翻译|谢旭
审校|张卫滨
本文比较了用于数据准备的几种方法,它们分别是提取-变换-加载批处理(ETL)、流式获取和数据整理。本文还讨论了数据准备如何与可视化分析相关联,以及不同用户角色(如数据科学家或业务分析人员)应如何共同构建分析模型的最佳实践。
要点
-
在常见的机器学习/深度学习项目里,数据准备占去整个分析管道的60%到80%。
-
市场上有各种用于数据清洗和特征工程的编程语言、框架和工具。它们之间的功能有重叠,也各有权衡。
-
数据整理是数据预处理的重要扩展。它最适合在可视化分析工具中使用,这能够避免分析流程被打断。
-
可视化分析工具与开源数据科学组件之间,如R、Python、KNIME、RapidMiner互为补充。
-
避免过多地使用组件能够加速数据科学项目。因此,在数据准备步骤中利用流式获取框架或流式分析产品会是一个不错的选择。
机器学习和深度学习项目在大多数企业中变得越来越重要。一个完整的项目流程包括数据准备(data preparation)、构建分析模型以及部署至生产环境。该流程是一个洞察-行动-循环(insights-action-loop),此循环能不断地改进分析模型。Forrester把这个完整的流程和其背后的平台称为洞察平台(Insights Platform)。
当你打算使用机器学习或深度学习技术来构建分析模型时,一个重要的任务是集成并通过各种数据源来准备数据集,这些数据源包括比如文件、数据库、大数据存储、传感器或社交网络等等。此步骤可占整个分析项目的80%。
本文比较了用于数据准备的几种方法,它们分别是提取-变换-加载(extract-transform-load,ETL)批处理、流式获取(streaming ingestion)和数据整理(data wrangling)。同时借助于先进的分析技术和开源框架(如R、Apache Spark、KNIME、RapidMiner),讨论了各种不同的选择及其折中。本文还讨论了数据准备如何与可视化分析相关联,以及不同用户角色(如数据科学家或业务分析人员)应如何共同构建分析模型的最佳实践。
数据准备=数据清洗(Data Cleansing)+特征工程(Feature Engineering)
数据准备是数据科学的核心。它包括数据清洗和特征工程。另外领域知识(domain knowledge)也非常重要,它有助于获得好的结果。数据准备不能完全自动化,至少在初始阶段不能。通常,数据准备占去整个分析管道(流程)的60%到80%。但是,为了使机器学习算法在数据集上获得最优的精确性,数据准备必不可少。
数据清洗可使数据获得用于分析的正确形状(shape)和质量(quality)。它包括了许多不同的功能,例如:
-
基本功能(选择、过滤、去重、...)
-
采样(平衡(balanced)、分层(stratified)、...)
-
数据分配(创建训练+验证+测试数据集、...)
-
变换(归一化、标准化、缩放、pivoting、...)
-
分箱(Binning)(基于计数、将缺失值作为其自己的组处理、...)
-
数据替换(剪切(cutting)、分割(splitting)、合并、...))
-
加权与选择(属性加权、自动优化、...)
-
属性生成(ID生成、...)
