3W 解析 Golang 语言 Context:用法、源码
作者:thom,腾讯PCG后台开发工程师
Context 是什么?
按照官方定义在 go 语言里面 context 包定义了一个 context 类型的接口,携带了截止时间,取消信号,超时时间,以及携带上下文的系统参数(k-v)的类型。是 Go 语言 1.7版本引入的。
为什么要有 context?
有人说 go1.7 版本之前没有 context,那为什么 go1.7 版本要引入 Context? 看 chatGPT 如何回答:
其实在 Go 1.7 之前,也有一种叫做 "context" 的机制,只不过它是私有的,只能在 Go 标准库内部使用。而在 Go 1.7 中,标准库将 context 机制公开了出来,使得开发者可以在自己的代码中使用它。 引入 context 的主要原因是为了解决在并发编程中的一些问题,比如在一个请求处理过程中,可能会启动多个 goroutine 来处理不同的任务,这些任务可能需要共享一些上下文信息,比如请求的截止时间、请求的 ID 等等。如果没有一个统一的机制来管理这些上下文信息,那么代码就会变得非常混乱,难以维护。 通过引入 context,开发者可以将这些上下文信息封装在一个 context 对象中,并将其传递给各个 goroutine,从而实现了上下文信息的统一管理。这样一来,代码就变得更加清晰、易于理解和维护了。
我总结一下: 使用 context 管理上下文 能够使代码更加简洁和清晰,并且也避免了一些线程安全的风险。
context 是怎么做的? 没有 context 这些问题是怎么做的?
没有 context,多个 goroutine 之间要保持相同的超时时间和相同的变量使用的是全局变量的方式。
package mainimport ( "fmt" "time")// 全局变量,用于存储上下文信息var ( deadline time.Time requestID string)func main { // 设置上下文信息 deadline = time.Now.Add(5 * time.Second) requestID = "123456" // 启动一个 goroutine 来处理任务 go func { for { select { case <-time.After(1 * time.Second): // 模拟一些耗时的操作 fmt.Println("goroutine 1: doing some work") default: // 检查上下文信息,如果已经超时或被取消了,就退出循环 if time.Now.After(deadline) { fmt.Println("goroutine 1: context canceled") return } } } } // 启动另一个 goroutine 来处理任务 go func { for { select { case <-time.After(1 * time.Second): // 模拟一些耗时的操作 fmt.Println("goroutine 2: doing some work") default: // 检查上下文信息,如果已经超时或被取消了,就退出循环 if time.Now.After(deadline) { fmt.Println("goroutine 2: context canceled") return } } } } // 等待一段时间,然后取消上下文信息 time.Sleep(3 * time.Second) fmt.Println("main: context canceled") deadline = time.Now time.Sleep(1 * time.Second)}
有了 context 之后,代码如下。
package mainimport ( "context" "fmt" "time")func main { // 创建一个带有截止时间的 context ctx, cancel := context.WithDeadline(context.Background, time.Now.Add(5*time.Second)) defer cancel // 启动一个 goroutine 来处理任务 go func(ctx context.Context) { for { select { case <-ctx.Done: // 如果 context 被取消了,就退出循环 fmt.Println("goroutine 1: context canceled") return default: // 模拟一些耗时的操作,普通情况可能是rpc调用 time.Sleep(1 * time.Second) fmt.Println("goroutine 1: doing some work") } } }(ctx) // 启动另一个 goroutine 来处理任务 go func(ctx context.Context) { for { select { case <-ctx.Done: // 如果 context 被取消了,就退出循环 fmt.Println("goroutine 2: context canceled") return default: // 模拟一些耗时的操作 time.Sleep(1 * time.Second) fmt.Println("goroutine 2: doing some work") } } }(ctx) // 等待一段时间,然后取消 context time.Sleep(3 * time.Second) cancel fmt.Println("main: context canceled") time.Sleep(1 * time.Second)}
总结:通过下面代码实现实现携带超时时间的终止。同时代码更加简洁清晰容易维护。
ctx, cancel := context.WithDeadline(context.Background, time.Now.Add(5*time.Second)) ... ctx.Done
可以替换每一个地方的截止时间,同时这个 ctx 是只读的,不会有修改。同时如果有其他的变更是带锁的操作,contetext接口是提供的只读的方法。
time.Now.After(deadline)
因此我觉得是一个能力的替换,使用 context 保存 deadline 全局变量,只提供只读操作,并且通过封装起来,里面的锁机制保证线程安全。
Context 是怎么做到的包含 goroutinue 的上下文?
