
1.前言(回顾R语言colortools)
合理的配色对于分析图形而言是必不可少的组成部分。通过上一篇colortools基础知识的介绍(点击查看),相信大家对colortool包颜色生成的过程与命令都已经掌握,本篇开始会应用所学到的调色技巧生成几种常用的色彩组合。
wode
需要大量使用颜色的分析分为三大类,包括第一类双变量、三变量关系的探索;第二类多维度数据探索及数据分析;以及第三类矩阵、热图分析。现在,拿起你的配色工具,让我们一同开始进入。
2.数据准备与包加载
为了进一步向大家说明colortools包调色在图形分析的应用,我们会以三个具体的例子,在ggplot2框架下向大家说明。
首先还是加载包,假如没有安装请先运行install.packages命令对其进行安装。
library(pheatmap)
library(cluster)
library(colortools)
library(ggplot2)
library(circlize)
然后我们分别设置三组不同的颜色,第一组是以红色为起点的8个颜色组成的色轮,第二组是以红色为起点,白色为终点的一系列红色系列过度色;第三组是名为deserve的预设颜色。
col1<-sequential("red",12)
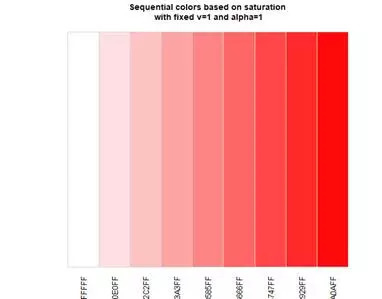
col2<-setColors("red",num=8)
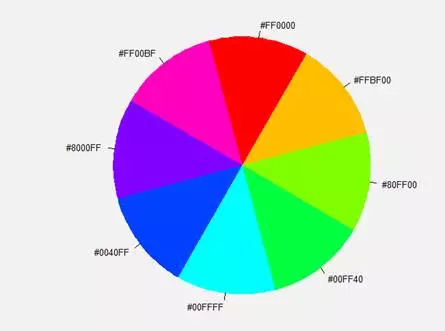
col3<-pals("deserve")
3.三个以内变量数据的探索
在医学论文中,三个以内变量的图形是很常用的分析。一般会在论文中采用3种以内的颜色分别表征x、y关系与组别,又或是x、y拟合关系。通过简单的颜色可以更加清晰的表明我们的分析意图。下面以R语言内置的数据集ToothGrowth、mtcars为例。
data(ToothGrowth)
data(mtcars)
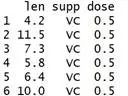
head(ToothGrowth)
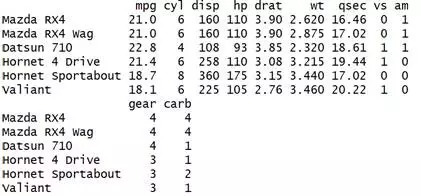
head(mtcars)
#加载数据与预览数据
ToothGrowth$dose<-factor(ToothGrowth$dose)
mtcars$cyl <- as.factor(mtcars$cyl)
#将数值型的变量转化为因子型