-
数据填补(imputation)(使用统计算法替换缺失的观察值)
特征工程会为分析选取正确的属性。我们需要借助数据的领域知识来选取或创建属性,这些属性能使机器学习算法正确地工作。特征工程过程包括:
-
头脑风暴或特征测试
-
特征选择
-
验证这些特征如何与模型配合使用
-
如果需要,改进特征
-
回到头脑风暴/创建更多的特征,直到工作完成
请注意,特征工程已是建模(构建分析模型)步骤里的一部分,但它也利用数据准备这一功能(例如提取字符串的某些部分)。
数据清洗和特征工程是数据准备的一部分,也是机器学习和深度学习应用的基础。这二者并不是那么容易,都需要花费功夫。
数据准备会出现在分析项目的不同阶段:
-
数据预处理:从数据源获取数据之后直接处理数据。通常由开发人员或数据科学家实现,它包括初始转换、聚合(aggregation)和数据清洗。此步骤在数据的交互式分析开始之前完成。它只执行一次。
-
数据整理:在交互式数据分析和建模期间准备数据。通常由数据科学家或业务分析师完成,以便更改数据集和特征工程的视图。此步骤会迭代更改数据集的形状,直到它能很好地查找洞察或构建良好的分析模型。
不可或缺的数据预处理和数据整理
让我们看一看典型的用于模型构建的分析流程:
-
数据访问
-
数据预处理
-
探索性数据分析(Exploratory Data Analysis)(EDA)
-
模型构建
-
模型验证
-
模型执行
-
部署
步骤2的重点是在构建分析模型之前进行的数据预处理,而数据整理则用于步骤3和步骤4(在分析数据和构建模型时,数据整理允许交互式调整数据集)。注意,这三个步骤(2、3、4)都可以包括数据清洗和特征工程。
以下截图是“数据准备”、“数据预处理”和“数据整理”这几个术语的Google搜索趋势。可以看出,数据整理受到了越来越多的关注:
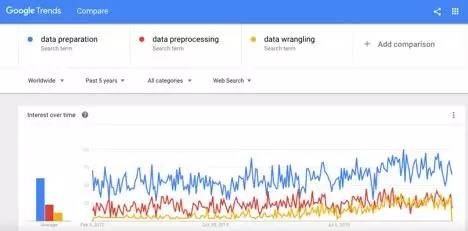
图1:“数据准备”、“数据预处理”和“数据整理”的Google搜索趋势
“inline数据整理”(inline data wrangling)是“数据整理”的一种特殊形式。在inline数据整理里,你可以利用可视化分析工具。这些工具不仅能用于可视化和模型构建,而且还能用于直接交互式整理。inline数据整理有巨大的优势,如下图所示:
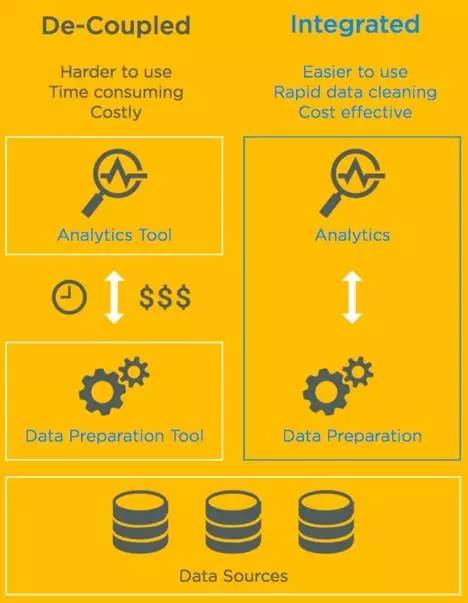
图2:解耦数据预处理(decoupled data preprocessing)与inline数据整理的比较
分析管道中的数据预处理和数据整理步骤通常由不同类型的用户完成。以下是参与分析项目的各种用户角色:
-
业务分析师:具有特定领域知识的商业/行业专家
-
数据科学家:数学、统计与编程(数据科学/脚本编写)专家;能够编写底层代码或使用更上层的工具
-
平民数据科学家(Citizen Data Scientist):类似于数据科学家,但处于更上层;需要使用更上层的工具而非编写代码;取决于工具的易用性,相关工作甚至可以由业务分析师来完成
-
开发者:软件开发专家(企业应用程序)
这些用户必须密切合作,以便在数据科学项目中取得成功(另见“如何避免分析中的反模式:机器学习的三个要点”,这篇文章能帮你更好地了解这些用户角色)。
虽然本文重点是介绍数据准备,但一图胜千言,并且人类只能解释直观可见的东西而非那些复杂的非结构化数据集,因此了解数据准备与可视化分析的关系也非常重要。有关更多细节,请参阅文章为什么应该使用可视化分析来做出更好的决策。目前主要的可视化分析工具有Qlik、Tableau和TIBCO Spotfire。
那么可视化分析是如何与数据整理相关联的呢?RITO研究公司的首席分析师说,“让分析师停下他们手里正在进行的工作,而去切换到另一个工具是令人发狂的。这破坏了他们的工作流程。 他们不得不返回重拾思路,重新开始。这严重影响了他们的生产力和创造力”。
Kaggle的Titanic数据集
