数据结构的塑造是数据可视化前重要的一环,虽说本公众号重心在于数据可视化,可是涉及到一些至关重要的数据整合技巧,还是有必要跟大家分享一下的。
在可视化前的数据处理技巧中,导入导出、长宽转换已经跟大家详细的介绍过了。
今天跟大大家分享数据集的合并与追加,并且这里根据所依赖函数的处理效率,给出诺干套解决方案。
数据合并操作涉及以下几个问题:
横向合并;
1. 是否需要匹配字段
1.1 匹配字段合并
1.1.1 主字段同名
1.1.2 主字段不同名
1.2 无需匹配字段合并
纵向合并:(情况比较简单,列字段数量相同,名称相同)
因为纵向合并情况比较简单,所以本篇讲解也着重以横向合并为主,按照以上几个问题,需要用到的函数列举如下:
cbind rbind merge plyr::join tidyr:: inner_join/full_join/left_join/right_join
首先介绍base内置的两三个函数:
cbind rbind merge
###横向追加(无需匹配字段)
数据集构造如下:
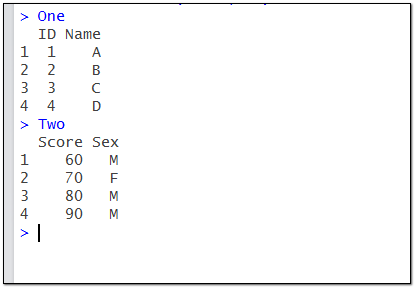
ID<-c(1,2,3,4)
Name<-c("A","B","C","D")
Score<-c(60,70,80,90)
Sex<-c("M","F","M","M")
One<-data.frame(ID,Name)
Two<-data.frame(Score,Sex)
合并:
Total<-cbind(One,Two)
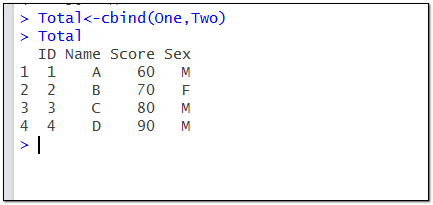
可以看到cbind函数横向合并无需匹配主字段,仅仅是将两个数据集横向拼接在一起。
###纵向合并
构造数据集:
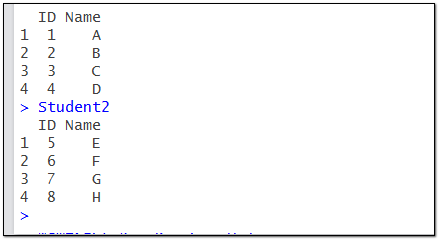
ID<-c(1,2,3,4)
Name<-c("A","B","C","D")
Student1<-data.frame(ID,Name)
ID<-c(5,6,7,8)
Name<-c("E","F","G","H")
Student2<-data.frame(ID,Name)
合并:
Total_student3<-rbind(Student1,Student2)
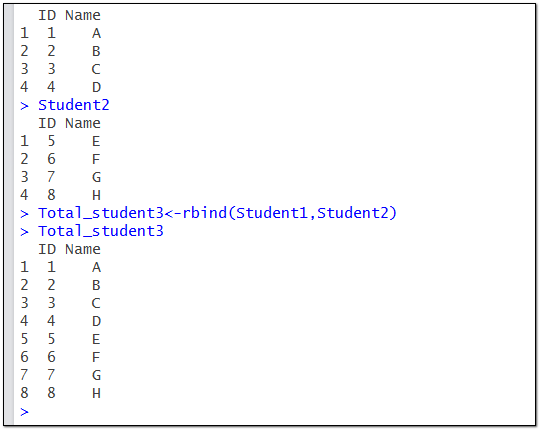
以上通过rbind函数对Student1,Student2两个数据集进行纵向合并(也称追加)。
merge函数:
merge函数主要针对横向(列字段)合并,而且可以针对主字段(主键)进行匹配,如果主字段名称不同,还可以指定前后相匹配的主字段。
基本语法如下:
merge(x, y, by = , by.x = , by.y = , all = , all.x = , all.y = , sort = , suffixes = , incomparables = , ...)
具体参数解释如下:

