
先用几个问题检验一下你是否需要看这篇文章
-
dplyr包中如何批量筛选变量做汇总计算,知不知道有summarise_all at 这类函数
-
reshape2包中的融合重铸和分组计算有什么关联
-
tidyr 包的使用
-
Hadley 大神
本文介绍数据处理上的其他方面,和上一篇文章合在一起就可以组成处理数据的一个完整的系统。
本文目录如下
-
数据框合并
-
拼接合并
-
merge合并
-
计算并增加行列
-
汇总计算
-
分组计算
-
融合重铸
-
融合重铸的应用
-
拆分合并列
library(tidyr) # 提供一些其他功能
library(reshape2)
本文使用这三个包较多,如果对这几个包不再了解,建议先看一看
dplyr包5个主要函数(http://blog.163.com/zzz216@yeah/blog/static/16255468420147179438149/)
tidyr包中四个主要函数(http://www.cnblogs.com/homewch/p/5778405.html)
reshape2包中的融合-重铸两个函数(
数据框合并
拼接合并
列相同的两个数据框可以直接纵向接在一起,行相同的两个数据框也可以横向接在一起。
name1 <- c( "Bob", "Mary", "Jane", "Kim")
name2 <- c( "Bob", "Mary", "Kim", "Jane")
weight <- c( 60, 65, 45, 55)
height <- c( 170, 165, 140, 135)
birth <- c( "1990-1", "1980-2", "1995-5", "1996-4")
accept <- c( "no", "ok", "ok", "no")
df1 <- data.frame(name1,weight,height)
df2 <- data.frame(name2,birth,accept)
# 合并
rbind(df1,df2)
cbind(df1,df2)
# dplyr包中高效合并
bind_rows(df1,df2)
bind_cols(df1,df2)
merge合并
当两个数据框中有一列表示相同的含义,其他列不同时,可以按照这一列merge起来。
比如拿到两张表,分别对应两个数据框,一个记录了公司每个员工的体重,一个记录了公司每个员工的身高,他们有相同的姓名一列,我们就可以把两个数据框融合成为一个带有姓名、身高、体重的数据框。
有的人可能会问,为什么不直接横向拼在一起,再把相同的名字列去掉?是因为如果两个数据框的名字顺序不一样,或者名字不是完全相同,这样做就不行了。我们来看下面的例子
先创建数据框
name1 <- c( "Bob", "Mary", "Jane", "Kim", "Smith")
weight <- c( 60, 65, 45, 55, 60)
name2 <- c( "Bob", "Mary", "Kim", "Jane", "Eric")
height <- c( 170, 165, 140, 135, 170)
df11 <- data.frame(name1,weight,stringsAsFactors=F) # 加这个参数是防止字符串自动转化为因子
df33 <- data.frame(name1,height,stringsAsFactors=F)
df22 <- data.frame(name2,height,stringsAsFactors=F) # 成员与前面不完全一样
先使用基础的merge函数
merge(df11,df33) # 自动根据相同的列名匹配
merge(df11,df22,by.x="name1",by.y="name2") # 没有相同的列名则指定根据这两列融合
# 上面默认保留了df11和df22共有的行
merge(df11,df22,by.x="name1",by.y="name2",all=T) # 保留所有出现过的行,没有的显示NA
merge(df11,df22,by.x="name1",by.y="name2",all.x=T) # 保留所有x的行
merge(df11,df22,by.x="name1",by.y="name2",all.y=T) # 保留所有y的行
下面使用dplyr包
inner_join(df11,df33) # 自动根据相同的列名匹配
full_join(df11,df22, by=c( "name1"= "name2"))
left_join(df11,df22, by=c( "name1"= "name2")) # 只保留前者的行
right_join(df11,df22, by=c( "name1"= "name2")) # 只保留后者的行
semi_join(df11,df22, by=c( "name1"= "name2")) # 保留共有的行,同时只返回前者的列
anti_join(df11,df22, by=c( "name1"= "name2")) # 返回后者没有的前者的行,同时只返回前者的列
计算并增加行列
创建数据框
name1 <- c( "Bob", "Mary", "Jane", "Kim")
weight <- c( 60, 65, 45, 55)
height <- c( 170, 165, 140, 135)
df1 <- data.frame(name1,weight,height)
R基础函数
df2 <- transform(df1,BMI=weight/height^ 2) # 第一种方法
df2
df1 $BMI<- df1 $weight/df1 $height^ 2# 第二种方法, 每一步都要$,很麻烦
df1
使用dplyr包中的函数
mutate(df1,BMI=weight/height^2)
汇总计算apply(df1[,- 1], 2,mean) # R基础函数
dplyr包中的summarise系列函数
summarise(df1,arv_weight=mean(weight),arv_height=mean(height))
