《R包学习》专栏·第2篇
文| R学习者
3412字 | 9分钟阅读
这是dplyr包系列第二篇文章。第一篇文章《dplyr包-列选择的方法 》总结了如何使用dplyr包有效地选择感兴趣的列。本文会总结列变换的方法,以实现按着需求对列做合理处理,例如:衍生新的列,列的离散化,列的拆分与合并等。

列的变换操作,会介绍如下内容:
- 增加一列
- 增加多列
- 列的离散化操作
- 列的拆分
- 列的合并
- 列的集成
- 数据重塑
我们以R自带数据,采用管道的操作,演示列变换的具体操作和实现。
第一步:加载R包和数据集
1library(pacman)
2p_load(tidyverse)
3# 使用msleep数据集做示例
4msleep %>% glimpse
第二步:列变换操作实例
1 增加一列,使用mutate函数
1# 1 增加一列
2msleep%>%
3select(name, sleep_total) %>%
4mutate(sleep_total_min = sleep_total * 60) %>%
5head

增加的新列,也可使用聚合函数,计算平均值、中位数、最大值、最小值、标准差等。
1msleep%>%
2select(name, sleep_total) %>%
3mutate(sleep_total_vs_AVG = sleep_total - round(mean(sleep_total), 1)) %>%
4head

若要基于两列或者多列的值按着行来做聚合以生成新的列,可以参照如下方法实现。
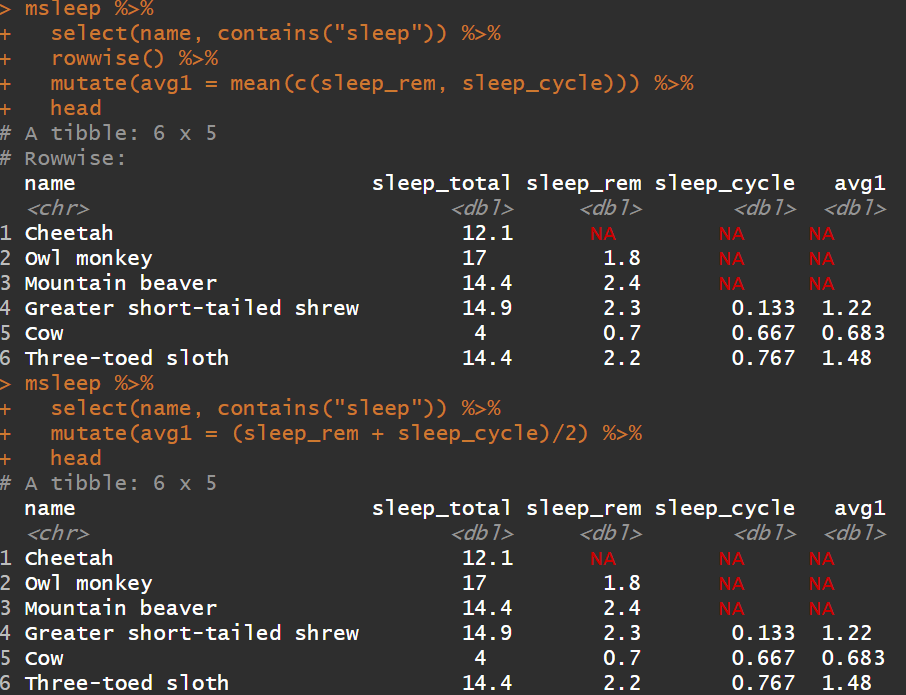
1# 方法1 使用rowwise 指定按着每行做聚合计算
2msleep%>%
3select(name, contains( "sleep")) %>%
4rowwise %>%
5mutate(avg1 = mean(c(sleep_rem, sleep_cycle))) %>%
6head
7# 方法2
8msleep %>%
9select(name, contains( "sleep")) %>%
10mutate(avg1 = (sleep_rem + sleep_cycle)/ 2) %>%
11head
思考题:
1)若要增加一列,记录brainw大于4,就为NA,否则为原值,请问如何实现?
2)请问下面这个代码片段实现了什么功能?
