微生物多样性或者宏基因组分析中,往往有几个出现频率很高的词,比如 OTU,群落结构,alpha多样性, beta多样性。今天就来通过分析思路上(主要围绕微生物多样性)给大家解释一下这些高频词汇。
一、OTU分类
OTU[1]全称为Operational Taxonomic Unit, 直译过来是操作分类单元,其实是人为进行定义的分类单元, 即一般是在微生物多样性分析中,对序列以97%的相似度进行Cluster聚类。
微生物的研究我们往往是在生境(例如人体肠道样本,可以把肠道环境就是一个生境; 又如某一区域土壤取样,可以把区域土壤看做一个生境)的群落结构层面来关注。而类似生境下的群落构成是有极大的相似性的。
所以多样性研究的方法是: 首先对所有样本的valid tags(tags这里指双端reads拼接后的序列)以97%相似度进行cluster聚类,分类OTU。例如9万条tags可能cluster到2000个OTU单元。然后从每个OTU分类单元中挑选序列最长的或者是Abundance最大的作为代表序列。通过这2000个代表序列和数据库比对并进行注释。
基于OTU水平可展示的分析有:
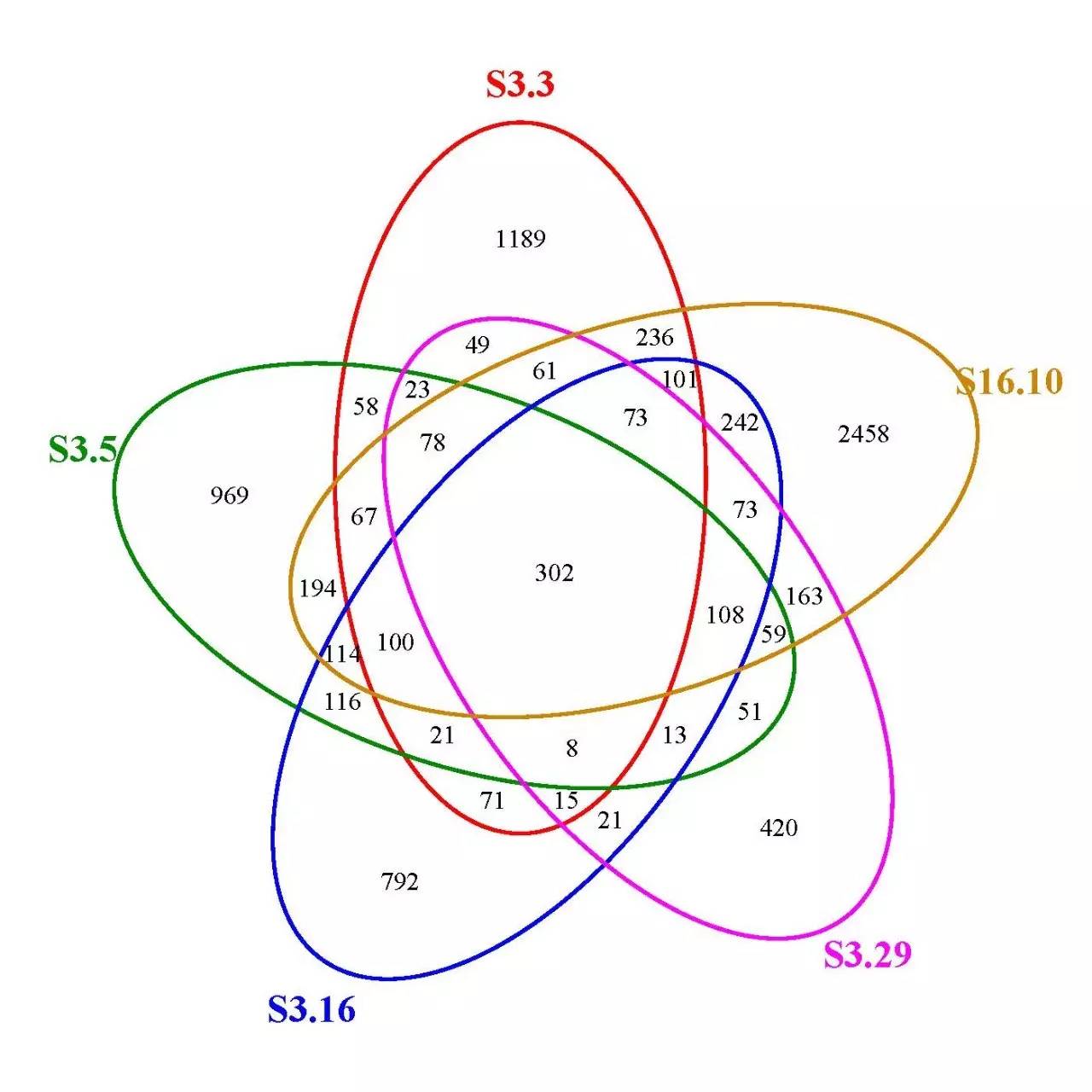
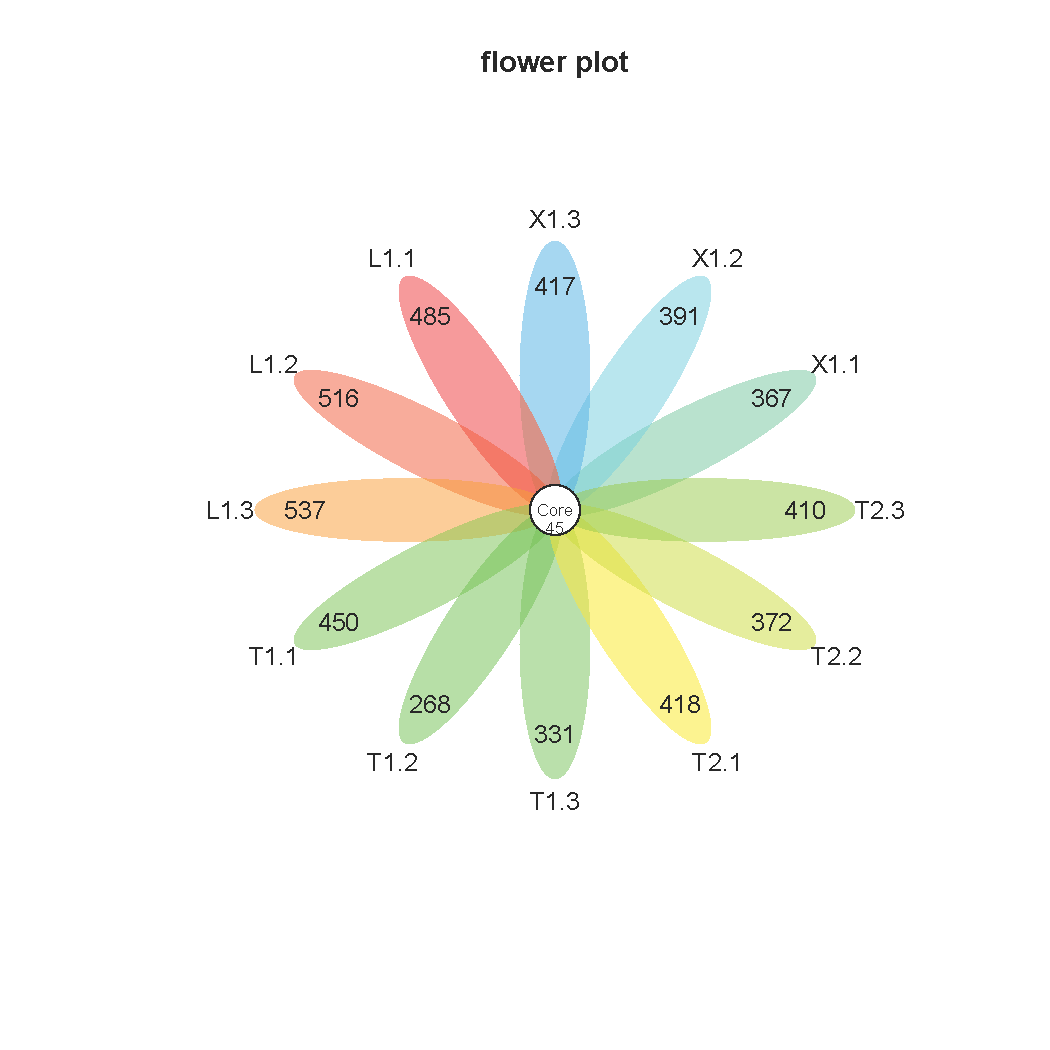
1. 基于OTU的venn图和花瓣图: 可以统计不同样本或者分组间特有的OTU和共有的OTU。
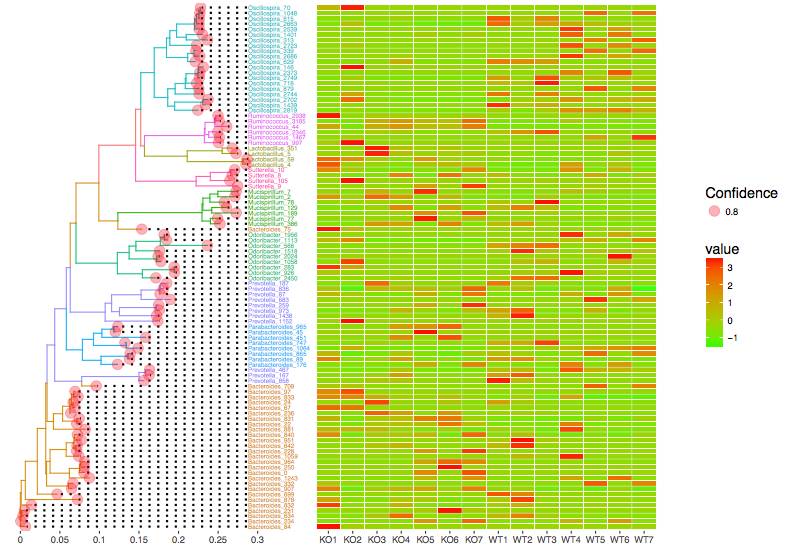
2. 基于OTU代表序列的系统发育树构建: 可以挑选出丰度较高的OTU,并构建这些OTU的系统发育树,并辅助Heatmap结果展示。相对高低丰度OTU在不同样本或分组一目了然。
3. 基于OTU的热图: 可以直观展示OTU在不同样本或者分组的丰度差异。