上面这种方式是一般人都会用的,但是如果没有看过dplyr包的文档,就不知道还有summarise_all等函数。当需要对每列都进行计算时,或者选择某一些列计算,只是summarise一个一个指定就会非常麻烦。下面我们介绍一些批量筛选计算的函数。
为了更好地说明问题,我们改一下数据框
name1 <- c( "Bob", "Mary", "Jane", "Kim")
weight <- c( 60, 65, 45, 55)
height <- c( 170, 165, 140, 135)
weta <- 1: 4
df1 <- data.frame(name1,weight,height,weta)
summarise_all 和 summarise_if
对所有列进行计算或者根据列的数据类型选择计算
summarise(df1,avg_weight=mean(weight),avg_height=mean(height)) # 很麻烦地每个都指定
summarise_all(df1[- 1],mean) # 对选出来的所有列都进行计算
summarise_ if(df1,is.numeric,mean) # 检验出所有是数值的列,全部求均值
summarise_at配合vars的用法
筛选出符合条件的列名对应的列
summarise_at( df1, vars( weight, height, weta), mean) # 配合 vars函数,一次选择多列
summarise_at( df1, vars( weight:weta),mean) # 从哪到哪
u <- c("weight","height")
summarise_at(df1,vars(one_of(u)),mean) # 可以接字符串向量
summarise_at(df1,u,mean) # 也可以直接接字符串向量
summarise_at(df1,u,mean,trim=1) # mean的参数可以接在后面
summarise_at(df1,vars(contains("eig")),mean) # 匹配含有的
summarise_at(df1,vars(matches(".t.")),mean) # 使用正则表达式
summarise_at(df1,vars(starts_with("w")),mean) # 匹配以此为开头的
summarise_at(df1,vars(ends_with("ht")),mean) # 匹配以此为结尾的
summarise_at(df1[,-1],vars(everything()),mean) # 选择所有列
funs的用法
summarise_all(df1[,- 1],funs(mean,sum))
summarise_all(df1[,- 1],funs(sum(.* 2))) # 数据用.表示
summarise_all(df1[,- 1],funs(medi=median)) # 指定得到的列后缀名
summarise_all(df1[,- 1],funs( "in"=median)) # 或者加引号
mutate_all(df1[,- 1],funs(.^ 2))
结合使用
summarise_if(df1,is.numeric,funs(mean,sum))
summarise_at(df1,vars(ends_with("t")),funs(mean,sum))
分组计算
首先创建我们需要的数据集
name1 <- c( "Bob", "Mary", "Jane", "Kim")
weight <- c( 60, 65, 45, 55)
height <- c( 170, 165, 140, 135)
accept <- c( "no", "ok", "ok", "no")
df <- data.frame(name1,weight,height,accept)
R基础函数
tapply(df $height,df $accept,mean) # 使用tapply函数,按照accept分类
with(df,{ # 使用aggregate函数
aggregate(height,by= list(accept),FUN=mean)
})
使用dplyr包中的函数
group_df <- group_by(df,accept)
summarise(group_df,arv_height=mean(height),count=n()) # 其中n()是查数的意思
# 使用扩展函数
summarise_all(group_df[,- 1],mean)
summarise_ if(group_df,is.numeric,mean)
summarise_at(group_df,vars(contains( "eigh")),funs(sum,mean))
dplyr包中的主要功能我们就讲到这里,除了以上功能,这个包还改写了很多基础函数,使其使用更方便,运行速度更快,感兴趣的读者可以查看帮助文档自行学习。
融合重铸
说到融合重铸,就不得不使用这张经典的图(来自《R语言实战》),这张图清晰的展现了融合重铸到底做了什么
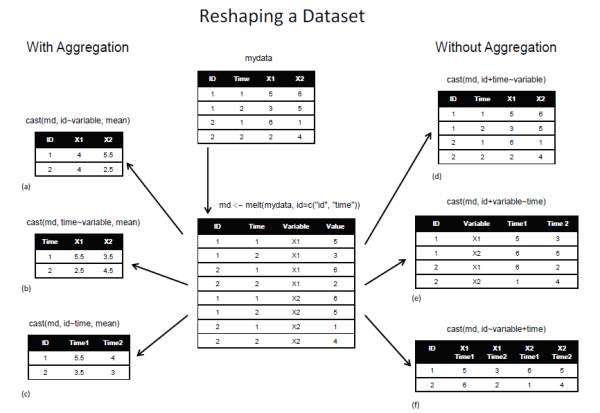
这里我们使用reshape2包和tidyr包分别完成融合重铸功能。
reshape2
上面这张图对应的代码就是reshape2包中的函数
names(airquality) <- tolower(names(airquality))
View(airquality)
aqm <- melt(airquality, id=c( "month", "day"), na .rm= TRUE) # 除了month和day两列,其他列摞起来,为了等长,m和d列循环对齐
dcast(aqm, day + variable ~ month) # 保持day和variable不变,month中的元素分类映射到列上去
dcast(aqm, variable + day ~ month) # 换一下顺序,重复的variable连在一起,对应不一样的day,这样的方式排列
dcast(aqm, day ~ variable + month) # 只保留day列
