R语言中,apply族函数是非常重要的函数,它在很多场景下,可以代替循环语句,简化程序写作过程,实现高效的统计分析,因此我们称之为批量处理函数。利用apply族函数可将某函数作用到一系列数据对象上,包括标量、向量、矩阵、多维数组、数据框、列表。我们可以同时纳入多个向量、数据库、列表、变量,进行变量的转换、统计描述。 此外,apply函数另外一个优势是它可以批量开展自编或者系统自带函数的运算。
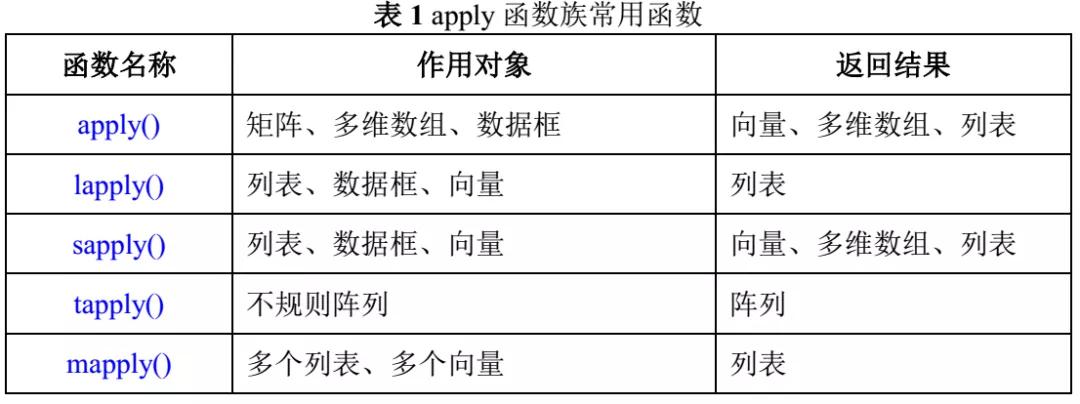
1. 函数apply()
对数据对象的一个维度,都作用上某函数,生成列表、多维数组或向量。基本格式为:
apply(x, MARGIN=..., fun, ...)
其中,x为数据对象(矩阵、多维数组、数据框);MARGIN=1表示按行,2表示按列;fun表示要作用的函数。
通常来说,apply函数经常用来计算矩阵中行或列的均值、和值的函数。
> x<-matrix(1:6,ncol=2)
> x
[,1] [,2]
[1,] 1 4
[2,] 2 5
[3,] 3 6
> apply(x,1,mean) #按行求均值
[1] 2.5 3.5 4.5
> apply(x,2,mean) #按列求均值
[1] 2 5
2. 函数lapply()
对数据对象的每一个元素,都作用上某函数,生成一个与元素个数相同的值列表。基本格式为:
lapply(x, fun, ...)
其中,x为数据对象(列表、数据框、向量)。
lapply对每列进行操作,非常适合数据框;在R中数据框是一种特殊的列表,所以数据框的列也将作为函数的处理对象。
> x<-list(a=1:5,b=exp(0:3))
> x
$a
[1] 1 2 3 4 5
$b
[1] 1.000000 2.718282 7.389056 20.085537
> lapply(x,mean)
$a
[1] 3
$b
[1] 7.798219
3. 函数sapply()
基本格式为:
lapply(x, fun, ..., simplify=TRUE, USE.NAMES=...)
