本文来了解下R语言关键的组成部分:R程序和R数据
一、R语言程序
R语言程序主要由R程序及其分析结果组成
1. R程序
R程序由多行代码组成(基于S语言),是由命令和结果名组成。
例如:
Lg<-log(10) #计算10的自然对数值
其中,
- log(10)为命令,Lg为命令产生的结果名
- R程序代码大小写必须区分,Lg和lg是不同的
- R语言中,命令主要为函数形式
- 结果名主要是数据或者统计分析结果集合的一个标签。
- 命令产生的结果复制给结果名的符号为“<-”,就是告诉我们,我这条命令,产生的结果都打包给你了,这个包的名字叫做Lg。
- #+文字 为对程序的注释或解释,程序运行时会自动忽略。解释很重要,规范的R程序每天都需要解释,以免下一次看不懂上次R代码的意思。
2.R语言的分析结果
上述已经提过,R语言分析在一个名字为结果名的包中,想要知道结果,只要如果你想知道Lg的内容。直接再输入以下命令,就出来结果了。
Lg
上述程序合并在一起就是
Lg<-log(10)
Lg
有些时候命令不打包,也就是不赋值,则直接log(10)就可以出来结果了。
log(10)
3. R程序的具体运行过程
R程序运行过程,全部可以在Rstudio文本编辑器操作。如果要将两行全部运行,选中全部,点击右上角run按钮。如果只想跑一行,讲鼠标放置在改行,点击右上角run按钮即可
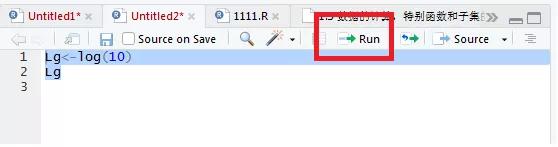
> Lg<-log(10)
> Lg
[1] 2.302585
> log(10)
[1] 2.302585
具体GIF动画
4. R命令的主要形式:函数
大多数R语言的命令为函数。中学学过数学我们就知道f(x),为函数的基本表现方法。在R语言也是如此。
log(10)中,log为函数名,往往形式为log(),即为y=ln(x)。10为一个函数的参数,也就是其中的x。
R语言包的方便就在于,对于复杂的函数,我们无序自己手动去计算函数的值,R语言作者通过编写程序,已经写了一系列的函数,帮助我们去直接计算。比如计算标准差sd,无需将标准差的公式写出来计算,只需sd()即可
函数中,要纳入的参数往往不是一个,很多时候函数()中的参数很多。比如,我需要产生一连续的的数据,采用seq的方法。比如我想产生1-5直接连续的一串数据,那么就可以
> seq(1,5)
[1] 1 2 3 4 5
这里面的参数看起来有2个,也就是一头一尾的界值。但实际上seq()的参数总共是五个,包括from,to,by,length.out,along.with 另外三个一般都缺省了。
seq(from = 1, to = 1, by = ((to - from)/(length.out - 1)), length.out = NULL, along.with = NULL, ...)