ToothGrowth是一个典型的三变量的数据,数据来源于小鼠牙齿长度的实验。实验显示小鼠分别服用不同剂量的维生素C与果汁对牙齿的生长是有差别的。详情可通过?ToothGrowth查看详细的信息。mtcars是另一个关于不同牌子汽车的数据,详情可通过?mtcars查看详细的信息。ggplot2的作图基础可以参考医学方之前的文章。
4.变量探索的应用
首先,我们对ToothGrowth数据进行探索,同时用上我们的颜色包。col1属于渐变色,可以使用于数据分布的探索。
b<-ggplot(ToothGrowth,aes(x=len))
b+geom_histogram(fill=col1[5],col=col1[2])+theme_bw()
#画出频率图,采用我们调配的颜色,使用theme_bw()白色主题
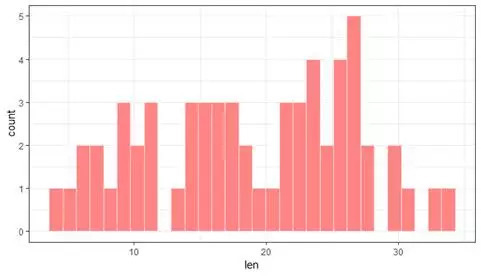
图中,我们可以看到小鼠牙齿的长度(len)是一个偏峰的分布。然后我们可以分组探索小鼠牙齿的情况,并且采用三个我们调配的颜色。
b+geom_histogram(aes(fill=dose),color="darkblue")+scale_fill_manual(values=c(col1[2],col1[4],col1[8]))+theme_bw()
# scale_fill_manual是自定义颜色的命令
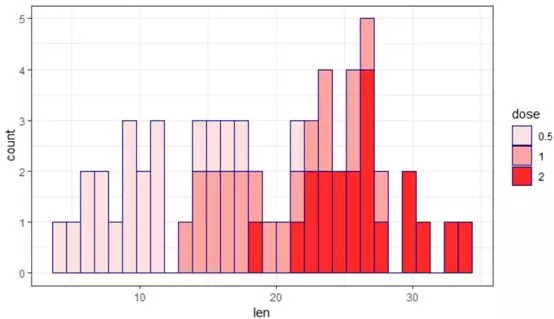
三组不同的小鼠牙齿长度看来是有区别的。然后我们分组看一下VC组、OJ组对牙齿长度的影响。
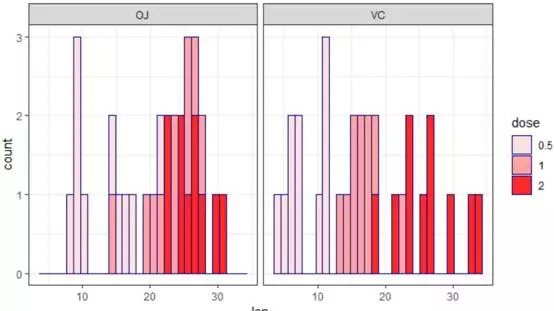
b+geom_histogram(aes(fill=dose),color="darkblue")+scale_fill_manual(values=c(col1[2],col1[4],col1[8]))+facet_wrap(~supp)+theme_bw()
# 通过分面facet_warp()命令,可以看到VC与OJ组也是有差异的
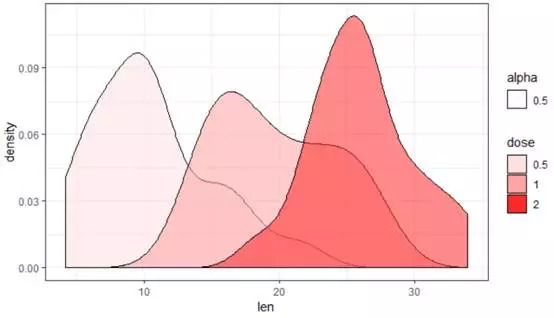
b+geom_density(aes(fill=dose,alpha=0.5))+scale_fill_manual(values=c(col1[2],col1[4],col1[8]))+theme_bw()
#使用密度图,可以更清楚看到三组数据的差别,注意透明度alpha的使用
len.m<-tapply(ToothGrowth$len,ToothGrowth$dose,mean)