二、群落结构
community structure即群落结构[2]。 生境内微生物环境可以看做一个大的生态生物群落,而这些群落是由各种优势菌属以及低丰度菌属构成,不同生境的微生物种类以及微生物的丰度是不同的,而这些多种类不同丰度的菌属的构成就可以理解为生境的群落结构。
一般进行群落结构分析,可以从几个角度来入手:
1. 群落结构分布柱状图: 可以展示不同样本或者分组整体群落的构成,以及构成之间的差异。
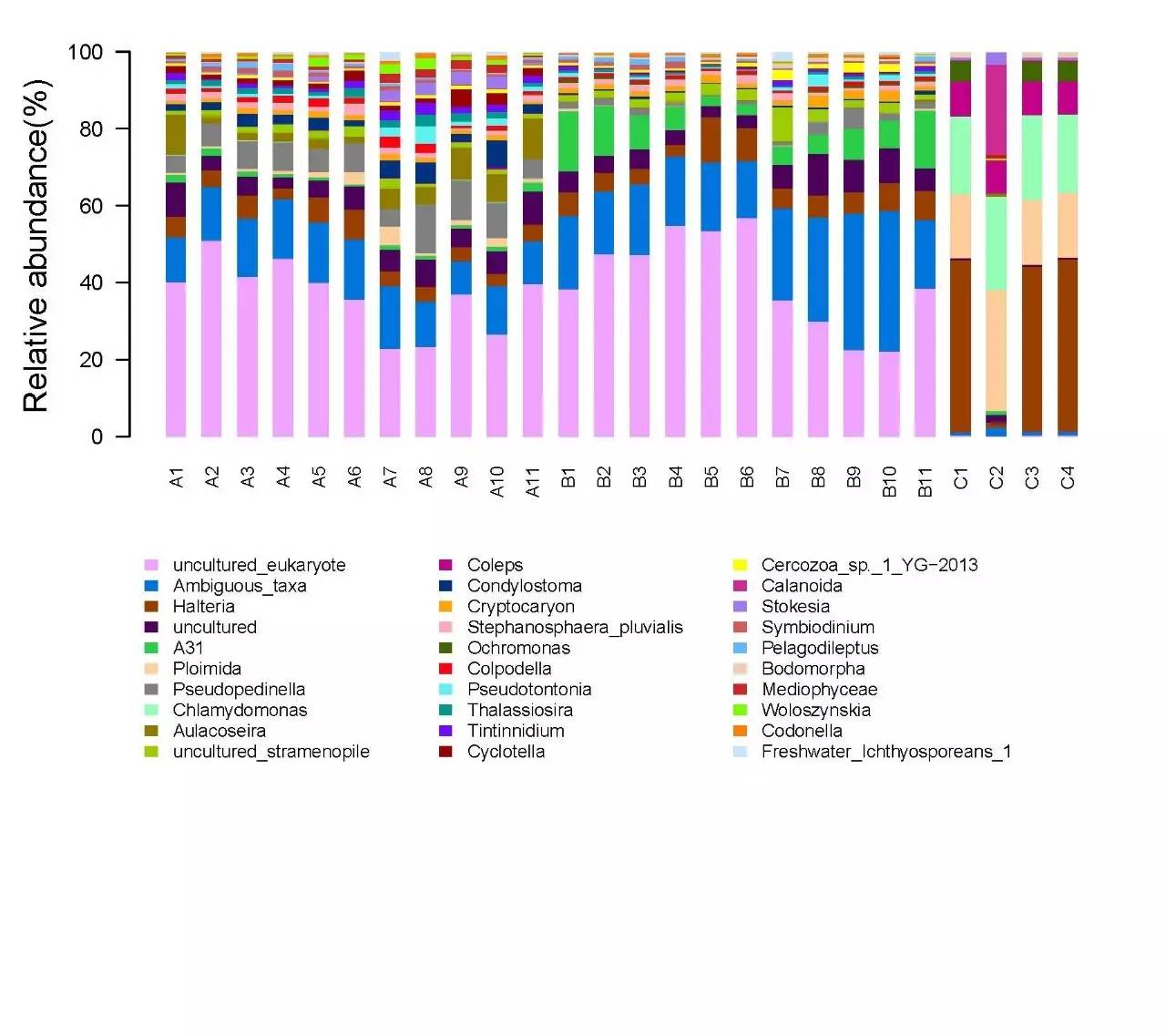
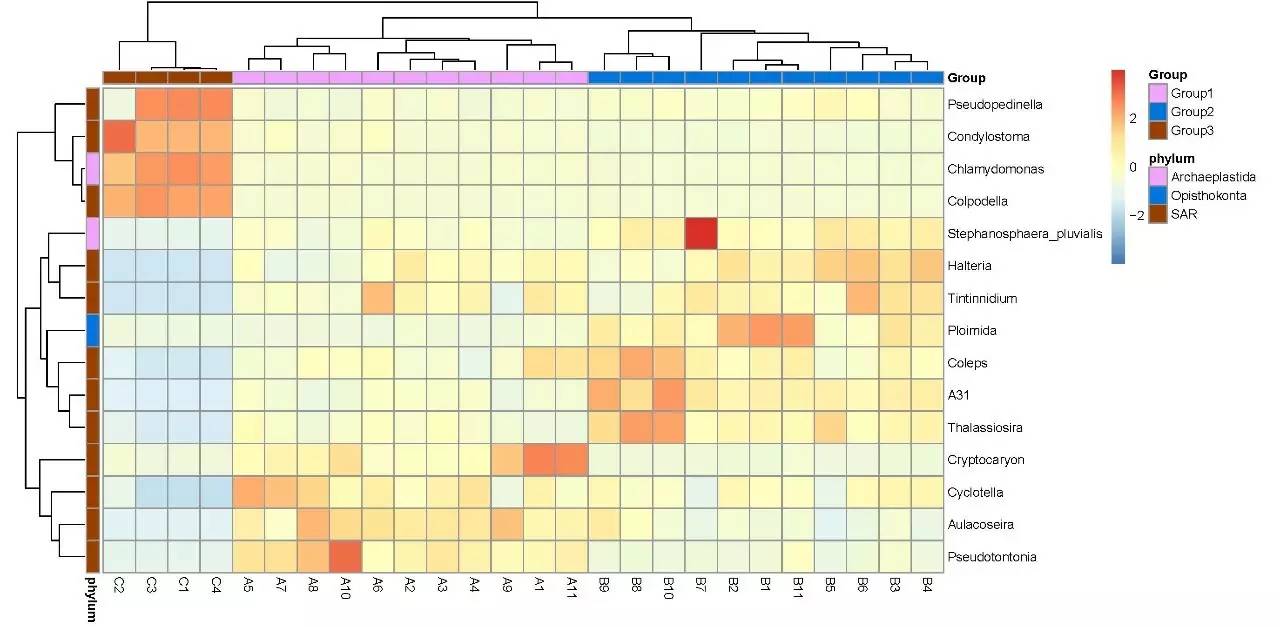
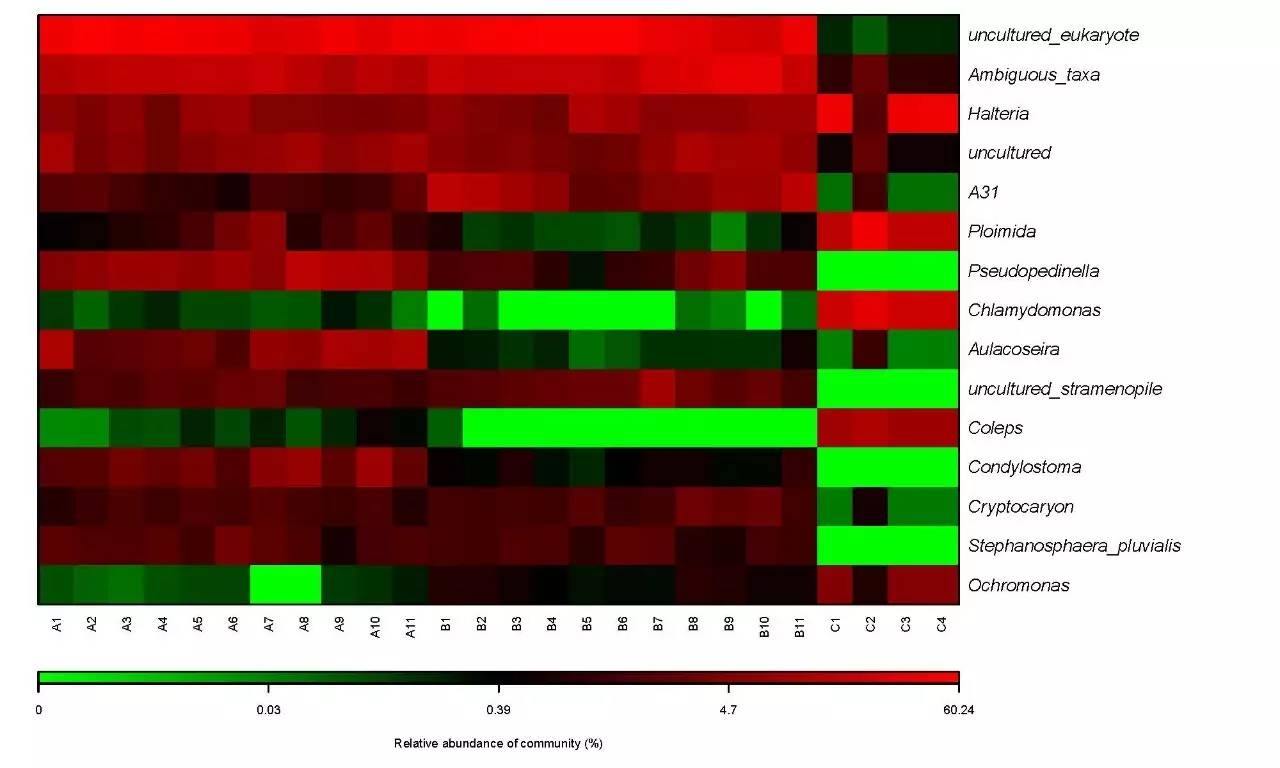
2. 群落结构分布Heatmap图: 可直观展示物种在门纲目科属水平的丰度高低。
三、alpha多样性
alpha、beta多样性均来源于生态学,可以理解为两个不同的空间尺度。alpha多样性一般指生境内物种的多样性程度,即不侧重于比较,而只是评估生境内的多样性程度,而beta多样性侧重于对不同生境的多样性进行比较。
alpha多样性有很多评估指数:observed species即观测到的OTUs数目、shannon香农指数[3]、simpson[4]指数、chao[5]指数、ACE指数等等……
不同指数的侧重点不同,以及计算公式也是不同。总的来说:Observed species即为分类OTUs的数目;Shannon指数可同时反映群落的物种多样性高低以及均匀度;Chao指数算法是通过计算群落中只检测到1次和2次的OTU数目来估计群落中实际存在的物种数。因此该指数对于痕量菌(低丰度物种)相对比较敏感。
alpha多样性分析可以从哪几个角度来展示呢?