如果我们加一个by参数(间隔2个单位产生一串数据):
> seq(1,5,2)
[1] 1 3 5
因此,R语言函数其实设定的参数个数往往都不少,一般情况下,我们以缺省的方法可以忽略它,但是特殊情况必须要进行设置。各种函数的参数解释可以输入help()语句进行学习:
> help("seq")

5. R语言简单计算
以下是R语言最基本的数学计算公式,请大家进行根据R函数进行简单的运算
加减乘除:+ - * / ;
> 1+1 #程序
[1] 2 #运算结果
平方根:sqrt()
> sqrt(25) #程序
[1] 5 #运算结果
对数:log2()、log10()、log(a,base=exp(1))
> log(10) #程序
[1] 2.302585 #运算结果
其他还包括:余数、整除:%% %/%;幂、指数:^;判断符号 == > < != <= >= 等
二、R语言程序对象:R数据
1. R 数据产生的方式
R数据产生往往有两种:第一种是利用R函数直接产生相应的数据集,一般用来举例、方便学员理解;另外一种是从外界的数据库比如EXCEL,导入数据,形成数据集,这种是大多数R数据分析的的方式。
今天文章先来先来介绍第一种方法。利用R函数直接产生数据库的方法,最常用的是利用最基本的函数c( )。
举例:c()产生一串数据,并赋值结果名(数据名)x1、x2
> x1<-c(2,4, 6, 10) #产生数据,数据名为x1
> x1
[1] 2 4 6 10
或者
> x2<-c("A","B", "C","D") #产生数据,数据名为x2
> x2
[1] "A" "B" "C" "D"
R语言也可以不用 c( ),直接产生连续等距数据:
> x3<-1:5 #产生1-5直接连续整数数据,数据名为x2
> x3
[1] 1 2 3 4 5
我们也可以利用seq(1,5)产生等距的数据串,本文先前已经介绍过了。也可以利用
2. R数据的类型
R数据类型可以从两个角度进行分类,一种是根据数据值本身,或者统计学上所说的变量值来进行判断;第二种角度,根据变量特性进行判断。
第一种角度,变量观察值的类型
根据数据值,我们可以有以下多种形式
- 数字(double/numeric, 缩写num)
- 整数(integer, 缩写int) : 1L, 2L
- 虚数(complex, 缩写cplx) :1+2i, 3-5i
- 逻辑(logic, 缩写logi) : True, False
- 文字(character, 缩写chr)
x1<-c(2, ,4, 6, 10),x1数据集全部为数字型
x2<-c(“A”, “B”, “C”, “D”),x2 数据集全部为文字型
特别注意的是,R语言逻辑型数据为True, False,或者T,F,他们不是字符串,而是对客观现象的一种判断,在R语言有特殊的地位,今后会经常碰到,敬请注意。
函数class( ) 可以鉴定一串数据的类型
> class(x1)
[1] "numeric"
> class(x2)
[1] "character"
第二种角度,变量的类型
在医学研究中,数据由变量组成,变量可以分为数值变量和分类变量。
数值变量数据,一般来说变量值都以数值为主。包括整数型和数值型向量
> x4<-c(170,171,161,164) # 产生身高的变量
> x4
[1] 170 171 161 164
分类变量数据,包括无序和有序。变量值的属性结果,比如女性或者男性,在R语言中分类变量我们称之为因子(factor)。
主要包括:字符型变量;整数型变量: 1、2;逻辑性变量;医学数据库最常见的类型是整数型变量,即便是字符型变量(性别,男性和女性),也通常会以整数型变量体现,比如1,2来表示,用1代表男,用2代表女。这样做好处非常明显:数据库主要开展数学运算,数学运算对象,最好是数字。
对于字符串型的分类数据,R语言直接认定为因子
对于数值型分类数据,R语言很多时候认定为数值变量数据,需要用factor( )或者as.factor( )函数进行转换
factor( )可将整数型向量转为分类变量数据,变成因子
> f1<-factor(c(1,2,1,3,2,4,2,4,2,1))
> f1
[1] 1 2 1 3 2 4 2 4 2 1
Levels: 1 2 3 4
factor( )可以加levels参数设定,对因子顺序进行重新排列
> f2<-factor(c(1,2,1,3,2,4,2,4,2,1),levels=c(2,1,4,3))
> f2
[1] 1 2 1 3 2 4 2 4 2 1
Levels: 2 1 4 3
在f2数据集产生过程中,函数加了条件levels。加levels的意思是,对里面因子1,2,3,4的排列顺序重新调整,在这个例子中,2这个一类别是放在最前面的,在以后统计分析中,作为对照组。这一操作是否有价值,我们可以在统计分析中,任意设定对照组,而不是只以第一组或者第四组为对照
我们还可以设定值的标签:
f3<-factor(c(1,2,1,3,2,4,2,4,2,1), levels=c(2,1,4,3),
labels = c("A","B","AB","O"))
对于因子,我们还有更多的操作,诸位可以试试
- table(f1) #因子列表展示
- class(f1) #查看f1的类型
- levels(f1) #查看f1 因子的分组水平
- summary(f1) #f1因子的汇总
- as.factor( ) #把数值型的资料变成因子
DAY2的内容就介绍到这里!
转自:医学论文与统计分析
- 本文固定链接: https://maimengkong.com/moreshare/975.html
- 转载请注明: : 萌小白 2022年6月4日 于 卖萌控的博客 发表
- 百度已收录