试想一下如果让你来设计多个协程控制超时时间,你会怎么设计和怎么走? 也是一个全局变量一直玩下传递? 前面提到了全局变量的方法,但是在可维护性,线程安全等等都有一些问题。 协程之间同时控制统一完成。 正常的go服务里面,通常要控制多个协程进行操作,这个时候就需要一个context来进行管理,并且官方也推荐ctx context.Context放在第一个入参。
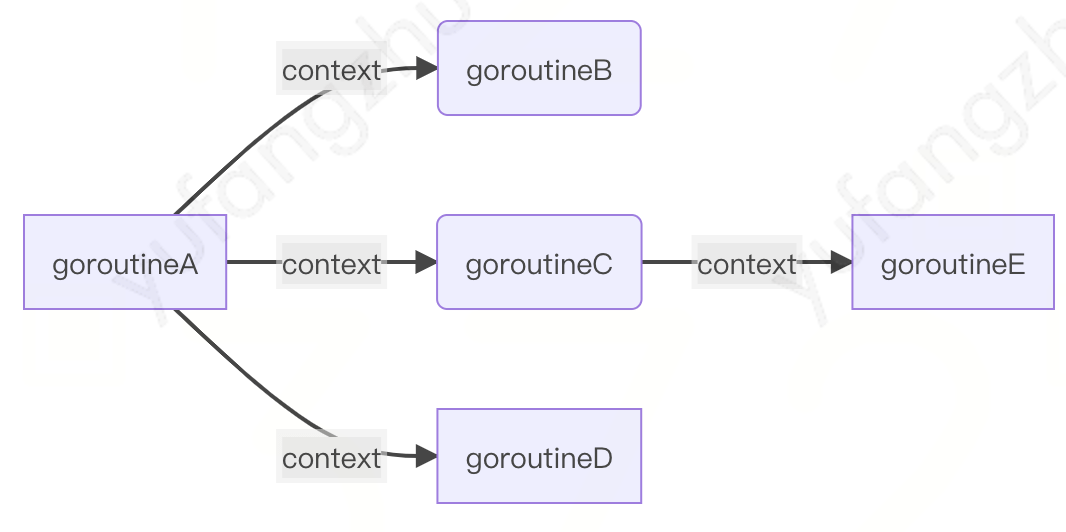
那就要跟我们读一下 context 的源码,深入探索这些原理了。 首先 Context 如何将超时时间一层一层传递给上面? 如下代码所示:对于 Context 在包内是一个接口,定义了 4 个方法,并且都是幂等的。
// Conetext 包介绍 : 通常context携带截止时间,**和取消信号**,以及其他跨越API边界的值,Context的方法可以被多个协程同时调用。package contexttype Context interface { // 返回截止的日期,如果无截止日期,ok返回false Deadline (deadline time.Time, ok bool)// 返回一个channel,当工作已完成或者上下文被取消时关闭。如果是一个不会被取消的上下文,Done会返回nil// WithCancel方法,会在被调用cancel时,关闭Done// WithDeadline方法,会在过截止时间时,关闭Done// WithTimeout方法,会在超时结束时,关闭Done Done <-chan struct{}// Done没有被关闭时,会返回nil// 如果Done关闭了,将会返回关闭的原因(取消、超时)Err error// 返回与当前上下文关联的键值或nil。如果没有值与键关联,使用相同键连续调用 Value 会返回相同的结果Value(key interface{}) interface{}}
因为当前自己的版本是 go1.20 版本,本次所讲到的源码就是 go 1.20.
Context 的超时时间控制
我们使用 context 使用的最多也是约定俗成的就是通过 ctx 控制协程之间的超时时间了,那么我们看下源码是怎么实现的?
我们由于前面的例子中可以看到超时时间是通过 ctx.Done 来判断是否有通道信号过来,如果有的话,那么就返回信号通知
func (c *cancelCtx) Done <-chan struct{} { // 原子变量加载看是否存通道信息 d := c.done.Load if d != nil { return d.(chan struct{}) } c.mu.Lock defer c.mu.Unlock d = c.done.Load if d == nil { d = make(chan struct{}) c.done.Store(d) } return d.(chan struct{})}
c.done 是“懒汉式”创建,只有调用了 Done方法才被创建,因此可以看到是一个只读的 channel,并且没有地方向 channel 里面写数据。因此调用读这个 channel,协程会被 block 住。通常搭配 select 来使用。一旦关闭,就会立刻读出零值。 那我们推测出来,肯定是在 WithCancel 来进行关闭或者 WithDeadLine超过了定时 timer 进行关闭的。并且要递归关闭掉所有的父节点和子节点。 我们通过 debug 跳到源码里面去跟踪一下源码: 首先是 context.WithDeadline
func WithDeadline(parent Context, d time.Time) (Context, CancelFunc) { if parent == nil { panic("cannot create context from nil parent") } if cur, ok := parent.Deadline; ok && cur.Before(d) { // The current deadline is already sooner than the new one. return WithCancel(parent) } c := &timerCtx{ cancelCtx: newCancelCtx(parent), deadline: d, } propagateCancel(parent, c) dur := time.Until(d) if dur <= 0 { c.cancel(true, DeadlineExceeded, nil) // deadline has already passed return c, func { c.cancel(false, Canceled, nil) } } c.mu.Lock defer c.mu.Unlock if c.err == nil { c.timer = time.AfterFunc(dur, func { c.cancel(true, DeadlineExceeded, nil) }) } return c, func { c.cancel(true, Canceled, nil) }}
根据上面可以知道,所有 close(channel)都在 c.cancel 里面。 我们看下 cancel的实现?
