俱往矣,数风流人物,还看今朝!从今天开始,R语言数据清洗或者叫做数据预处理的大幕正式拉开!众所周知,在现实工作中,我们面临的几乎所有数据都是脏数据,即乱七八糟的数据,要让这些数据发挥价值,就必须要对其进行整理、修饰,让其变成一个软件可接受,可识别的整洁数据。
当然了,100个数据科学家就会有98个说,数据清洗最费时间费脑子。

这是可想而知的,因为数据的读取与分析这都是固定的套路,唯有数据的清洗不固定,因为我们会遇到各种各样的奇葩数据。

好了,闲话少叙,直接进入今天的主题——数据排排坐。

数据排排坐,只是一句为了吸引大家眼球的俏皮话,其真正的意思是变量的排序。变量,或者说数据的排序,我们并不陌生,在Excel中就经常干这种事情。Excel中的排序用法相对初级,要么由高到低,要么由低到高。而在R语言中,变量的排序则更加灵活,功能更加强大。
R语言中与变量排序的函数有几个,比如sort(), order(), rank()以及dplyr包中的arrange()函数。今天主要介绍前三个函数,关于arrange(),我们会在介绍dplyr包的时候一起介绍。

dvdf
如你所见,nums是一个随机生成的1-100之内的整数,默认情况下是没有顺序的,经过sort()函数排序后,则生成了顺序,此处我们将decreasing参数设置为TRUE,表示从大到小排序,该参数默认为FALSE,即从小到大排序。

wode
在nums2中,我加入了一个NA,即缺失值,同时引入了一个新参数na.last,默认情况下,NA是会被删除的,即不参与排序。当na.last参数设置为TRUE时,NA则会被置于向量的最后,若为FALSE,则会被置于向量的第一位。

如你所见,sort()函数不仅可以对数值型向量进行排序,同样可以对字符串排序,这个顺序就是按照字母表的先后顺序。

好,关于sort()点到即止。下面我们介绍一下rank()函数。
rank()函数其实不是用来排序的,而是用来产生秩的。何为秩?即秩次。小时候我们最怕的就是期末排名了(当然了,Leopard作为常年优等生,一直稳居班级前二,嘿嘿),排名就是一种秩次,比如第一名,第二名,有时候还有遇到并列名次。这都是秩次。

学过卫生统计学的童鞋自动忽视上述解释,秩次你们都懂的。看例子:

我们生成了一个数值向量x2,并给x2中的所有元素命了名,对x2进行排序之后,如你所见,1,1,2,3,3,4,5,5,5,6,9。第一位和第二位都是1,所以他俩的秩都是1.5((1+2)/2),对应起来,就是b和d的秩次为1.5,以此类推。
﹏
﹏
﹏
﹏
以上我们生成的都是平均秩次,有些时候,我们不需要平均秩次,这时就可以调用ties.method参数。

当该参数设置为“first”后,即表示只返回第一个秩次,比如1,在x2中出现两次,但是只返回第一次出现时的秩次1。同理,将ties.method参数设置为‘last’时,则表示只返回最后一次出现时的秩次。

order()函数与sort()函数截然不同,它返回的是元素的下标,即元素在向量中的位置。见下面的例子:

ok,我们产生了一个随机数变量x,并将x进行了升序排序。

如你所见,order()函数返回的并不是元素本身,而是元素在原始向量x中的位置,比如第一个数字7,它表示排在第一位的元素在x向量中是排在第七位的!我们去找一下,发现第七位的元素是4。x中4是最小的,理所当然排在第一位!
由于order()函数更多的是在数据框变量中使用,所以下面我们结合数据框来进行演示。
这里我们使用reshape2包中的tips数据(小费数据集)。
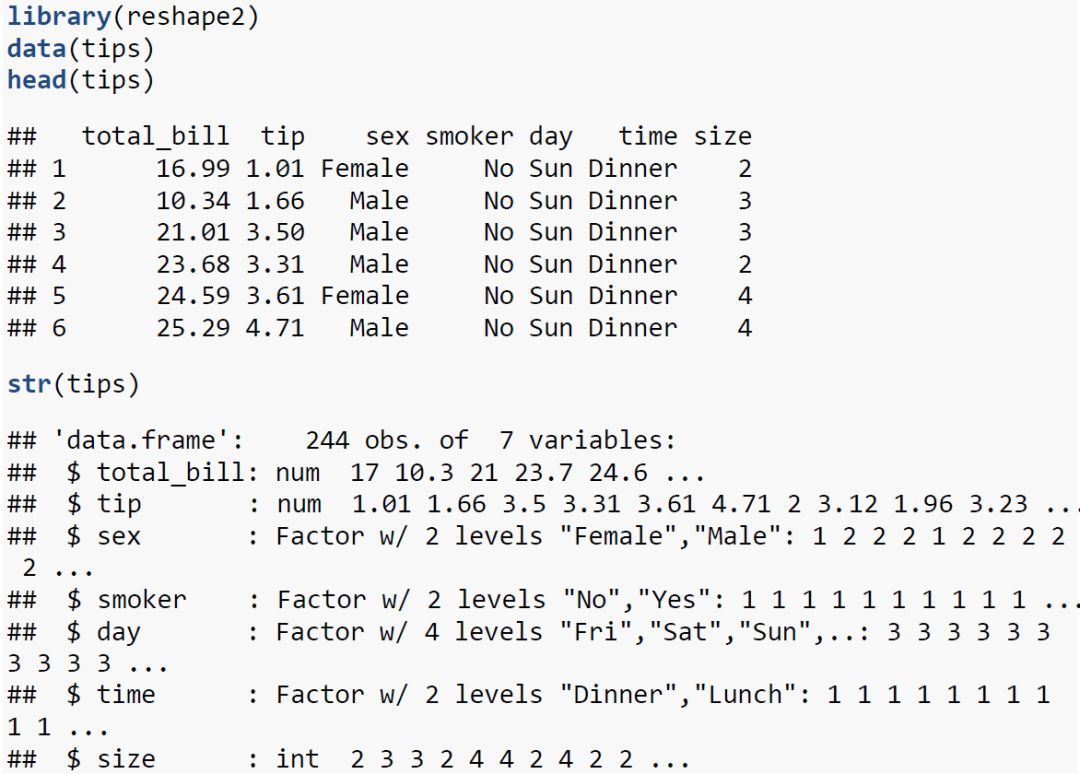
tips数据集包含244个观测,7个变量。其中3个数值型变量,4个因子型变量。
首先,我们根据其中某一个数值型变量对tips数据进行排序。
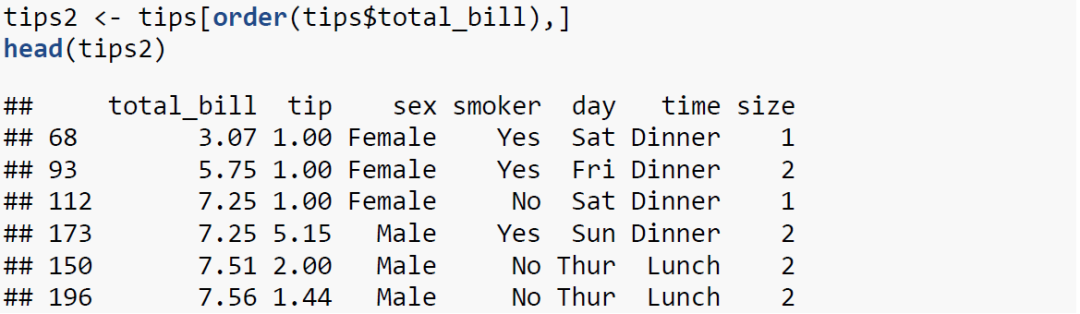
如你所见,tips数据框根据total_bill变量由小到大进行了排序,当然,order()函数中也有一个decreasing参数,默认是FALSE,如果需要由大到小进行排序,则改为TRUE即可。当然,如果不使用这个参数,也是可以的,比如:
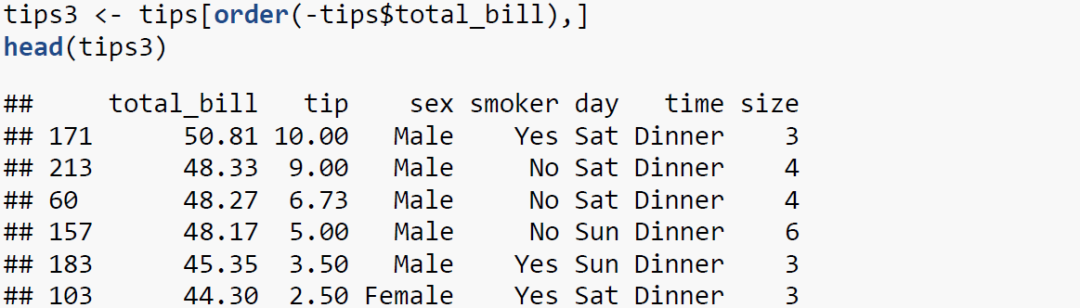
如你所见,我们根据total_bill从大到小对tips进行了排序。注意代码中的“-”。
上述代码均是根据一个变量进行排序,下面我们根据两个变量对数据框进行排序。
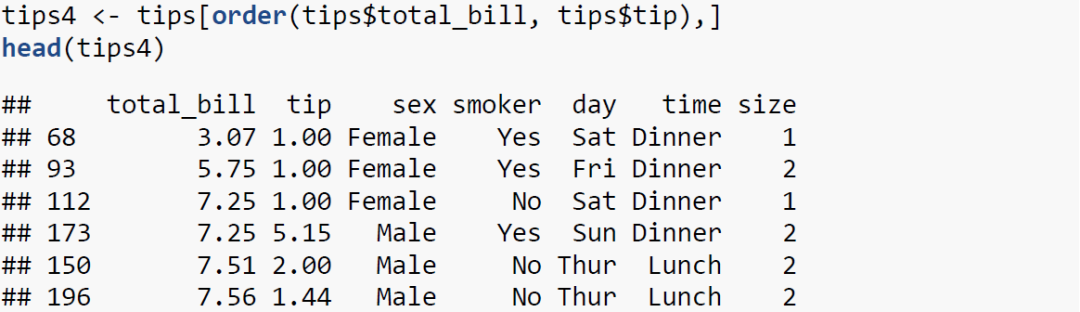
如你所见,我们根据total_bill与tip对tips进行了排序,两个变量均是由小到大排序。
除了对整个数据框进行排序,我们也可以根据一个变量对另外一个变量进行排序。

order()函数的功能是不是很强大呢,希望大家多多练习,这句话已经说了很多遍了。下期我将给大家介绍长宽型数据的转换,see you!
- 本文固定链接: https://maimengkong.com/kyjc/963.html
- 转载请注明: : 萌小白 2022年6月3日 于 卖萌控的博客 发表
- 百度已收录