1. 可以计算出各个指数的数值,例如长这样:

得到这样一张指数表格,就可以评估出样本的多样性程度。当然如果需要从指数数值上对不同样本的多样性程度或者均匀度进行比较,可以首先对各个样本中的序列进行随机抽齐操作,在同等的测序量下,比较样本间的多样性指数高低。
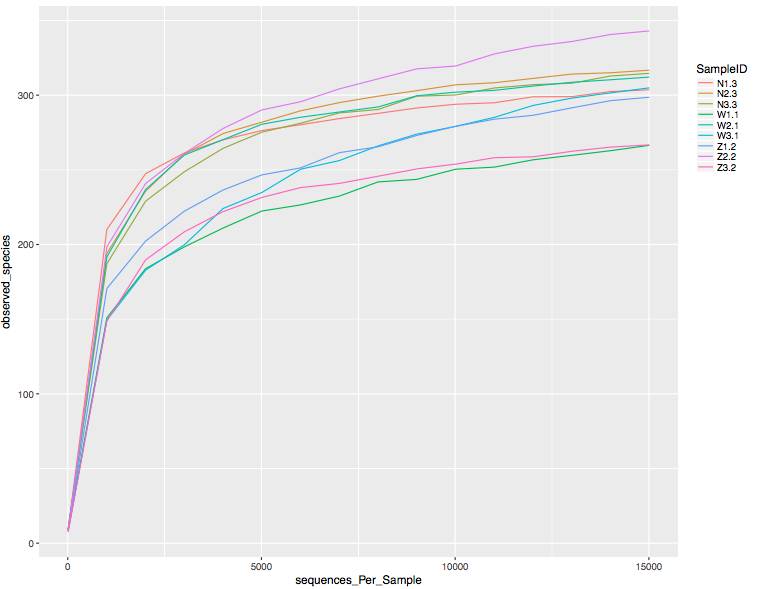
2. 可以通过多样性指数对测序的饱和度进行评估。例如下图为稀释曲线,纵坐标为observed species即观测OTU的个数,横轴为对序列集进行随机抽样的抽样深度。稀释曲线展示的为在不同抽样深度下构建OTU的个数。该曲线可以对测序饱和度做一个初步评估,如果最终曲线趋于水平,代表当前的测序量饱和度足够。
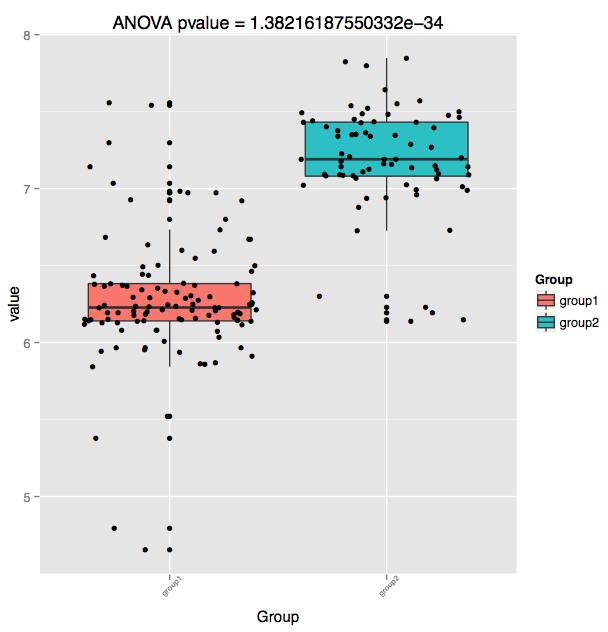
3. 同时可以比较不同处理组的多样性指数是否在两组间有显著性差异。如下图,为2组(182个)样本的shannon指数Boxplot图。箱线图上的每个点代表一个样本。通过ANOVA差异统计方法,计算出两组的shannon指数差异p value为1.38*10-34。
四、beta多样性分析
beta多样性侧重于不同生境的群落构成的比较。常用于展示beta多样性的分析方法有:
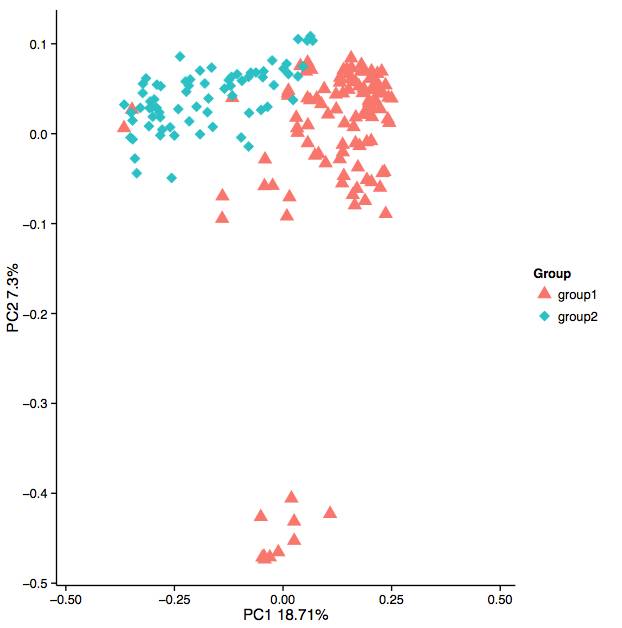
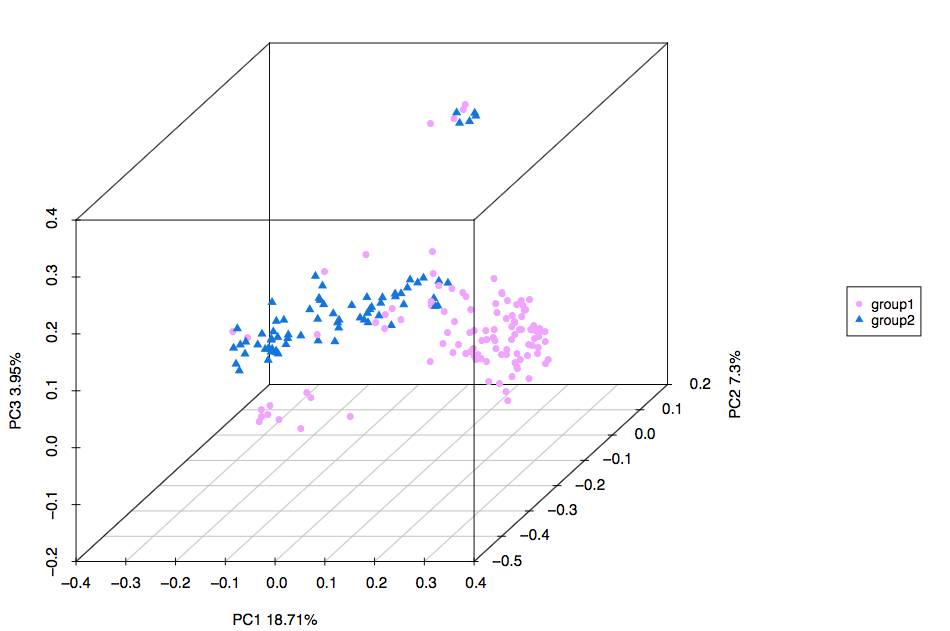
1. PCA[6]主成分分析。主成分分析是一项基于线性分析的模型,并不依赖于距离矩阵算法。
2. 基于距离矩阵算法的PCoA[6]分析以及NMDS分析。 与PCA主成分分析不同,PCoA以及NMDS可以通过不同的矩阵算法(Unweighted Unifrac、 Weighted Unifrac、 Bray Curtis、Binary Jaccard、 Euclidean等等)来比较样本间的相似性。