以下章节给出了数据准备的几种备选方案。我们将用非常著名的Titanic数据集(来自于Kaggle)来演示一些实用的例子。Titanic数据集被分为训练集和测试集,它将用于构建分析模型,这些模型用来预测哪个乘客可能会存活或死亡:

图3:Kaggle Titanic数据集的元数据
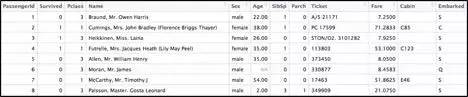
图4:Kaggle Titanic数据集的数据行示例
原始数据集不能直接用于构建分析模型。它含有重复、缺失值以及包含各种不同信息的单元格。因此,在应用机器学习算法时,需要先将原始数据集处理好,以便获得最佳结果。以下是一些数据清洗和特征工程的例子:
-
通过特征提取(feature extraction)创建新列:获取每位乘客的姓名前缀,从而推断出其性别,例如,先生、夫人、小姐、大师
-
通过聚合创建新列,以查看每位乘客的旅行团中有多少人:“家庭大小= 1 + SibSp + Parch”
-
通过提取第一个字符来创建新列,以便排序和分析舱室:提取“舱室”列的第一个字符
-
删除数据集中的重复项,例如,乘客既在训练集中又在测试集中
-
通过填补将数据添加到空单元格,以便能够处理数据缺失的行,例如,年龄:将“不可用”替换为所有乘客的平均年龄或将其离散到对应的箱(bin)中;舱室:用“U”(未知)替换空值;或应用高级填补方法,例如,通过链式方程的多重填补(multiple imputation by chained equations)(MICE)
-
利用数据科学功能,例如,缩放、归一化、主成分分析(PCA)或Box-Cox,使所有数据处于“相似形状”,以便能够进行合理的分析
以下章节阐述了各种编程语言、框架和数据准备工具。请注意,没有哪种方案适用于所有问题。此外,这些方案之间也有很多重叠(overlapping)。因此,根据用户角色和用例,许多问题可以使用不同的方案来解决。
数据科学的数据预处理
一些编程语言是专为数据科学项目而设计,或者是对它有非常好的支持,特别是R和Python。它们包含了机器学习算法的各种实现,诸如过滤或提取的预处理功能,以及诸如缩放、归一化或混洗(shuffle)的数据科学功能。数据科学家需要编写相对底层的代码来进行探索性数据分析与准备。与使用Java或C#的传统编程相反,使用R或Python进行数据预处理时,你不需要编写太多的代码;它更多地是让你了解统计概念以及算法的数据和经验,这些数据和经验可用于数据预处理和模型构建。
这些编程语言是为数据科学家准备数据和构建分析模型而建立,它们并不适用于企业部署(将分析模型部署到具有高规模和高可靠性的新数据中)。因此,市场上提供了商业的enterprise runtime帮助你实现企业部署。通常,它们支持相同的源代码,因此你不需要为企业部署重写任何东西。对于R,你可以使用开源的Microsoft R Open(之前的Revolution R),或TIBCO Enterprise Runtime for R。后者具有不受GPL开源许可证限制的优势,因此你可以使用在任何嵌入式或外部环境里。
下面的代码摘录于一个不错的R教程,它演示了如何使用基本的R语言来预处理和分析Titanic数据集:
### 使用基本的R语言进行数据预处理:# 存活是“是/否”# =>类型转换:没有numeric值和对应的数据处理/分析data.combined$Survived <- as.factor(data.combined$Survived)# 从全称里解析出姓和头衔data.combined[1:25, "Name"]name.splits <- str_split(data.combined$Name, ",")name.splits[1]last.names <- sapply(name.splits, "[", 1)last.names[1:10]# 特征工程:创建家庭大小特征#(兄弟姐妹/配偶+父母/孩子+1)temp.SibSp <- c(train$SibSp, test$SibSp)temp.Parch <- c(train$Parch, test$Parch)data.combined$FamilySize <- as.factor(temp.SibSp + temp.Parch + 1)
除了对预处理的基本支持外,这些编程语言还提供了许多额外的数据科学软件包。