因子在R语言中可以用来表示名义型变量或有序变量。名义变量一般表示类别,如性别,种族等等。有序变量是有一定排序顺序的变量,如职称,年级等等。在R语言中,名义变量和有序变量可以使用因子来表示。
创建因子
在R语言中可以使用factor()函数和gl()函数来创建因子变量。
(1)使用factor()函数
factor()函数的语法格式为:
f <- factor(x=charactor(), levels, labels=levels, exclude = NA, ordered = is.ordered(x), namax = NA)
其中:
x 为创建因子的数据,是一个向量;
levels:因子数据的水平,默认是x中不重复的值;
labels:标识某水平的名称,与水平一一对应,以方便识别,默认取levels的值;
exclude:从x中剔除的水平值,默认为NA值;
ordered:逻辑值,因子水平是否有顺序(编码次序),若有取TRUE,否则取FALSE;
nmax:水平个数的限制。
下面给出几个具体的例子来说明具体使用方法:
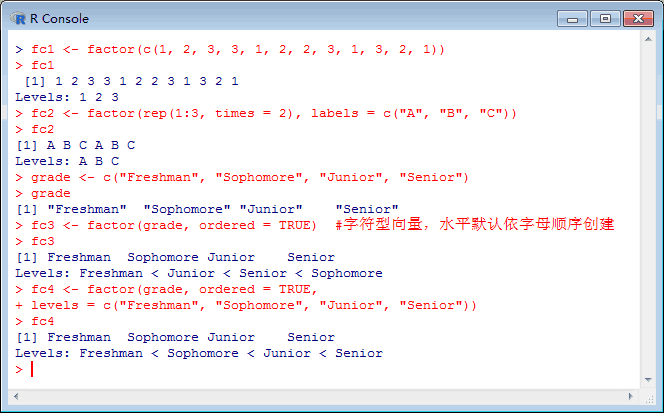
fc1 <- factor(c(1, 2, 3, 3, 1, 2, 2, 3, 1, 3, 2, 1))
fc2 <- factor(rep(1:3, times = 2), labels = c("A", "B", "C"))
grade <- c("Freshman", "Sophomore", "Junior", "Senior")
fc3 <- factor(grade, ordered = TRUE) #对于字符型向量,因子的水平默认依字母顺序创建
fc4 <- factor(grade, ordered = TRUE, levels = c("Freshman", "Sophomore", "Junior", "Senior")) #指定levels,则按levels中的顺序定义数值
本部分执行情况如下图所示:
(2)使用gl()函数
gl()函数用于定义有规律的因子向量,其语法格式如下:
gl(n, k, length = n*k, labels = 1:n, ordered = FALSE)
其中参数的含义如下:
n: 正整数,表示因子的水平个数
k:正整数,表示每个水平重复的次数;
length: 正整数,表示因子向量的长度,默认为n*k
labels: 表示因子水平的名称,默认值为1:n
ordered: 逻辑变量,表示因子水平是否是有次序的,默认值为FALSE
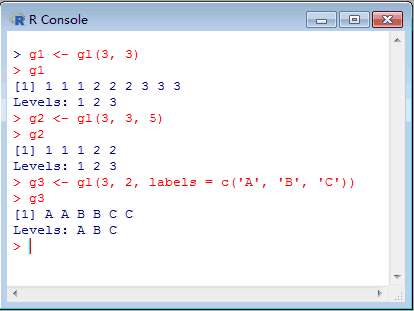
g1 <- gl(3, 3) # 1 1 1 2 2 2 3 3 3
g2 <- gl(3, 3, 5) # 1 1 1 2 2
g3 <- gl(3, 2, labels = c('A', 'B', 'C')) # A A B B C C
本部分的结果情形如下图所示:
因子的索引
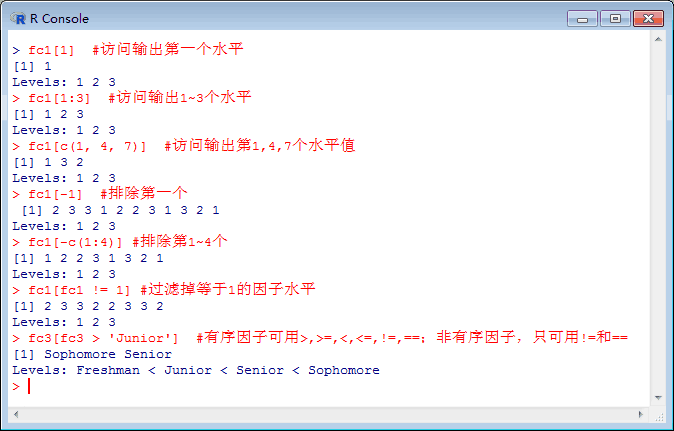
fc1[1] #访问输出第一个水平
fc1[1:3] #访问输出1~3个水平
fc1[c(1, 4, 7)] #访问输出第1,4,7个水平值
fc1[-1] #排除第一个
fc1[-c(1:4)] #排除第1~4个
fc1[fc1 != 1] #过滤掉等于1的因子水平
fc3[fc3 > 'Junior'] #对于有序因子可以使用>,>=,<,<=,!=,==;而非有序因子,只可以使用!=和==
注意:因为因子一般表示名义变量或有序变量,如非有序因子,则使用>,>=,<,<=比较大小是没有意义的。
本部分执行情况如下图所示:
因子的修改
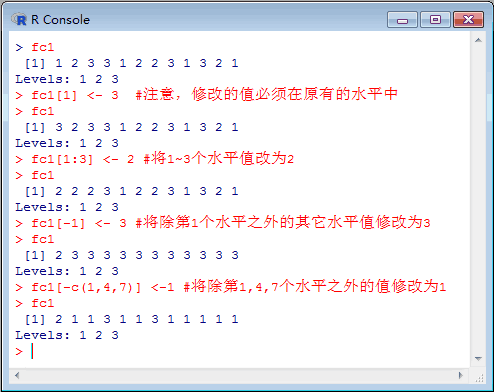
fc1[1] <- 3 #注意,修改的值必须在原有的水平中
fc1[1:3] <- 2 #将1~3个水平值改为2
fc1[-1] <- 3 #将除第1个水平之外的其它水平值修改为3
fc1[-c(1,4,7)] <-1 #将除第1,4,7个水平之外的值修改为1
执行情况如下:
-------------------
- 本文固定链接: https://maimengkong.com/kyjc/1001.html
- 转载请注明: : 萌小白 2022年6月20日 于 卖萌控的博客 发表
- 百度已收录