1# ?这个代码片段的作用是什么
2msleep%>%
3select(name) %>%
4mutate(name_last_word = tolower(str_extract(name, pattern = "w+$"))) %>%
5head
2 增加多列,使用mutate_all,mutate_if和mutate_at函数
2.1 mutate_all,对所有列操作
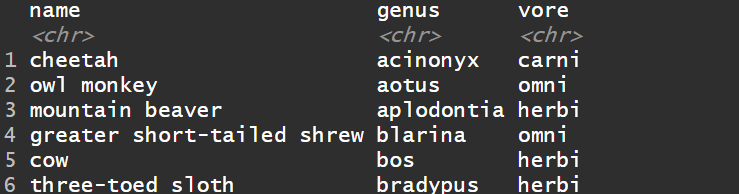
1)把所有列小写化
1msleep%>%
2select(name, genus, vore) %>%
3mutate_all(tolower) %>%
4head
2)对所有列做数据清洗工作
1msleep_ohno<- msleep %>%
2select(name, genus, vore) %>%
3mutate_all(~paste(., " /n "))
4msleep_ohno %>% head
5msleep_corr <- msleep_ohno %>%
6mutate_all(~str_replace_all(., "/n", "")) %>%
7mutate_all(str_trim)
8msleep_corr %>% head
2.2 mutate_if,对布尔值为真的列进行操作
常用的布尔值判断函数
is.numeric,is.integer,is.double,is.logical,is.factor,lubridate::POSIXt或者lubridate::is.Date
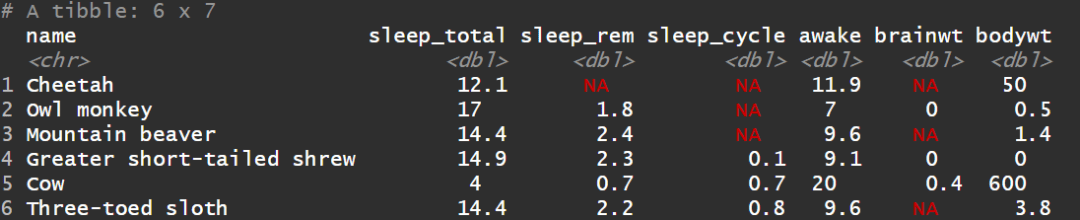
例如,对所有数值型变量取一位小数
1# 自定义函数
2my_func <- function(x){
3return(round(x,1))
4}
5msleep%>%
6select( name, sleep_total:bodywt) %>%
7mutate_if( is.numeric, my_func) %>%
8head
9
2.3 mutate_at, 在vars参数中指定要操作的列
具体使用方法,第一步,在vars指定需要操作的列,第二步,使用波浪线引入所需操作的函数。
1msleep%>%
2select(name, sleep_total:awake) %>%
3mutate_at(vars(contains( "sleep")), ~(.* 60)) %>%
4rename_at(vars(contains( "sleep")), ~paste0(., "_min")) %>%
5head

3 列的离散化操作
1) 重编码操作,使用recode函数或者recode_factor函数
1msleep %>%
2mutate(conservation2 = recode(conservation,
3"en"= "Endangered",
4"lc"= "Least_Concern",
5"domesticated"= "Least_Concern",
6. default= "other")) %>%
7count(conservation2)
8msleep %>%
9mutate(conservation2 = recode_factor(conservation,
10"en"= "Endangered",
11"lc"= "Least_Concern",
12"domesticated"= "Least_Concern",
13. default= "other",
14.missing = "no data",
15.ordered = TRUE)) %>%
16count(conservation2)
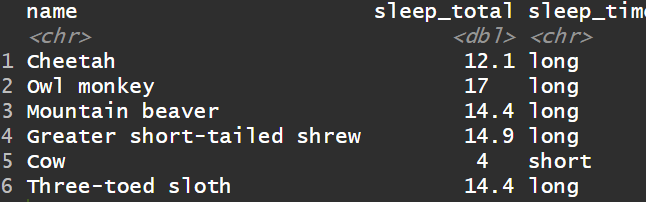
2) 创建新的离散列(二元情形),使用ifelse函数
1msleep%>%
2select(name, sleep_total) %>%
3mutate(sleep_time = ifelse(sleep_total > 10, "long", "short")) %>%
4head
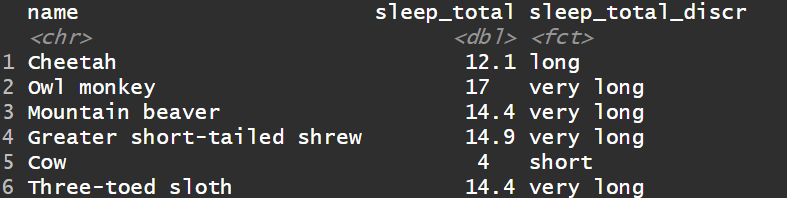
3) 创建新的离散列(多元情形),使用case_when函数
1msleep%>%
2select(name, sleep_total) %>%
3mutate(sleep_total_discr = case_when(
4sleep_total > 13~ "verylong ",
5sleep_total > 10 ~ " long ",
6sleep_total > 7 ~ " limited ",
7TRUE ~ " short ")) %>%
8mutate(sleep_total_discr = factor(sleep_total_discr,
9levels = c(" short ", "limited ",
10" long ", "very long "))) %>%
11head
12
4 列的拆分
使用separate函数
1(conservation_expl <- read_csv( "./datasets/conservation_explanation.csv"))
2(conservation_table <- conservation_expl %>%
3separate(`conservation abbreviation`,
4into= c( "abbreviation", "deion"), sep = " = "))