接下来按照名相同与不同分两种情况介绍;
列名相同:
ID<-c(1,2,3,4)
name<-c("A","B","C","D")
score<-c(60,70,80,90)
student1<-data.frame(ID,name)
student2<-data.frame(ID,score)
total_student1<-merge(student1,student2,by="ID")
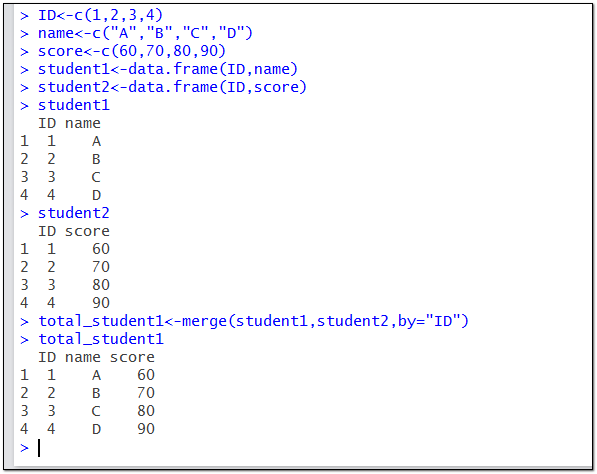
#以上两个数据集有相同的列名(ID)时,by参数可以省略(by="ID")
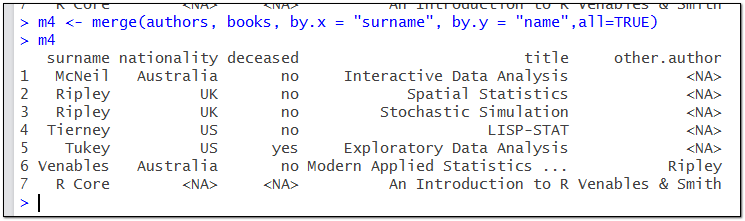
以上两个数据集中,authors和books中有相同属性的主字段(surname&name)但是主字段名称不同,这里需要给merge函数指定匹配的主字段。
横向合并的四种类型:
#inner(内部链接)只合并交集
m1 <- merge(authors, books, by.x = "surname", by.y = "name")
#left join(左连接)
m2 <- merge(authors, books, by.x = "surname", by.y = "name",all.x=TRUE)
#right join(右连接)
m3 <- merge(authors, books, by.x = "surname", by.y = "name",all.y=TRUE)
#all_join(外连接)
m4 <- merge(authors, books, by.x = "surname", by.y = "name",all=TRUE)




plyr::join函数
join函数源于plyr包(该包作者就是大名鼎鼎的Hadley Wickham,就是ggplot2的开发者,当然它开发的包还有很多),使用前需要加载:
以下是该函数语法:
join(x, y, by = NULL, type = "left", match = "all")
当两个数据集主字段有相同名称时,by参数可以省略(by="name"),当名称不同时,需指定左右两个数据集匹配的主字段名称。
join(x,y,by=intersect("Name","name"),type = "left")
以下我只演示相同主字段名称下的四种类型合并语句:
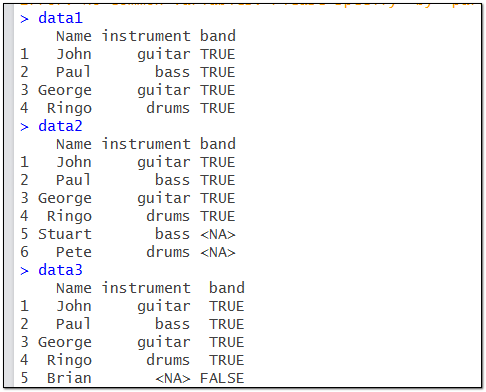
构造待合并数据集:
x<-data.frame(name=c("John","Paul","George","Ringo","Stuart","Pete"),instrument=c("guitar","bass","guitar","drums","bass","drums"))
y<-data.frame(name=c("John","Paul","George","Ringo","Brian"),band=c("TRUE","TRUE","TRUE","TRUE","FALSE"))

#left_join
data1<-join(x,y,by="name",type = "left")
#right_join
data2<-join(x,y,by="name",type = "right")
#inner_join
data3<-join(x,y,by="name",type = "inner")
#full_join
data4<-join(x,y,by="name",type = "full")


合并函数与merge函数基本相同。
dplyr::inner_join/full_join/left_join/right_join
(告诉你一个不幸的消息,该包作者还是Hadley Wickham,没办法,一个赢者通吃的时代,谁让人家有才任性呢哈哈~_~)
dplyr的数据合并语句要比plyr还要精练:
x<-data.frame(Name=c("John","Paul","George","Ringo","Stuart","Pete"),instrument=c("guitar","bass","guitar","drums","bass","drums"))
y<-data.frame(name=c("John","Paul","George","Ringo","Brian"),band=c("TRUE","TRUE","TRUE","TRUE","FALSE"))

