$WOE*coefficients[ 6]e6$Score2 <- e6$WOE*coefficients[ 7]
# 和前面的NaiveScore分数计算方法保持一致
f <- rbind(e1,e2,e3,e4,e5,e6)f$Score2 <- f$Score2*adf
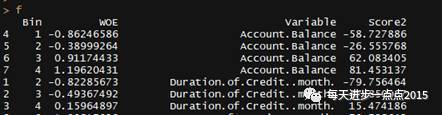
小结
OK,今天关于如何构造评分卡模型的内容就介绍到这里,希望对有需要的朋友能够带来帮助。关于本文涉及到的数据集和R语言脚本,可以从文末的链接获取。关注“每天进步一点点2015”,与小编同进步!
资料链接:
链接: https://pan.baidu.com/s/1nv7lm0x 密码: egim
感谢:
非常朋友黄升向“每天进步一点点2015”公众号投递原创性文章,同时也欢迎各位网友一起参与知识分享和交流。
参考资料:
http://blog.csdn.net/qq_16365849/article/details/67632776- 本文固定链接: https://maimengkong.com/morejc/1007.html
- 转载请注明: : 萌小白 2022年6月22日 于 卖萌控的博客 发表
- 百度已收录