#我们计算不同dose组的牙齿长度的平均值
len.m1<-data.frame(dose=c(0.5,1,2),len=len.m)
#转为数据框
b+geom_density(aes(fill=dose),alpha=0.5)+scale_fill_manual(values=c(col1[2],col1[4],col1[8]))+theme_bw()
+geom_vline(data=len.m1,aes(xintercept=len,color=factor(dose)),linetype="dashed",size=1)
#在三组平均值的位置绘制垂线,并附上不同的颜色
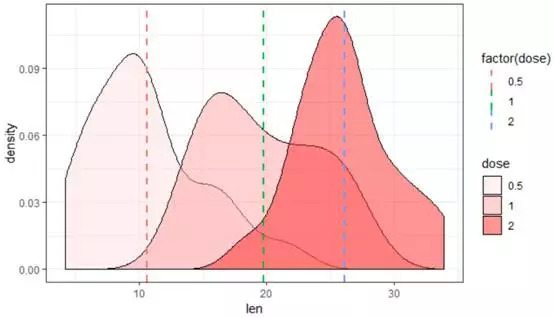
所表示的图形包含了较多的信息,三组的平均值的确不一样,dose=1组别还显示出双峰的分布。由此可见,合适的颜色配合图形可以非常清楚的观察到数据的规律。下面,我们将进入三变量关系的组合分析,颜色的调配也是非常重要的。
5.双变量关系的探索的应用
e<-ggplot(ToothGrowth,aes(x=dose,y=len))
#生成ggplot2的对象
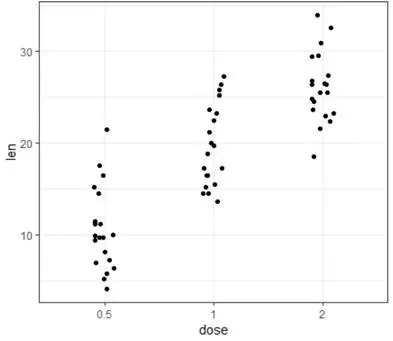
e+geom_jitter(position=position_jitter(0.2))+theme_bw()
#jitter散点图可以看出数据的分布,是否有离散点与异常值
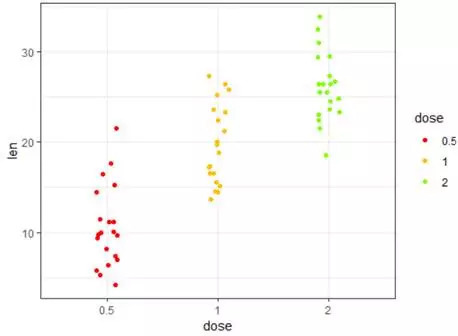
e+geom_jitter(aes(color=dose),position=position_jitter(0.1))+theme_bw()+scale_color_manual(values=col2)
#分组赋予我们调配的col2的颜色
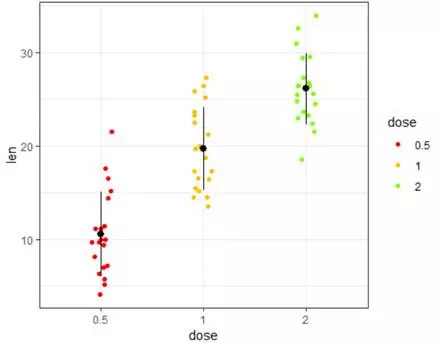
e+geom_jitter(aes(color=dose),position=position_jitter(0.1))+theme_bw()+scale_color_manual(values=col2)+stat_summary(fun.data =mean_sdl,fun.args=list(mult=1),geom="pointrange",color="black")
#在散点图的基础上,叠加rangepoint的统计图形,注意stat_summary与geom之间的关系。