5 列的合并
使用unite函数
1conservation_table%>%
2unite(united_col, abbreviation, deion, sep= ": ")
6 列的集成
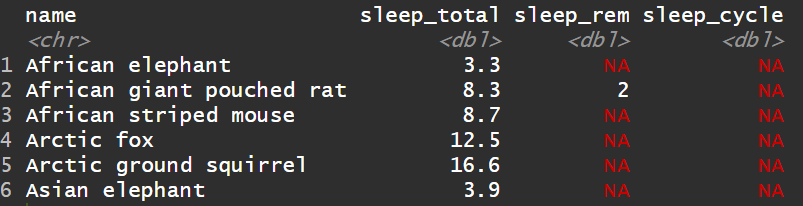
使用关联函数,左连接left_join,内连接inner_join等。
1msleep %>%
2select(name, conservation) %>%
3mutate(conservation = toupper(conservation)) %>%
4left_join(conservation_table, by= c( "conservation"= "abbreviation")) %>%
5mutate(deion = ifelse( is.na(deion), conservation, deion)) %>%
6head
7 数据重塑
使用gather函数把宽表转换成长表,使用spread函数把长表转换成宽表。
1)gather示例
1# 1)宽表变为长表
2msleep %>%
3select(name, contains( "sleep")) %>%
4gather(key = "sleep_measure", value= "time", -name) %>%
5head
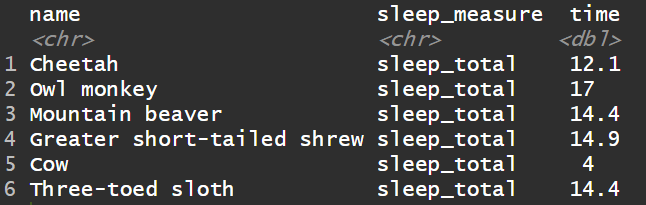
思考题:下面这个代码片段,有什么作用?
1(msleep_g <- msleep %>%
2select(name, contains( "sleep")) %>%
3gather( key= "sleep_measure", value = "time", -name, factor_key = TRUE))
2)spread示例
1# 2) 长表变为宽表
2msleep_g%>%
3spread(sleep_measure, time) %>%
4head
完整代码:
1# dplyr包列变换的方法
2
3# 第一步:加载R包和数据集
4library(pacman)
5p_load(tidyverse)
6# 使用msleep数据集做示例
7msleep %>% glimpse
8
9# 第二步:列变换操作实例
10# 1 增加新的一列
11msleep %>%
12select(name, sleep_total) %>%
13mutate(sleep_total_min = sleep_total * 60) %>%
14head
15
16msleep %>%
17select(name, sleep_total) %>%
18mutate(sleep_total_vs_AVG = sleep_total - round(mean(sleep_total), 1)) %>%
19head
20
21# 方法1 使用rowwise 指定按着每行做聚合计算
22msleep %>%
23select(name, contains( "sleep")) %>%
24rowwise %>%
25mutate(avg1 = mean(c(sleep_rem, sleep_cycle))) %>%
26head
27# 方法2
28msleep %>%
29select(name, contains( "sleep")) %>%
30mutate(avg1 = (sleep_rem + sleep_cycle)/ 2) %>%
31head
32
33msleep %>%
34select(name, brainwt) %>%
35mutate(brainwt2 = ifelse(brainwt > 4, NA, brainwt)) %>%
36head
37
38
39msleep %>%
40select(name) %>%
41mutate(name_last_word = tolower(str_extract(name, pattern = "w+$"))) %>%
42head
43
44# 2 增加多列
45# mutate_all函数
46msleep %>%
47select(name, genus, vore) %>%
48mutate_all(tolower) %>%
49head
50
51msleep_ohno <- msleep %>%
52select(name, genus, vore) %>%
53mutate_all(~paste(., " /n "))
54msleep_ohno %>% head
55msleep_corr <- msleep_ohno %>%
56mutate_all(~str_replace_all(., "/n", "")) %>%
57mutate_all(str_trim)
58msleep_corr %>% head
59
60# mutate_if函数
61my_func <- function(x){
62return(round(x, 1))
63}
64msleep %>%
65select(name, sleep_total:bodywt) %>%
66mutate_if( is.numeric, my_func) %>%
67head
68
69# mutate_at函数
70msleep %>%
71select(name, sleep_total:awake) %>%
72mutate_at(vars(contains( "sleep")), ~(.* 60)) %>%
73head
74
75msleep %>%