#(1)inner_join(x, y) :只包含同时出现在x,y表中的行
data1<-inner_join(x,y,by=c("Name"="name"))
#(2)left_join(x, y) :包含所有x中以及y中匹配的行
data2<-left_join(x,y,by=c("Name"="name"))
#(3)right_join(x, y,by=c("Name"="name")) :包含所有y中以及x中匹配的行
data3<-right_join(x,y,by=c("Name"="name"))
#(4)full_join(x,y,by=c("Name"="name")) :包含所以x、y中的行
data4<-full_join(x,y,by=c("Name"="name"))
#(5)semi_join(x, y) :包含x中,在y中有匹配的行,结果为x的子集
data5<-semi_join(x,y,by=c("Name"="name"))
#(6)anti_join(x, y) :包含x中,不匹配y的行,结果为x的子集,与semi_join相反
data6<-anti_join(x,y)

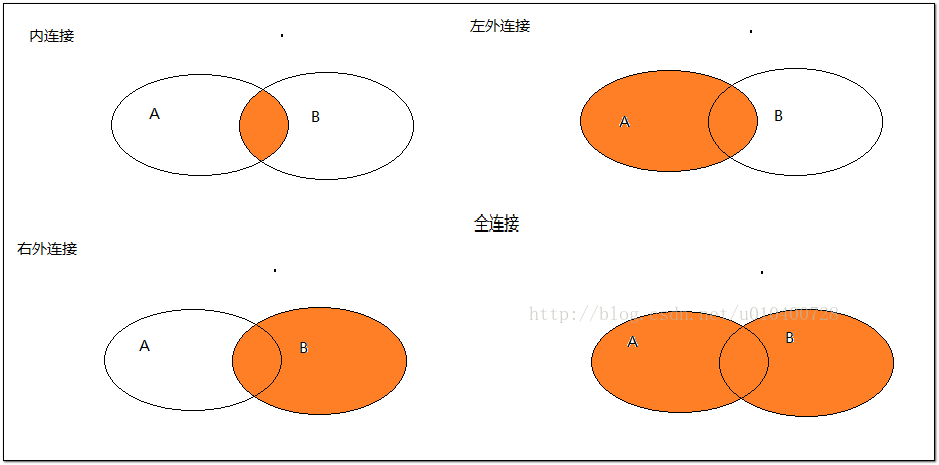
以上连接类型中,前四个(内连接、外连接、左连接、右连接)最为常用,大家可以将dplyr和plyr以及merge函数三种连接方式进行对比记忆。
下面聊一列为啥要专门讲一节数据连接方式:
因为……
在excel中……
这种数据连接真的……真的……真的……太费劲了
我所知道的连接方式——
第一:手动复制黏贴;(大家不要随便作死)
第二:最古老的Microsoft Query(藏在excel数据导入菜单的最底层,据说微软也不更新了,如果的excel是精简版的,可能都没法调用,菜单特丑)
第三:数据透视表;Alt+D+P(为啥微软要把调用数据透视表多表合并的菜单隐藏起来只能用快捷键,太烦人了)
第四:微软的最新商务智能应用——PowerBI(其中的PowerQuery、PowerPivot)
第五:第三方的效率插件(很多VBA大神写过这些办公插件,但是我就不爱用,多装一个,Excel启动拖后两秒钟,时间就是金钱啊你说是不)
以上四种方式(第一种除外),虽说都可以完成数据合并操作,但是效率上不敢恭维,每次都得走一遍菜单流程。如果有点R语言基础的同学,强烈建议将这些操作放在R中操作,数据导入导出、长宽转换、横纵合并,只需修改一下代码路径、参数分分钟搞定。
当然对于有数据库基础的同学(相信大部分同学都有吧,应该是大学本科的必修课)来讲,写几个SQL也可以瞬间完成。
虽然已经N多年没有用过了,但是还是想在这里献丑一下:
内连接 inner join
语法:select * from x inner join y on x.Name =y.name
左连接 left join(左表中所有数据,右表中对应数据)
语法:select * from x left join y on x.Name = y.name
右连接 right join(右表中所有数据,左表中对应数据)
语法:select * from x right join y on x.Name = y.name
全连接 full join
语法:select * from x full join y on x.Name = y.name
我是一个比较懒、嫌麻烦但注重效率的人,很多关于数据处理上的需求,如果能用简单的方式解决(比如VBA、R或者效率函数),我都不会去选择安装插件或者外部软件,一方面太浪费时间,操作麻烦;另一方面,使用插件大多需要用菜单点选,以后遇到同样的需要还得从新走一遍流程,所以我更倾向用简单的可重复利用的代码来解决。
简单、省事儿、快捷、可重复……
- 本文固定链接: https://maimengkong.com/kyjc/819.html
- 转载请注明: : 萌小白 2021年12月26日 于 卖萌控的博客 发表
- 百度已收录

网友评论(1)