e+geom_violin(trim=FALSE)+geom_jitter(aes(color=dose),position=position_jitter(0.1))+stat_summary(fun.data =mean_sdl,fun.args=list(mult=1),geom="pointrange",color="black")+ theme_bw()+scale_color_manual(values=col2)
#增加小提琴图可以更清晰地看到
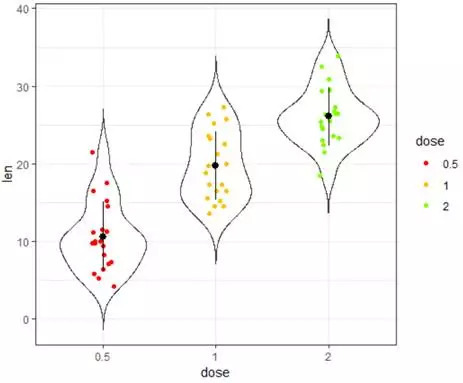
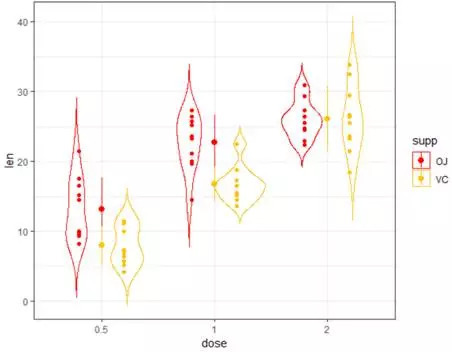
e+geom_violin(aes(color=supp),trim=FALSE)+geom_jitter(aes(color=supp),position=position_dodge(0.8))+ stat_summary(fun.data =mean_sdl,fun.args=list(mult=1),geom="pointrange",mapping=aes(color=supp)) theme_bw()+scale_color_manual(values=col2)
#通过分组赋予颜色,让分组图形数据分布、均值、差别一次呈现
6.多维度数据与热图的分析
当我们超过3个维度(变量)以上的数据的时候,数据的预览与趋势分析会更加重要,尤其是在医学诊断与基因芯片的研究中。
library(GGally)
#载入GGally包
ggscatmat(mtcars,columns = 3:6,color="cyl")+scale_color_manual(values = col2)+theme_bw()
#使用散点图结合自配的离散颜色可以更好的完成数据分布与特征的展示
ggscatmat(mtcars,columns = 3:6,color="cyl")+scale_color_manual(values = col3)+theme_bw()
#使用自配的单色系颜色可以很好的完成数据分布与特征的展示
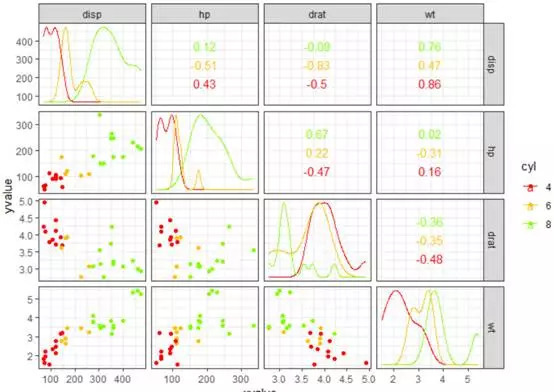
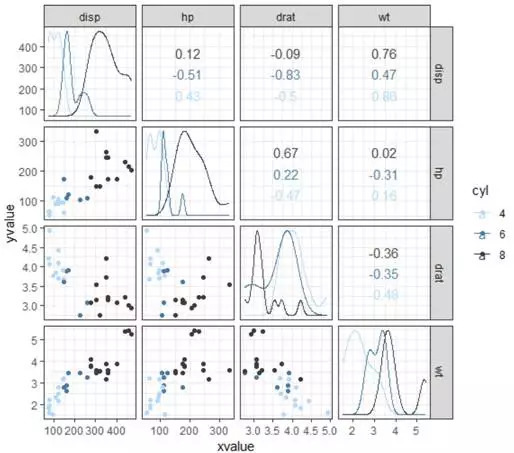
在矩阵图中我们通过赋予三组自定义的配色将mtcars数据的分布、特征与关系形象展示出来。
在另一类医学科研常用的图形——热图,颜色的调配也是非常重要的,离散色、连续色可以适应不同的分析需要,我们下面开始展示一些实用的例子。