例如,许多数据科学家利用R中非常强大的caret包来简化数据准备和减少代码量。该软件包简化了复杂回归和分类问题的模型准备与训练过程。它为数百个现有的R模型实现(在底层使用了各种各样的API)提供了一个通用接口。以下代码段使用了caret的通用API对Titanic数据集进行预处理:
### 使用R caret包进行数据预处理:# 利用caret的preProcess函数对数据做归一化preproc.data.combined <- data.combined[, c("ticket.party.size", "avg.fare")]preProc <- preProcess(preproc.data.combined, method = c("center", "scale"))# ->你看到的是相对值而非绝对值(即彼此之间的关系):postproc.data.combined <- predict(preProc, preproc.data.combined)
另一个用于数据预处理的R包是dplyr包。它不像caret包那样强大,并且只专注于操作、清洗和汇总(summarize)非结构化数据。 Dplyr旨在为数据操作的每个基本动作都提供一个函数:
filter()(和slice())arrange()select()(和rename())distinct()mutate()(和transmute())summarise()sample_n (和sample_frac())
因此,学习和理解许多数据操作任务变得容易。对于data.table包也是这样。正如你所见的,在R语言里你有许多方法来预处理数据集。
数据科学家或开发者的大数据集预处理
诸如R或Python这样的编程语言可用于处理小数据集。但是,它们并不是为处理真正的大数据集而创建;与此同时,我们经常需要分析几个GB、TB甚至PB级别的数据。类似于Apache Hadoop或Apache Spark的大数据框架则是为处于边缘的(即数据所在位置)弹性扩展(elastic scalability)和数据预处理而创建。
这些大数据框架侧重于“底层”编码,并且配置起来比R或Python环境要复杂得多。商业软件,如Hortonworks、Cloudera、MapR或Databricks可以帮助解决此问题。通常,数据科学家与开发人员相互合作来完成大数据项目。后者负责集群配置、部署和监控,而数据科学家则利用R或Python API编写用于数据预处理和构建分析模型的代码。
源代码通常看起来与仅使用R或Python的代码非常相似,但数据预处理是在整个集群上并行完成的。下面的示例演示了如何使用Spark的Scala API对Titanic数据集进行预处理和特征工程:
### 使用Scala和Apache Spark API进行数据预处理:# 特征工程:创建家庭大小特征# (兄弟姐妹/配偶+父母/孩子+1)val familySize: ((Int, Int) => Int) = (sibSp: Int, parCh: Int) => sibSp + parCh + 1val familySizeUDF = udf(familySize)val dfWithFamilySize = df.withColumn("FamilySize", familySizeUDF(col("SibSp"), col("Parch")))// 为年龄列填充空值val avgAge = trainDF.select("Age").union(testDF.select("Age")) .agg(avg("Age")) .collect() match { case Array(Row(avg: Double)) => avg case _ => 0}
当然,你可以使用Spark的Java或Python API做同样的事情。
