转录组测序中,常见的几种reads count值的标准化方法,基于测序深度和基因长度进行标准化。
 RPKM、FPKM和TPM标准化
RPKM、FPKM和TPM标准化
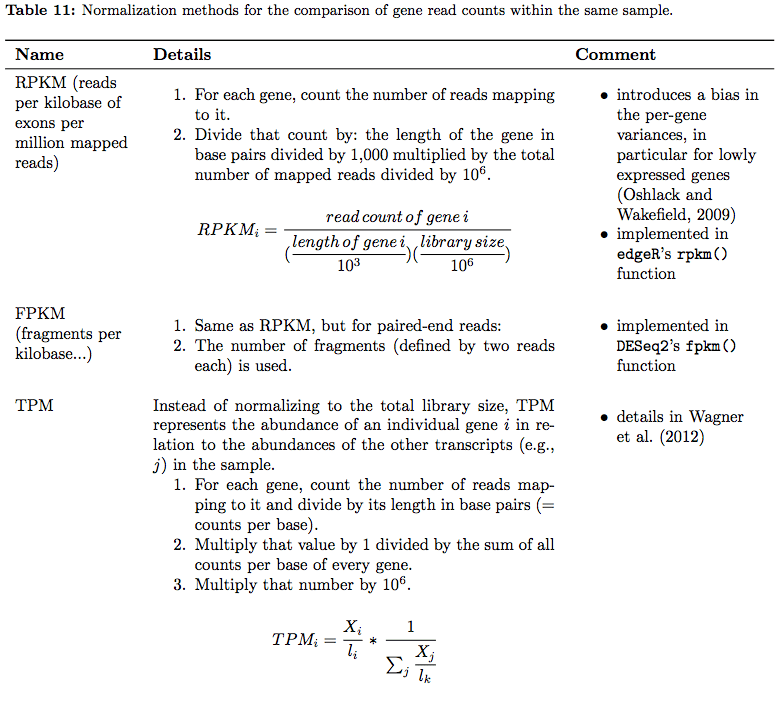
RPKM(Reads Per Kilobase Million)计算方法:
- 计算样本中的总reads数,然后将其除以1000000,获得百万缩放因子。
- 将每个基因的reads count值,除以百万缩放因子标准化测序深度,获得每百万reads中来自该基因的reads比例(reads per million,RPM)。
- 将RPM值除以基因长度(以千碱基为单位),获得RPKM。
FPKM(Fragments Per Kilobase Million)与RPKM非常相似:
- RPKM是针对单端测序而言,其中每个reads对应于一个已测序的片段;FPKM用于双端测序,两个reads(分为R1和R2端)对应一个测序片段(fragments)。RPKM和FPKM之间的唯一区别是FPKM考虑到成对的reads来源于一个DNA片段的测序,因此它不会来自同一fragments的reads进行两次计数。
TPM(Transcripts Per Kilobase Million)与RPKM和FPKM也比较相似,但计算顺序略有不同:
- 将每个基因的reads count值除以每个基因的长度(以千碱基为单位),获得基因的每千碱基reads覆盖数(reads per million,RPK)。
- 计算样本中所有RPK值,然后除以1000000,获得百万缩放因子。
- 将RPK值除以百万缩放因子,获得TPM值。
因此可看到,TPM与RPKM和FPKM相比,唯一的区别是先对基因长度进行归一化,然后对序列深度进行归一化。但是这种差异的影响非常明显。
使用TPM时,每个样本中所有TPM的总和是相同的,这样可以更轻松地比较每个样本中映射到基因的reads比例。使用RPKM和FPKM,每个样本中的标准化reads之和可能会有所不同,这使得直接在样本间比较更加复杂。
所以TPM方法正越来越流行。
如果样品1中基因A的TPM为3.33,而样品B中的TPM为3.33,则可以认为这两个样品中映射到基因A的总reads数的比例完全相同,因为两个样本中的TPM的总和始终为相同的数字(因此,无论要查看哪个样本,计算比例所需要的分母都是相同的。
使用RPKM或FPKM,每个样本中的标准化读数之和可能不同,此时如果样本1中基因A的RPKM为3.33,样本2中的RPKM为3.33,则难以获知两个样本中映射到基因A中reads的比例是否相同,这是因为计算比例所需的分母在两个样本之间可能是不同的。
更多内容,请添加“纪伟讲测序”官方公众号,欢迎您来咨询与交流。- 本文固定链接: https://maimengkong.com/kyjc/1241.html
- 转载请注明: : 萌小白 2022年10月5日 于 卖萌控的博客 发表
- 百度已收录