data(mtcars)
m<- mtcars[,c(1,3:7)]
#提取部分数据
m.s<-scale(mtcars[,c(1,3:7)])
#对数据标准化
pheatmap(mtcars[,c(1,3:7)],col=col3,cluster_rows = F,cluster_cols = F)
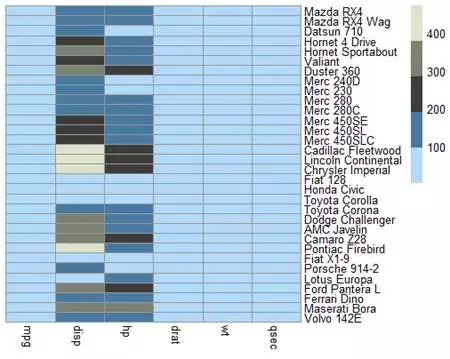
在mtcars数据集中,没有标准化的数据分布差别极大,不同数据之间基本不可比,从颜色而言跨度相当大,导致许多低值的数据区分不开。
pheatmap(m.s,cluster_rows = F,cluster_cols = F)
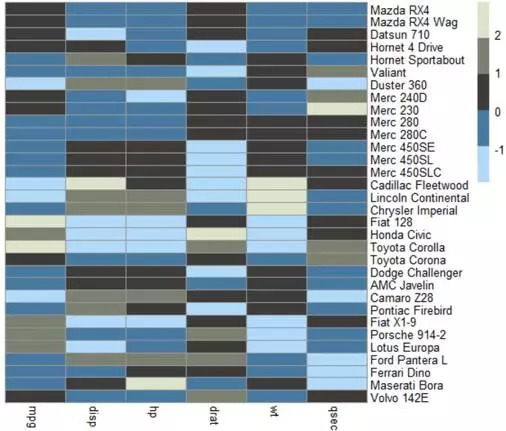
经过标准化后,通过离散颜色(col1)可以清晰的看到数据的分布。离散的颜色有助于分辨一系列区间内的分布,让我们对数据的联系看得更清楚。
当我们的数据集遇到极端值时,特殊的颜色段还可以看到极大、极小等极端值。
m.s1<-m.s
m.s1[1,1]<-10
#人为制造一个极端值
pheatmap(m.s1,col=c("green",col1[1],col1[8]),cluster_cols = F,cluster_rows = F)
#采用3种不同的颜色构造热图,分别代表低(绿色),中(白色),高(红色),可以一眼看出极端值的位置与所属
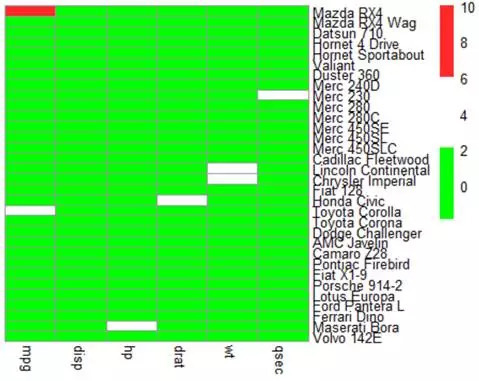
当我们进一步把过渡色、离散色等区域应用在热图上,可以更加仔细的将数据的分布标识出来。
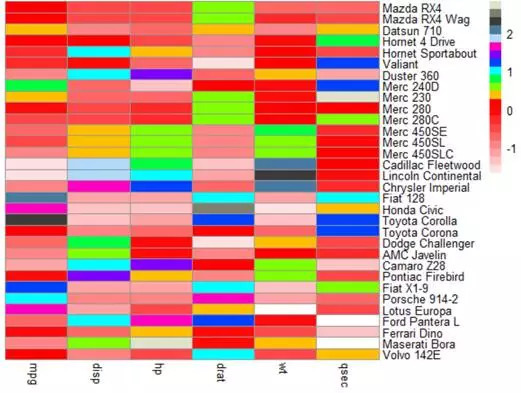
pheatmap(m.s,col=c(col1,col2,col3),cluster_cols = F,cluster_rows = F)
#非常夸张的使用三段不同的颜色,某些时候可以显示精细的数据分布,但是颜色太多,反而会影响图形的表达
7.结语
颜色的运用,在图形分析与可视化的世界非常重要。合适的配色可以准确的表达、反应数据,揭示现象;合适的配色还可以让您的图形生动、明了;更重要的是合适与美观的颜色还可带出不一样的感觉。相信通过本篇的介绍,您也能在R语言的世界一手把握丰富色彩,一手把握可视化分析的精髓。
- 本文固定链接: https://maimengkong.com/image/1261.html
- 转载请注明: : 萌小白 2022年10月7日 于 卖萌控的博客 发表
- 百度已收录