3. RDA/CCA分析。即冗余分析(Redundancy analysis,RDA)、典型相关分析(Canonical analysis)。 即引入了环境因子的变量,通过菌群结构数据与某种给定的因素互相拟合,通过置换检验来探寻样本、物种、环境两两之间的关系,或者三者之间的关系。
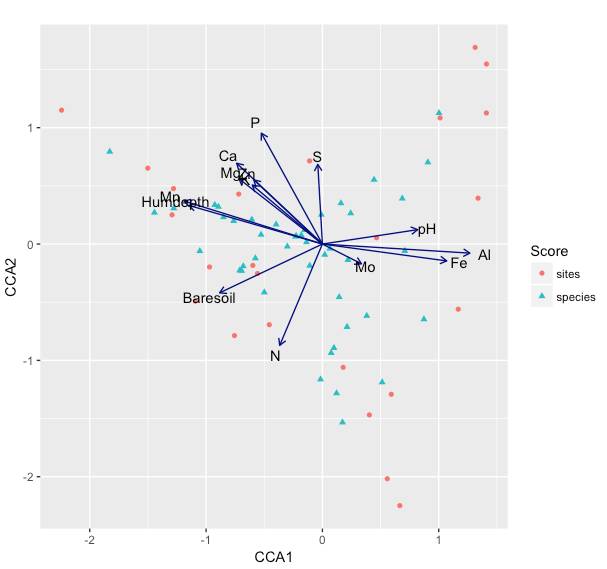
但是这么多beta多样性比较的算法,应该怎么取舍呢? 微生物多样性研究一般建议结合实验设计,考虑多种矩阵算法,选取最合适的一种。例如Unifrac距离有权重和非权重方法,非权重方法侧重于只考虑物种有无,即群落物种种类差异;而权重算法不仅考虑物种有无,也会考虑物种丰度的高低。而有些处理因素主要会引起微生物物种丰度的变化,这种情况下可能更适合于权重算法。
五、统计分析(差异统计或者分类)
微生物多元变量统计分析,即根据不同的分组寻找组间差异物种,或者寻找不同处理组的biomarker。 统计分析有基于物种丰度(ANOVA、G_test、Metastat等),也有基于距离矩阵(Adonis、ANOSIM等)的算法。同时也可分为参数检验的统计方法以及非参数检验统计算法。
另外还有一些对于分类评估的统计,例如ROC曲线分析。以及其他的一些统计方法: 随机森林分布、LEfSe分析等。(想了解LEfSe分析么?想自己来做分析么? 请点击以往微信文章:【干货】微生物高分文章必备分析LEfSe)
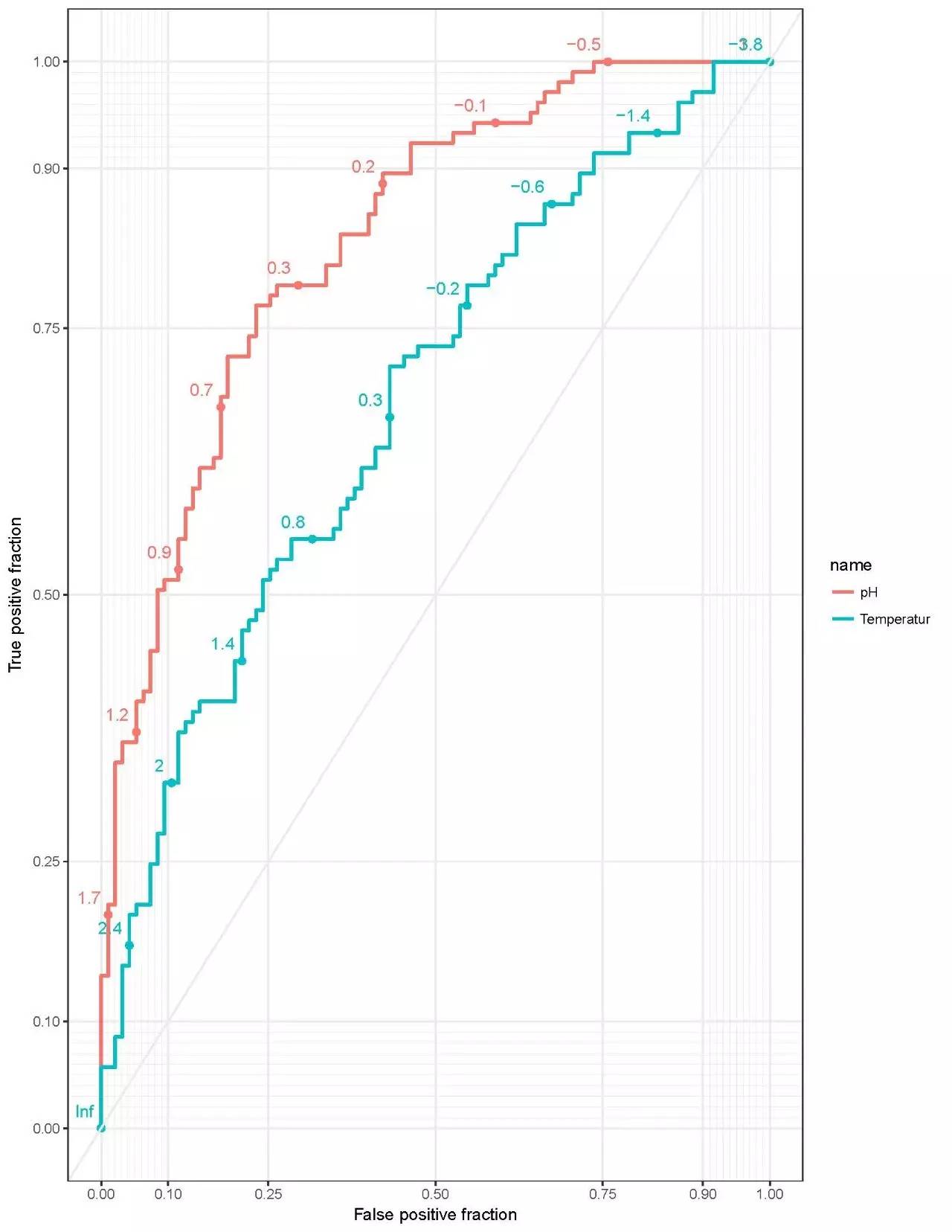
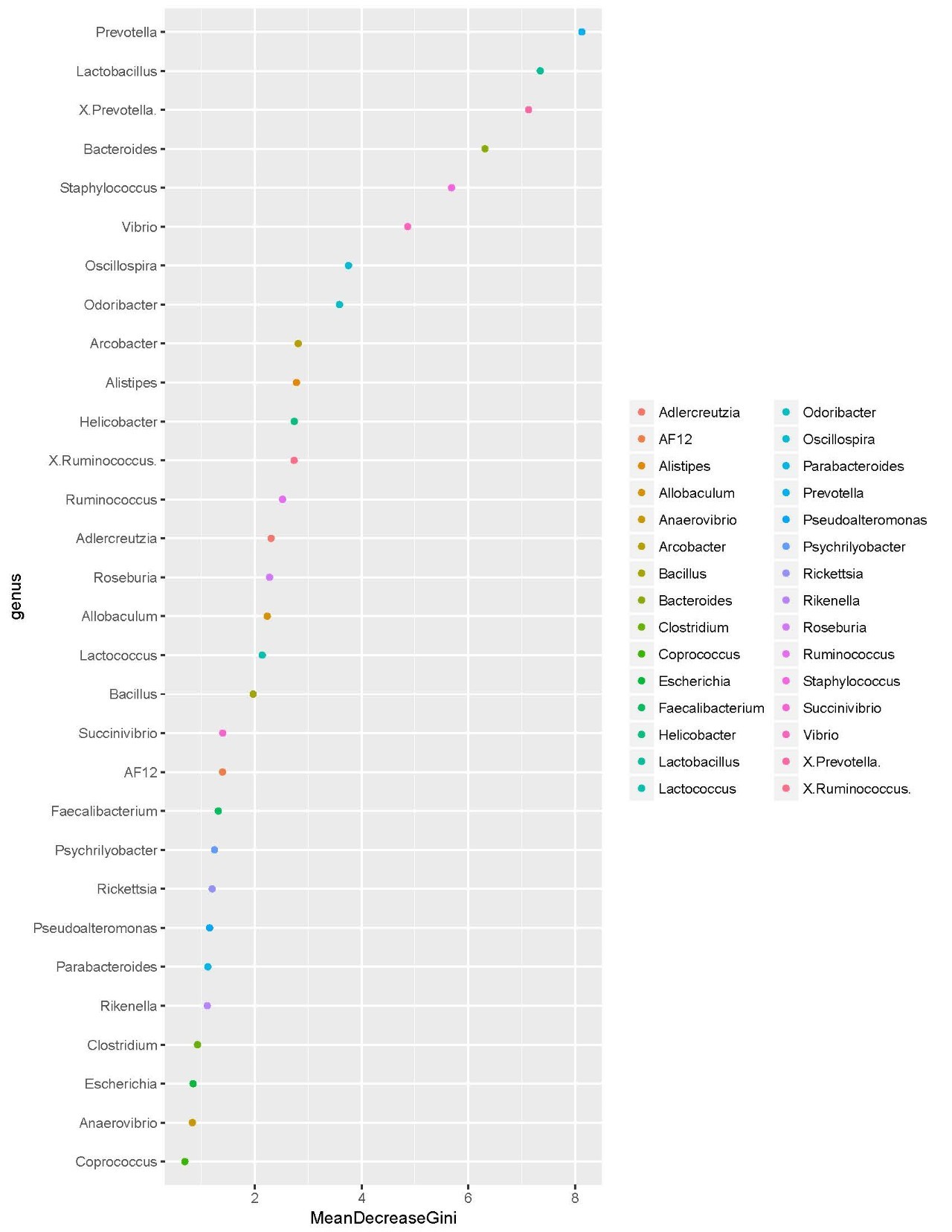