76select(name, sleep_total:awake) %>%
77mutate_at(vars(contains( "sleep")), ~(.* 60)) %>%
78rename_at(vars(contains( "sleep")), ~paste0(., "_min")) %>%
79head
80
81# 3 列的离散化操作
82msleep %>%
83mutate(conservation2 = recode(conservation,
84"en"= "Endangered",
85"lc"= "Least_Concern",
86"domesticated"= "Least_Concern",
87. default= "other")) %>%
88count(conservation2)
89
90msleep %>%
91mutate(conservation2 = recode_factor(conservation,
92"en"= "Endangered",
93"lc"= "Least_Concern",
94"domesticated"= "Least_Concern",
95. default= "other",
96.missing = "no data",
97.ordered = TRUE)) %>%
98count(conservation2)
99
100msleep %>%
101select(name, sleep_total) %>%
102mutate(sleep_time = ifelse(sleep_total > 10, "long", "short")) %>%
103head
104
105msleep %>%
106select(name, sleep_total) %>%
107mutate(sleep_total_discr = case_when(
108sleep_total > 13~ "very long",
109sleep_total > 10~ "long",
110sleep_total > 7~ "limited",
111TRUE ~ "short")) %>%
112mutate(sleep_total_discr = factor(sleep_total_discr,
113levels = c( "short", "limited",
114"long", "very long"))) %>%
115head
116
117msleep %>%
118mutate(silly_groups = case_when(
119brainwt < 0.001~ "light_headed",
120sleep_total > 10~ "lazy_sleeper",
121is.na(sleep_rem) ~ "absent_rem",
122TRUE ~ "other")) %>%
123count(silly_groups)
124
125# 4 列的拆分
126(conservation_expl <- read_csv( "./datasets/conservation_explanation.csv"))
127(conservation_table <- conservation_expl %>%
128separate(`conservation abbreviation`,
129into= c( "abbreviation", "deion"), sep = " = "))
130
131# 5 列的合并
132conservation_table %>%
133unite(united_col, abbreviation, deion, sep= ": ")
134
135# 6 列的集成
136# 使用连接函数
137msleep %>%
138select(name, conservation) %>%
139mutate(conservation = toupper(conservation)) %>%
140left_join(conservation_table, by= c( "conservation"= "abbreviation")) %>%
141mutate(deion = ifelse( is.na(deion), conservation, deion)) %>%
142head
143
144# 7 列重塑
145# 1)宽表变为长表
146msleep %>%
147select(name, contains( "sleep")) %>%
148gather(key = "sleep_measure", value= "time", -name) %>%
149
150
151(msleep_g <- msleep %>%
152select(name, contains( "sleep")) %>%
153gather(key = "sleep_measure", value= "time", -name, factor_key = TRUE))
154
155# 2) 长表变为宽表
156msleep_g %>%
157spread(sleep_measure, time) %>%
158head
参考资料:
1https://suzan.rbind.io/2018/02/dplyr-tutorial-2/
- 本文固定链接: https://maimengkong.com/moreshare/1276.html
- 转载请注明: : 萌小白 2022年11月18日 于 卖萌控的博客 发表
- 百度已收录
