第五天 R语言对象的操作总结
R语言主要分析的对象是数据集,R语言数据集主要是向量、矩阵、数据框、列表、数组等,我们主要介绍前4种。前面2文已经进行了4种对象的介绍,现在本文将4种对象的程序方法进行进一步总结和凝练。
一、is和as系列函数
is 和as系列函数涉及不同类型数据和对象的鉴定和转换。我们经常在R语言编程过程中需要了解某一种数据的类型,也可能进行转换方便计算,所以诸位要熟悉他们。
is系列是判断某一个数据中的观察值是何种类型,或者数据属于何种对象与结构
• is.character(x) #判断是否为字符型
• is.numeric(x) #判断是否为数值型
• is.vector(x) #判断是否为一个向量
• is.matrix(x) #判断是否为一个矩阵
• is.array(x) #判断是否为一个数组
• is.data.frame(x) #判断是否为一个数据框
• is.factor(x) #判断是否为一个因子
as系列是对数据的类型、对象进行转换
• as.numeric() #转换为数值型
• as.logical() #转换为逻辑型
• as.charactor() #转换为字符串
• as.matrix() #转换为矩阵
• as.data.frame() #转换为数据框
• as.factor() #转换为因子
二、R语言四种主要对象的特点和关系
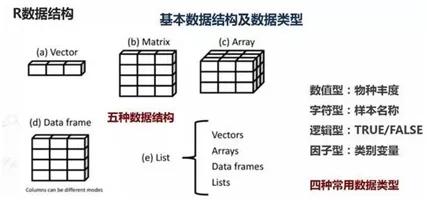
1. 向量(vector)
向量是一维数据集,往往具有一个向量名和一串数据,一个向量中,数据为同个类型

2. 矩阵(matrix)
矩阵是一个二位数据,往往具有一个矩阵名名和矩阵数据,一个矩阵中,,数据为同个类型

3. 数据框(data.frame)
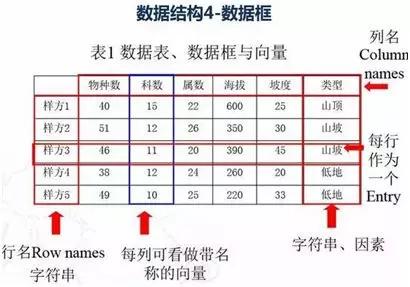
数据框是医学研究数据的主要方式,往往由多个向量同等长度的向量组成。每个向量称之为变量,具有向量名(变量名)和向量值(变量值),此外还有个数据库名。不同变量可以允许不同的数据类型。数据库的运算往往以一个向量(变量)为整体进行运算。

4. 列表(list)
列表是多个对象的组合(向量、矩阵、数据框、列表),结构较为复杂,一般在统计分析结果体现角度。
5. 向量可以通过matrix( )形成矩阵、多个向量可以通过data.frame ( )转为数据框;矩阵可以通过as.vector( ),转为向量,也可以通过data.frame( )或者as.data.frame( )转为数据框;list可以通过unlist( )转为向量。
三、子集的提取(数据索引)
子集提取将是今后数据整理、清洗核心的内容,请诸位务必掌握。子集的提取有具体位置的提取、根据逻辑值的提取、根据属性及值大小的提取、变量名的提取、反提取与删除、subset()函数提取、今后还会学习到dplyr包的提取等。
其中,向量和矩阵提取方法相似,只不过增加一个维度;数据库提取则增加变量$的提取。列表子集提取与数据框操作类似,但是用双重方括号。
1. 根据具体位置提取子集
向量的提取
x1<-c(2,3,5,7,9,10)
x1
x1[1] #返回x1的第1个元素
x1[-1] #返回除第一个元素之外的所有元素
x1[c(2:4)] #返回x1的第2至4个元素
x1[-c(2:4)] #返回x1的除第2至4元素之外的所有元素
矩阵的提取
m1<-matrix(x1, nrow=3,ncol=2) #采用matrix产生3行2列矩阵
m1
m1[i,j] #返回矩阵a的第i行,第j列的元素
m1[i,] #返回矩阵a的第i行
m1[,j] #返回矩阵a的第j列
m1[c(i:j),] #返回矩阵a的第i至第j行
m1[i,j] #返回矩阵a的第i行,第j列的元素
数据框的提取
d1<-data.frame(x1=c(5.1,4.9,8.7,2.6),x2=c(6, 3, 2, 3), x3=c(1.4,2.4,1.3,2.5))
d1
d1
d1[1,1]
d1[1,]
d1[,1]
2. 根据名称提取子集
向量的提取
>names(x1)<-c("two","three","five","seven","night","ten")
>x1[c("three","seven")]
>x1[-c("three","seven")]
矩阵的提取
m2<-matrix(x1,nrow=3,ncol=2,byrow=F,dimnames=list(c("r1","r2","r3"), c("c1","c2"))) # 产生具有行列名的矩阵
m2["r2","c1"] #返回矩阵c的第r2行,第c1列的元素2
数据框的提取
d1["x1"] # 产生名为x1的一列,也就是产生变量为x1的一列结果,结果为向量
d1["x2"] # 产生名为x1的一列,也就是产生变量为x1的一列结果,结果为向量
d1["x3"] # 产生名为x3的一列
数据框的$提取法
d1$x1 # 产生名为x1的一列,也就是产生变量为x1的一列结果,结果为向量
d1$x2 # 产生名为x1的一列,也就是产生变量为x1的一列结果,结果为向量
d1$x3 # 产生名为x3的一列
3. 根据属性及值大小的提取
向量的提取
x1[x1>3 & x1<8] # 产生大于3 又小于8的子集
矩阵提取
b[,r2=2] # 返回“r2”一行值为2的一列
b[c2=2, ] # 返回“c2”值为2的一行
数据框提取行
d1[d1$x1>4,] #提取大于x1>2的行
d1[d1$x1>4 | d1$ x2<4,] #提取大于x1>4或x2<4的行
d1[d1$x1>4 & d1$ x2<4,] #提取大于x1>4且x2<4的行
d1[d1$x2==6,] #提取大于x2等于6的行,R语言函数等号中用==,而不是=
4. 根据which()元素位置
向量的提取
通过函数which()返回逻辑向量中为TRUE的位置;
x1[which(x1>3 & x1<8)]
x1[which.max(x1)]
数据框的提取
> which(d1$x1>4) # which() 函数返回位置
[1] 1 2 3
d1[which(d1$x1>4),]
d1[which(d1$x2==6),]
5. 根据subset()生成子集
向量的提取
subset(x1, x1>3 & x1<8)
数据框的提取
subset(df, d1$x1>2)
6. 列表索引(子集提取)
与数据框操作类似,但是用双重方括号。
mylist<-list(
a=c(1,2,3,4),
b=c("one","two","three"),
c=c(TRUE,FALSE),
d=(1+2i))
mylist[[1]] #索引列表data的第1列
mylist[["g"]] #按名称索引,同mylist [[1]]
mylist $g #索引列表mylist的名称为d的列
mylist [[1]][1] #索引列表mylist的第1列的第1个元素
- 本文固定链接: https://maimengkong.com/kyjc/933.html
- 转载请注明: : 萌小白 2022年5月23日 于 卖萌控的博客 发表
- 百度已收录