上图1为ROC[7]分析,即可以对于分类进行评估,例如在土壤不同pH值因素以及不同温度的因素下,通过群落物种分布评估这两个处理下的分类效果。如果ROC曲线大于0.5说明分类效果较好。上图2为通过随机森林分布(Random Forest)[8]算法挑选出来的对于分组贡献度最大的30个物种,并根据这30个物种的贡献度权重高低进行排序。
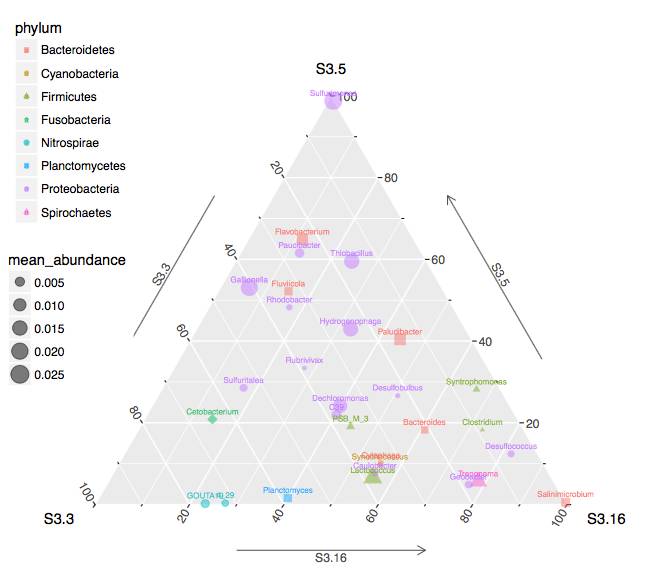
又例如优势物种间相关性计算以及网络图的绘制:

上图中节点代表各优势菌属,以不同的颜色标识,节点之间的连接表明两个属之间存在相关性,红线表明正相关,绿线(灰色线)表明负相关,线的粗细代表相关性高低。相同颜色的点,代表这些属均分类为相同的门。通过某节点的连接越多,表明该属于菌群中其它成员的关联越多。
通过以上的信息,不知道各位对于多样性的分析有没有更了解一些了呢?藏货很多,
今天只是一个粗略的分享,并且在这些高频“词汇“下其实还隐藏有很多更深的问题,值得我们去一一探讨。例如还有一些更为延伸的研究方向例如:Picrust功能预测(点击以往文章了解:微生物16S高分文章必备之-PICRUSt功能预测 瞬间提高微生物多样性研究性价比)、Enterotypes肠型分析、基于OTU或者宏基因组基因集的WGCNA分析等等。
[1] Blaxter M, Mann J, Chapman T, et al. Defining operational taxonomic units using DNA barcode data.Philosophical Transactions of the Royal Society of London, 2005, 360(1462): 1935-1943.
[2]Girvan M, Newman M E. Community structure in social and biological networks.[J].Proceedings of the National Academy of Sciences of the United States of America, 2002, 99(12):7821.
[3]Chao A, Shen T J. Nonparametric estimation of Shannon's index of diversity when there are unseen species in sample[J]. Environmental and Ecological Statistics, 2003, 10(4):429-443.
[4]Simpson EH. Measure of diversity.Nature, 1949, 163: 688.
[5]Chao A. Non-parametric estimation of the classes in a population. Scandinavian Journal of Statistics, 1984, 11(4): 265-270.
[6] Ramette A. Ramette A. Multivariate analyses in microbial ecology. FEMS MicrobiolEcol62: 142-160[J]. 2007, 62(2):142-160.
[7] Fawcett T. An introduction to ROC analysis[J]. Pattern Recognition Letters, 2006, 27(8):861-874.
[8] Breiman L. Random Forests[J]. Machine Learning, 2001, 45(1):5-32.
- 本文固定链接: https://maimengkong.com/kyjc/584.html
- 转载请注明: : 萌小白 2020年1月27日 于 卖萌控的博客 发表
- 百度已收录