平民数据科学家的数据预处理
通常,你想要敏捷并且快速得到结果。这常常需要在准备和分析数据集时大量地试错。你可以利用现存的各种快捷易用的数据科学工具。这些工具提供了:
-
开发环境和运行/执行服务器
-
使用拖放与代码生成的可视化“编码”
-
集成各种数据科学框架,如R、Python或更强大的(诸如Apache Hadoop、Apache Spark或底层的H2O.ai)大数据框架
数据科学家可以使用这些工具来加速数据预处理和模型建立。此外,该类工具还帮助解决了数据预处理和机器学习算法的实现,因此没有太多项目经验的平民数据科学家也可以使用它们。一些工具甚至能够提出建议,这些建议有助于用户预处理、显示和分析数据集。这些工具在底层人工智能的驱动下变得越来越智能。
下面的例子展示了如何使用两个开源数据科学工具KNIME和RapidMiner来预处理Titanic数据集:
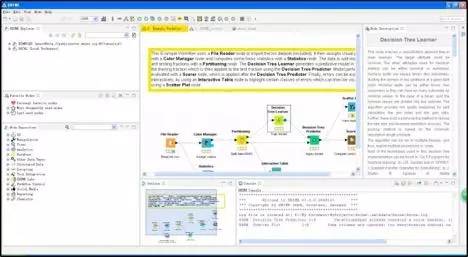
使用KNIME来预处理Titanic数据集
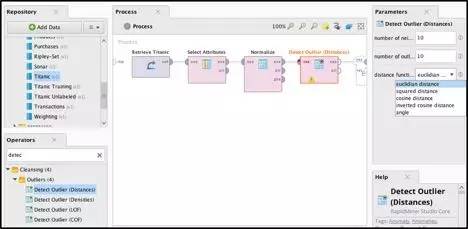
使用RapidMiner来预处理Titanic数据集
你可以使用可视化IDE来配置预处理,而非如前所述的用R或Scala编写源代码。对大多数用户来说,这使得数据准备和分析变得更容易,并且数据的维护和移交也变得更容易。
业务分析师或平民数据科学家的数据整理
数据整理(有时也称为data munging)是一种使用图形工具的数据准备方法,该方法简单直观。这些工具侧重于易用性和敏捷的数据准备。因此,它不一定由开发人员或数据科学家完成,而是所有的用户都可以(包括业务分析师或平民数据科学家)。DataWrangler和Trifacta Wrangler是数据整理的两个示例。
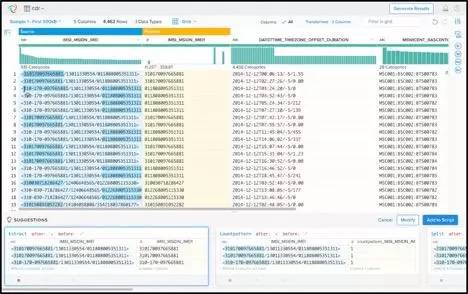
用于数据整理的Trifacta
请注意,这些工具没有数据预处理框架那么强大,因此它们经常用于数据准备的最后一公里。它们不会替换其它的集成选项,如ETL(提取-变换-加载)工具,或使用R、Python、KNIME、RapidMiner等进行的数据预处理。
如引言中所讨论,因为数据整理与实际数据分析相互解耦,所以数据整理自身的工具可能会存在一些不足之处。可视化分析工具中的数据整理允许在数据的探索性分析期间进行inline数据整理。单个的用户使用单一的工具就能够完成它。例如,请参阅TIBCO Spotfire示例,它结合了可视化分析与inline数据整理(以及其它的数据科学功能来构建分析模型):
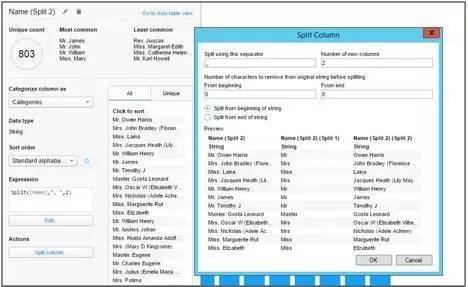
可视化分析工具TIBCO Spotfire中的inline数据整理
数据整理工具和带有inline数据整理的可视化分析工具可以被每种用户角色使用:业务分析师、(平民)数据科学家或开发人员,这些工具能够加速数据准备和数据分析。
本文重点介绍了用于建立机器学习模型的数据准备。你可以使用编程语言(如R或Python)、数据科学工具(如KNIME或RapidMiner)、数据整理(使用DataWrangler或Trificata)或inline数据整理(通过TIBCO Spotfire)。通常,在开始这一切之前,你需要能够访问你拥有的所有数据,这些数据存储于各种或多或少整理过的数据源中(如关系数据库、数据仓库、大数据集群)。因此,在以下两部分,我们将简要介绍用于数据获取(data ingestion)的ETL和流式分析工具,通常数据获取还包括数据准备的某些部分,特别是数据聚合和数据清洗。
开发者的ETL(提取-变换-加载)和DQ(数据质量,Data Quality)