func (c *timerCtx) cancel(removeFromParent bool, err, cause error) { c.cancelCtx.cancel(false, err, cause) if removeFromParent { // Remove this timerCtx from its parent cancelCtx's children. removeChild(c.cancelCtx.Context, c) } c.mu.Lock if c.timer != nil { c.timer.Stop c.timer = nil } c.mu.Unlock}
总结下上面代码: cancel的实现的方法功能是关闭 channel:c.done;递归地取消他所有的子节点,从父节点删除自己。能达到的效果就是关闭 channel.将取消信号传递给所有子节点。 综上我们可以看出来,是如何通过 context 控制整个链路上的超时时间和控制所有节点同一个时间推出和关闭通道。 我们利用了通道特性和封装和递归做到了简单的控制了 rpc 之间的调用关系。
通过 ctx 传递系统参数共享数据
源码:
func WithValue(parent Context, key, val any) Context { if parent == nil { panic("cannot create context from nil parent") } if key == nil { panic("nil key") } if !reflectlite.TypeOf(key).Comparable { panic("key is not comparable") } return &valueCtx{parent, key, val}}
例子:
package mainimport ( "context" "fmt")type Config struct { LogLevel string Timeout int}// 模拟获取系统配置信息的函数func getConfig(ctx context.Context) Config { // 从 ctx 中获取配置信息 config, ok := ctx.Value("config").(Config) if !ok { return Config{LogLevel: "debug", Timeout: 100} } return config}func main { // 初始化一个 context ctx := context.Background // 设置系统配置信息到 context 中 config := Config{LogLevel: "info", Timeout: 200} ctx = context.WithValue(ctx, "config", config) // 测试获取配置信息 c := getConfig(ctx) fmt.Println("LogLevel:", c.LogLevel) fmt.Println("Timeout:", c.Timeout)}
其中获取数据的源码:
func (c *valueCtx) Value(key any) any { if c.key == key { return c.val } return value(c.Context, key)}func value(c Context, key any) any { for { switch ctx := c.(type) { case *valueCtx: if key == ctx.key { return ctx.val } c = ctx.Context case *cancelCtx: if key == &cancelCtxKey { return c } c = ctx.Context case *timerCtx: if key == &cancelCtxKey { return ctx.cancelCtx } c = ctx.Context case *emptyCtx: return nil default: return c.Value(key) } }}
上面我们可以看到可以通过 k-v 的形式将数据放入 context 里面,无论哪一级的 ctx 都可以获取到数据,通常我们会把 traceID 放入 ctx 里面,串联整个日志内容,或者一些系统变量。 我觉得虽然他传递共享全局变量非常方便,但是他存在也存在一些缺点,就是全局变量的通病。不知道在哪里修改的,另外我们看到 context.WithValue,每一个加一层,类似链表,通常都是圈复杂度是 0(n)如果没有控制很好,效率不高。 比如下面:
ctx = context.WithValue(ctx, "config", config) ctx = context.WithValue(ctx, "test", "1") ctx = context.WithValue(ctx, "test2", "3") // 测试获取配置信息 c := getConfig(ctx)
可以看到如果赋值3次,那么可能需要递归3次,才能去得到变量。因此复杂度是0(n)
Context 缺点
通过上面的例子我们也可以看到 Context 通过 context 的包以及封装让我们写服务代码更加简单和精炼,那么真的 Context 有什么缺点呢? 其实前面源码以及分析已经有提到了。
- 从源码的角度来看 WithValue WithDeadline 等方法存在链表嵌套复杂度比较高
- 如果滥用代码比较难以为维护
- 如果不理解 context,代码不是很好理解(这也是其中的一个小优点,大家约定context做的事情)
- 传递的数据只能是基本的数据类型或者引用。!reflectlite.TypeOf(key).Comparable如果不是可比较的 key 就 panic 了。
- 如果 context 传递比较耗时,要保证及时清理 context 传递的信息。
- 本文固定链接: https://maimengkong.com/moreshare/1747.html
- 转载请注明: : 萌小白 2024年5月31日 于 卖萌控的博客 发表
- 百度已收录