比函数lapply()多了一个参数simplify,若simplify=FALSE,则同lapply();若为TRUE,则将输出的list简化为向量或矩阵;若USE.NAMES为TRUE,且x为字符型,则用x作为结果的名称。
simplify=F:返回值的类型是list,此时与lapply完全相同
simplify=T(默认值):返回值的类型由计算结果定,如果函数返回值长度为1,则sapply将list简化为vector;
> sapply(x, mean, simplify = TRUE) #x同上例
a b
3.000000 7.798219
> list<-list(c("a","b","c"),c("A","B","C"))
> list
[[1]]
[1] "a" "b" "c"
[[2]]
[1] "A" "B" "C"
#将列表list中的元素与数字1~3连接
> sapply(list, paste, 1:3, simplify = TRUE)
[,1] [,2]
[1,] "a 1" "A 1"
[2,] "b 2" "B 2"
[3,] "c 3" "C 3"
> sapply(list, paste, 1:3, simplify = FALSE)
[[1]]
[1] "a 1" "b 2" "c 3"
[[2]]
[1] "A 1" "B 2" "C 3"
4. 函数tapply()
对不规则阵列,对照一组确定因子作用某函数。基本格式为:
tapply(x, INDEX, fun, ..., simplify=TRUE)
其中,x通常为向量;INDEX为与x长度相同的因子列表(若不是因子,R会强制转化为因子);simplify=TRUE(默认)且fun计算结果为标量值,则返回值为数组,若为FALSE,则返回值为list对象。
x是需要处理的向量,INDEX是因子(因子列表),FUN是需要执行的函数,simplify指是否简化输入结果(考虑sapply对于lapply的简化)
x可以是数据库的一个变量,也可以是单独的向量。
> height<-c(174,165,180,171,160)
> sex<-c("F","F","M","M","F")
> tapply(height,sex,mean) #计算不同sex对应的height的均值
F M
166.3333 175.5000
5. 函数mapply()
是函数sapply()的多变量版本,将对多个变量的每个参数作用某函数。基本格式为:
mapply(fun, MoreArgs=NULL, SIMPLIFY=TRUE, USE.NAMES=TRUE)
其中,MoreArgs为fun函数的其它参数列表;SIMPLIFY为逻辑值或字符串,取值为TRUR时,将结果转化为一个向量、矩阵或高维阵列(但不是所有结果都可转化)。
#重复生成列表list(x=1:2), 重复次数times=1:3,结果为列表
> mapply(rep, times=1:3, MoreArgs = list(x=1:2))
[[1]]
[1] 1 2
[[2]]
[1] 1 2 1 2
[[3]]
[1] 1 2 1 2 1 2
#重复生成列表list(x=1:2), 重复次数times=c(2,2),结果为矩阵
> mapply(rep, times=c(2,2), MoreArgs = list(x=1:2))
[,1] [,2]
[1,] 1 1
[2,] 2 2
[3,] 1 1
[4,] 2 2
6. 医学数据分析中apply族的应用
对于医学数据而言,实际上很多情况我们不太会把所有的行,或者所有的列求一个均数或者求一个中位数,但是其它函数就会用的比较多。比如,我们要看看各个变量的缺失值数据,比如把很多数值变量因子化。
我们先导入数据库elder1和elder2
t1<-read_csv("elder1.csv")
t2<-read_csv("elder2.csv")
查看变量的类型
sapply(t1,class)
是不是都是数字变量呢
sapply(t1,is.numeric)
把部分变量转为因子
vars<-c(“sex”,”marriage”,”education”,”huji”,”income”,”smoking”)
t2[vars] <- lapply(t2[vars], factor)
分组计算均数
tapply(t2$health,t2$sex,mean, na.rm = TRUE)
分组计数
tapply(t2$marriage,t2$sex,table)
看看到底各变量有多少缺失值
naf<-function(x){
nas<-sum(is.na(x))
return(nas)
}
apply(t1,2, naf)
这段程序就是自编与apply族函数的联合。光apply族函数无法直接计算每一个变量的缺失值个数,但是我们用自编函数把is.na ()和sum()进行整合,形成新的函数naf,那么我们就可以进行批量操作了。
Apply族函数无论是在变量转换、数据统计描述甚至是统计分析,都具有一定的价值。它的批量作业法使它变成R语言非常重要系列函数。
DAY13的内容就介绍到这里!
转自:医学论文与统计分析
- 本文固定链接: https://maimengkong.com/kyjc/972.html
- 转载请注明: : 萌小白 2022年6月4日 于 卖萌控的博客 发表
- 百度已收录