# 加入计算
dcast(aqm, day ~ month, mean) # 没出现的那个变量被平均掉了
# dcast 和 acast区别
dcast(aqm, variable + month ~ day)
acast(aqm, variable + month ~ day) # acast和dcast的功能基本上相同,只是dcast会把分组信息作为一列或几列显示,而acast会将其作为行名
acast(aqm, day ~ month, mean) # 保留的列作为合并在一起作为列名
acast(aqm, variable ~ month ~ day) # acast 多出来的功能,生成一个三维数组,按照day的值分成31个矩阵
tidyr包
有融合和重铸的函数,但是在重铸方面功能弱一些
aqg <- gather(airquality, group, value,ozone:temp) # 融合,和reshape2的不同在于输入的是被转换的列
spread(aqg, group, value) # 还原
spread(aqg,month, value) # 输入要被转化到列名的列和值,好像一次只能转化一列作为列名
融合重铸的应用
让我们把融合重铸计算实现的功能和分组计算做一下对比。
假设我们拿到的数据是下面这个样子的。按照月日,分不同组别汇总在一起的两列变量值
df <- mutate(aqm, newvalue = value+rnorm( 2, 0, 50))
colnames(df) <- c( "month", "day", "group", "value1", "value2")
View(df) # 我们可以看一看现在拿到的数据
我们首先实现如下功能
-
根据group分组计算两个value的均值
-
根据month和group分组计算两个value的均值
-
根据month和group分组计算每组个数
使用分组计算来实现
# 根据group分组计算两个value的均值
df_grp1 <- group_by(df, group)
summarise_at(df_grp1,vars(value1,value2),mean)
# 根据month和group分组计算两个value的均值
df_grp2 <- group_by(df,month, group)
summarise_at(df_grp2,vars(value1,value2),mean)
# 根据month和group分组计算每组个数
summarise(df_grp2,count=n())
使用融合重铸来实现
df_melt <- melt(df,id=c( "month", "day", "group"))
# 根据group分组计算两个value的均值
dcast(df_melt, group~ variable, mean)
# 根据month和group分组计算两个value的均值
dcast(df_melt, month + group~ variable, mean)
# 根据month和group分组计算每组个数
dcast(df_melt, month + group~ variable, length)
从上面来看,实现分组计算的功能二者没有太大区别,毕竟这就是分组计算本身在做的事情,不过当需要按照多种分组来计算时,融合重铸不需要重新设置组别,显然会更方便。
不过融合重铸也要注意一点,如果数据列数非常多,而且有的是字符串,或者有的列不是你需要计算的,要事先只提取出你需要的,再融合重铸。
下面我们说一说融合重铸擅长的部分
-
如果要不区分value1和value2,算整体按照month和group分组后的均值
-
上面计算结果值是一个矩阵,想要把数值用一列表示
-
按照月份拆分成多个矩阵,每一个矩阵表示group和日期的对应
(mg <- dcast(df_melt, month ~ group, mean)) # 上面计算结果值是一个矩阵,想要用一列表示
melt(mg, id= "month")
# 按照月份拆分成多个矩阵,每一个矩阵表示group和日期的对应
u <- acast(df_melt, group~ day ~ month) # 使用acast返回一个三维数组
拆分合并列
我们现在要把一列这种类型”1990-1”的数据拆分成两列”1990”和”1”这样的数据,使用tidyr包中的separate函数
library(tidyr)
name1 <- c( "Bob", "Mary", "Jane", "Kim")
birth <- c( "1990-1", "1980-2", "1995-5", "1996-4")
df <- data.frame(name1, birth)
(df1 <- separate(df,birth, into=c( "year", "month"),sep= "-"))
separate_rows(df,birth,sep= "-") # 拆分完放在一列里面显示
# 其实separate_rows相当于使用separate之后进行了融合,再更换一下顺序
separate(df,birth, into=c( "year", "month"),sep= "-") %>% gather( group,birth,year:month)
tidyr包中很多函数都是成对出现的,unite 函数是和separate函数反向的函数,可以将它得到的结果还原
unite(df1,birth,year,month,sep="-")
到这里,我们就把数据处理的整体框架讲述了一遍,主要针对数据的计算与变形,覆盖了dplyr tidyr reshape2包的使用方法。本专题下一篇,我们会使用data.table包来重新完成这整个框架
Dwzb , R语言中文社区专栏作者,厦门大学统计专业学生。
知乎专栏:Data Analysis
https://zhuanlan.zhihu.com/Data-AnalysisR
- 本文固定链接: https://maimengkong.com/kyjc/1020.html
- 转载请注明: : 萌小白 2022年6月23日 于 卖萌控的博客 发表
- 百度已收录