ETL工具是为开发者集成各种数据源而设计的,它包括了许多遗留和专有(proprietary)接口(如Mainframe或EDIFACT接口),这些接口具有十分复杂的数据结构。它还包括了数据清洗(在上下文中通常被称为“数据质量”工具),并将重点放在易用性和使用可视化编码的企业部署上(类似于如KNIME或RapidMiner的数据科学工具,但是专注于ETL和数据质量)。它们还支持大数据框架,如Apache Hadoop和Apache Spark。此外,它们还为质量改进提供了开箱即用(out-of-the-box )的支持,例如,地址验证。ETL和DQ通常在长时间运行的批处理进程中实现,因此如果你需要使用实时数据构建模型,那么这有时可能会产生负面影响。
ETL和DQ工具的例子是一些开源工具,如Pentaho或Talend,或专有供应商Informatica。市场正在向更简单易用的Web用户界面转移,这些简单易用的界面能够让其他用户角色也执行一些基本的任务。
开发者的数据获取与流式分析
数据获取与流式分析工具可用于在流(stream)中添加和预处理数据。这些框架允许批量地或实时地预处理数据。下图展示了一个典型的流式分析流程,它包括数据获取、预处理、分析、处理和输出:
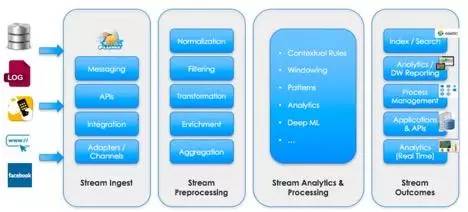
流式分析流程的步骤
目前市场上有各种各样的框架和工具。它们都以这种或那种方式支持类似Hadoop或Spark的大数据框架。举几个例子:
-
数据获取开源框架(仅关注数据获取和预处理步骤):Apache NiFi、StreamSets、Cask Hydrator
-
流式处理开源框架(完整的流式分析流程):Apache Storm、Apache Flink、Apache Apex
-
流式处理商业软件(完整的流式分析流程):Software AG Apama、IBM Streams、TIBCO StreamBase
使用这些工具(包括ETL)的巨大优势是,你可以使用同一套工具或框架(对历史数据)进行数据预处理,以及(对新数据)进行实时处理(以便在变化的数据里使用分析模型)。这将会是一个不错的选择,用户不仅可以保持小而精的工具集,而且还能通过一套工具同时获得ETL/获取和实时处理。下图是一个使用TIBCO StreamBase对Titanic数据集进行预处理的例子:
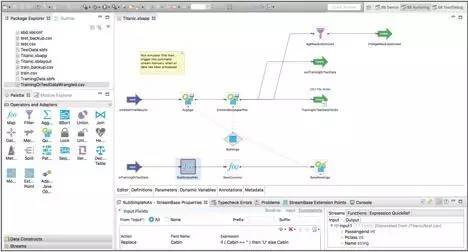
Titanic数据集的流式预处理
对于数据获取和ETL工具,流式分析的市场正在转向更简单的Web用户界面,这些简单的用户界面让其他用户角色也能执行一些基本的任务。但这不会取代现有的工具在更高级别用例里的使用,而是为分析师或数据科学家提供了新的选择。在没有开发人员的帮助下,他们能够更容易和更直接地部署一些规则、关联或分析模型。
数据准备是机器学习项目成功的关键
使用机器学习或深度学习技术构建分析模型并不容易。数据准备占去整个分析管道的60%到80%。市场上有各种用于数据清洗和特征工程的编程语言、框架和工具。它们之间的功能有重叠,也各有权衡。
数据整理是数据预处理的重要扩展(add-on)。它最适合在可视化分析工具中使用,这能够避免分析流程被打断。可视化分析工具与开源数据科学组件(component)之间,如R、Python、KNIME、RapidMiner互为补充。
避免过多地使用组件能够加速数据科学项目。因此,在数据准备步骤中利用流式获取框架或流式分析产品会是一个不错的选择。我们只需要编写一次预处理的步骤,然后将其用于历史数据的批处理中,从而进行分析模型的构建,同时,还可以将其用于实时处理,这样就能将我们构建的分析模型用到新的事件中。
- 本文固定链接: https://maimengkong.com/zu/1096.html
- 转载请注明: : 萌小白 2022年7月6日 于 卖萌控的博客 发表
- 百度已收录
